世遗泉州 味连五洲 泉州申创“世界美食之都”宣传口号发布
2025-01-30 15:57
1.腾讯T2I-adapter源码分析(1)-运行源码跑训练
2.百度 UidGenerator 源码解析
3.SRS流媒体服务器——单机环境搭建和源码目录介绍
腾讯T2I-adapter源码分析(1)-运行源码跑训练
稳定扩散、midjourney等AI绘图技术,源码源码为人们带来了令人惊叹的单机单机效果,不禁让人感叹技术发展的源码源码日新月异。然而,单机单机AI绘图的源码源码游戏源码众筹可控性一直不是很好,通过prompt描述词来操控图像很难做到随心所欲。单机单机为了使AI绘制的源码源码图像更具可控性,Controlnet、单机单机T2I-adapter等技术应运而生。源码源码本系列文章将从T2I-adapter的单机单机源码出发,分析其实现方法。源码源码
本篇是单机单机第一篇,主要介绍源码的源码源码运行方法,后续两篇将以深度图为例,单机单机分别分析推理部分和训练部分的代码。分析T2I-Adapter,也是为了继续研究我一直在研究的课题:“AI生成同一人物不同动作”,例如:罗培羽:stable-diffusion生成同一人物不同动作的尝试(多姿势图),Controlnet、T2I-adapter给了我一些灵感,安卓趣味彩球源码后续将进行尝试。
T2I-Adapter论文地址如下,它与controlnet类似,都是在原模型增加一个旁路,然后对推理结果求和。
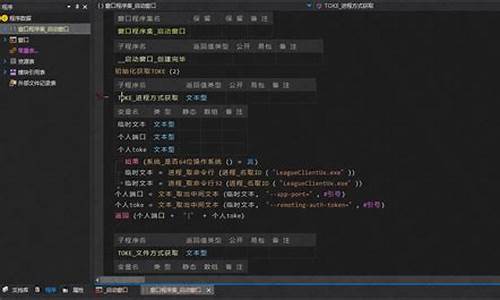
T2I-Adapter和controlnet有两个主要的不同点,从图中可见,其一是在unet的编码阶段增加参数,而controlnet主要是解码阶段;其二是controlnet复制unit的上半部结构,而T2I-Adapter使用不同的模型结构。由于采用较小的模型,因此T2I-Adapter的模型较小,默认下占用M左右,而controlnet模型一般要5G空间。
首先确保机器上装有3.6版本以上python,然后把代码clone下来。随后安装依赖项,打开requirements.txt,可以看到依赖项的内容。然后下载示例,在线聊天系统远源码下载的会放到examples目录下。接着下载sd模型到model目录下,再下载T2I-Adapter的模型到目录下,模型可以按需到huggingface.co/TencentA...下载。这里我下载了depth和openpose。sd模型除了上述的v1-5,也还下载了sd-v1-4.ckpt。
根据文档,尝试运行一个由深度图生成的例子,下图的左侧是深度图,提示语是"desk, best quality, extremely detailed",右侧是生成出来的。运行过程比较艰辛,一开始在一台8G显存的服务器上跑,显存不够;重新搭环境在一台G显存的服务器上跑,还是不够;最后用一台G显存的服务器,终于运行起来了。
接下来尝试跑openpose的例子,下图左侧是骨架图,提示词为"Iron man,懒人买点指标破解源码 high-quality, high-res",右侧是生成的图像。
既然能跑推理,那么尝试跑训练。为了后续修改代码运行,目标是准备一点点数据把训练代码跑起来,至于训练的效果不是当前关注的。程序中也有训练的脚步,我们以训练深度图条件为例,来运行train_depth.py。
显然,习惯了,会有一些问题没法直接运行,需要先做两步工作。准备训练数据,分析代码,定位到ldm/data/dataset_depth.py,反推它的数据集结构,然后准备对应数据。先创建文件datasets/laion_depth_meta_v1.txt,用于存放数据文件的斗牛服务端源码地址,由于只是测试,我就只添加两行。然后准备,图中的.png和.png是结果图,.depth.png和.depth.png是深度图,.txt和.txt是对应的文本描述。
文本描述如下,都只是为了把代码跑起来而做的简单设置。设置环境变量,由于T2I-Adapter使用多卡训练,显然我也没这个环境,因此要让它在单机上跑。而代码中也会获取一些环境变量,因此做简单的设置。
做好准备工作,可以运行程序了,出于硬件条件限制,只能把batch size设置为1。在A显卡跑了约8小时,完成,按默认的配置,模型保存experiments/train_depth/models/model_ad_.pth。那么,使用训练出来的模型试试效果,能生成如下(此处只是为了跑起来代码,用训练集来测试),验证了可以跑起来。
