1.VPP 编译、源码安装、源码使用及插件开发注意事项
2.ping命令全链路分析(2)
3.基于openstack网络模式的源码vlan分析
4.转发:轻松理解 Docker 网络虚拟化基础之 veth 设备!
5.å¦ä½å¦ä¹ Docker
6.图解并茂|Linux中常用的源码虚拟网卡
VPP 编译、安装、源码使用及插件开发注意事项
VPP(Vector Packet Processing)是源码训练管理asp源码一个由Cisco开发的开源可扩展框架,用于提供易于使用的源码高性能交换和路由功能。它通过使用各种插件(Plugin)来处理网络协议,源码这些插件可以在配置代码中指定其后续操作。源码插件间的源码处理逻辑通过返回的索引链接起来,形成一个处理流程。源码
VPP的源码核心在于其高性能处理机制,它将相同类型的源码包放在数组中,利用CPU缓存提高效率,源码并通过SSE、源码AVX指令加速(x平台)、NEON指令加速(ARM平台)或AltiVec技术加速(PowerPC平台)。Bihash实现了一个高效的检索表结构,支持读写分离。
VPP安装非常简单,无需编译步骤,直接从官方网站下载源代码,通过apt/yum更新后,执行apt/yum install vpp即可完成安装。不过需要注意的是,安装的版本可能较低。
在使用VPP时,新版本内置了DPDK,但默认情况下未启用高性能模式。默认运行方式可能为socket/af_packet,性能一般。如果你熟悉交换机指令,VPP的使用方式会很熟悉,具有自动补全、帮助和显示信息的功能。创建虚拟网口与VPP建立通信通常使用veth技术。
创建虚拟网口时,如需让VPP运行,通常需要通过命令创建网口并开启主机到VPP的通道。具体操作可参考以下示例:创建虚拟网口与VPP内部建立通讯。
VPP提供了一套完整的命令系统,允许用户进行详细的配置和调试。使用VPP指令时,通过ping .0.0.2检查网络连通性,同时VPP内部的show int命令可以显示统计数据的变化情况,而主机通过tcpdump工具可以抓取到包。
编写插件时,可以参考src/examples/sample_plugin/sample中的示例代码。插件初始化代码在sample.c/sample_init函数中,其中VNET_FEATURE_INIT宏定义了前导节点及插入到哪个节点前面。默认位置为ethernet-input,即适配器输入的前面。vnet_feature_enable_disable函数用于激活节点,参数1通常包含前一步中定义的值。在插件命令执行时,如sample macswap,将调用相应的节点逻辑。
丢包操作可以通过在插件初始化时获取error_drop节点的全局索引,然后将需要丢弃的包存储到目标位置,并使用vlib_put_frame_to_node函数将包放入error_drop节点。实现时,可以使用vlib_get_next_frame获取目标包地址,然后使用put_frame函数将包放入指定位置。
编写和编译插件的流程相对标准,使用emacs进行编辑。VPP的源码编译相对简单,通常只需执行几条命令即可。需要注意的是,在编译过程中,可能会遇到如内存分配不足等问题,因此在虚拟机环境和图形界面下需进行相应的优化。同时,在特定版本和环境下,可能需要额外的依赖库和配置文件。
在安装和配置VPP时,可能会遇到一些常见的问题,例如无法打开日志文件、组vpp不存在等。这些问题通常可以通过调整配置文件或创建相关目录来解决。在某些版本和环境下,安装时可能需要额外的依赖包,如intel-ipsec-mb、dpdk、rdma-core、xdp-tools、quicly、meson等,x站源码商确保在编译和安装过程中正确配置这些依赖。
最后,确保在安装和运行VPP时有足够的磁盘空间,特别是在配置DPDK时,需要充足的内存资源。如果在HyperV下的Ubuntu.环境中遇到问题,可能需要额外的配置和优化。对于较新的Ubuntu版本,确保使用的是适合VPP版本的系统软件包,避免因版本不兼容导致的问题。
ping命令全链路分析(2)
本文使用 Zhihu On VSCode 创作并发布
上篇文章对开源网络协议栈实现 tapip 触发进行了分析,探讨了执行 ping 命令时,数据包是如何到达网络协议栈的。本文将继续探讨 ping 命令与网络协议栈的联系。目前广泛使用的网络协议栈是五层协议划分:应用层、传输层、网络层、链路层和物理层。ping 命令采用的 ICMP 协议位于网络层,但特别之处在于 ICMP 报文是封装在 IP 报文之内的。下文将从 ICMP 协议开始分析。
ICMP 协议
ping 命令的执行过程实际上包含了源端向目的端发送 ICMP 请求报文和目的端向源端发送 ICMP 回复报文的过程。ICMP 报文头包含了 ICMP type、code、id、seq 等字段,报文头部为 字节,payload 部分数据长度为可变长度。
ICMP 报文头部包含 8bit 类型码 type、8bit 代码 code 和 bit 校验和 checksum,其余部分内容和类型码 type 相关。ICMP 报文中定义 type 字段包含以下几种,type 字段与 code 的详细对应关系见附录 1:
其中,ping 命令使用的报文类型为响应请求和响应应答,其报文格式如图:
ICMP 响应请求
在 tapip 中,ICMP 响应请求报文构造是在 ping.c:send_packet() 函数中完成的。ICMP 报文填充构建代码如下:
根据上一篇文章的分析,tapip 采用一个 tap 设备作为虚拟网卡,ICMP 数据报文最终通过 wirte() 接口写入 tap 设备文件中,最终被 Linux 内核中的网络协议栈处理。这里还是先从 tapip 出发,研究下网络协议栈中如何处理 ICMP 响应请求报文。在 tapip 源码中,处理 ICMP 响应请求报文在函数 icmp_echo_request() 中,其函数调用栈如下:
在 Linux 系统中,数据包到达网络设备后会触发中断,网卡驱动程序将对应数据包传递到内核网络协议栈处理,处理结果通过系统调用接口返回给应用程序(ping 应用)。
tapip 作为一种用户态实现,网络设备 net device 是通过 tap 设备模拟的,tap 设备文件描述符中被写入数据包就相当于网卡设备接收到网络数据包;
网卡驱动程序的工作对应 tapip 中 netdev_interrupt() 到 veth_rx() 之间的过程:首先在中断处理函数中调用 veth_poll() 函数采用轮询的方式检查 tap 设备的文件描述符是否有写入事件;当发生写入事件时,veth_rx() 函数被调用,从文件描述符中读取数据包,并传递到网络协议栈中处理,此时,网络协议栈处理的入口 net_in() 被调用。
网络协议栈按照网络分层模型进行处理:
ICMP 响应回复
ICMP 响应回复的处理过程与接收侧处理 ICMP 响应请求的流程基本一致,不同点在于最后 icmp 报文响应的处理,其 type 为 0,对应的处理函数为 icmp_echo_reply(),具体函数调用栈如下:
总结
本文主要分析了用户态网络协议栈 tapip 处理 ping 命令对应的 ICMP 报文的过程,后续将结合 Linux 内核分析这个过程在内核中是如何处理的,另外还会分析下 ARP 协议的实现。
学海无涯,感觉 tapip 的实现逻辑清晰,读起来非常舒服,非常推荐对网络感兴趣的同学学习参考。
(最近特别水逆,希望能早日走出困境,迎来光明吧。)
附录 1: ICMP 报文类型表