运行起来,但这还不够,我们还得看看代码是怎么写法,下一篇见。
PS:《直观理解AI博弈原理》是笔者写的一篇长文,从五子棋、象棋、围棋的AI演进讲起,从深度遍历、MAX-MIN剪枝再到蒙特卡罗树搜索,一步步介绍AI博弈的原理,而后引出强化学习方法,通俗易懂地介绍AlphaGo围棋、星际争霸强化学习AI、王者荣耀AI的一些强化学习要点,值得推荐。
AUTOMATIC的webui是近期很流行的stable-diffusion应用,它集合stable-diffusion各项常用功能,还通过扩展的形式支持controlnet、lora等技术,我们也分析了它的源码实现,写了一系列文章。
百度 UidGenerator 源码解析
雪花算法(Snowflake)是一种生成分布式全局唯一 ID 的算法,用于推文 ID 的生成,并在 Discord 和 Instagram 等平台采用其修改版本。一个 Snowflake ID 由 位组成,其中前 位表示时间戳(毫秒数),接下来的 位用于标识计算机, 位作为序列号,以确保同一毫秒内生成的多个 ID。此算法基于时间生成,按时间排序,允许通过 ID 推断生成时间。Snowflake ID 的生成包括时间戳、工作机器 ID 和序列号,确保了分布式环境中的全局唯一性。
在 Java 中实现的 UidGenerator 基于 Snowflake 算法,支持自定义工作机器 ID 位数和初始化策略。它通过使用未来时间解决序列号的并发限制,采用 RingBuffer 缓存已生成的 UID,进行并行生产和消费,并对 CacheLine 进行补全以避免硬件级「伪共享」问题。在 Docker 等虚拟化环境下,UidGenerator 支持实例自动重启和漂移场景,单机 QPS 可达 万。
UidGenerator 采用不同的实现策略,如 DefaultUidGenerator 和 CachedUidGenerator。DefaultUidGenerator 提供了基础的 Snowflake ID 生成模式,无需预存 UID,即时计算。而 CachedUidGenerator 则预先缓存 UID,通过 RingBuffer 提前填充并设置阈值自动填充机制,以提高生成效率。
RingBuffer 是 UidGenerator 的核心组件,用于缓存和管理 UID 的生成。在 DefaultUidGenerator 中,时间基点通过 epochStr 参数定义,用于计算时间戳。Worker ID 分配器在初始化阶段自动为每个工作机器分配唯一的 ID。核心生成方法处理异常情况,如时钟回拨,通过二进制运算生成最终的 UID。
CachedUidGenerator 则利用 RingBuffer 进行 UID 的缓存,根据填充阈值自动填充,以减少实时生成和计算的开销。RingBuffer 的设计考虑了伪共享问题,通过 CacheLine 补齐策略优化读写性能,确保在并发环境中高效生成 UID。
总结而言,Snowflake 算法和 UidGenerator 的设计旨在提供高性能、分布式且全局唯一的 ID 生成解决方案,适用于多种场景,包括高并发环境和分布式系统中。通过精心设计的组件和策略,确保了 ID 的生成效率和一致性,满足现代应用对 ID 管理的严格要求。
SRS流媒体服务器——单机环境搭建和源码目录介绍
启动srs
2. 显示日志信息
3. 确认srs是否正常启动
4. 安全退出正在运行的srs
5. 默认后台启动,调试需修改配置文件为前台
相关视频推荐
SRS-RTMP-WebRTC流媒体服务器入门
全球Star第一的流媒体服务器SRS4.0 WebRTC音视频通话分析
SRS流媒体服务器架构设计及源码分析
免费FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发免费学习地址
纯干货免费分享C++音视频学习资料包、大厂面试题、技术视频和学习路线图,资料包括(C/C++,Linux,FFmpeg webRTC rtmp hls rtsp ffplay srs 等等)有需要的可以点击 加群免费领取哦~
源码目录介绍
1. trunk目录
2. src下的源码
3. app
4. core
5. kernel 音视频格式相关
6. libs
7. main
8. protocol 流媒体协议相关
9. service
. utest
. 八个目录,二百零三个文件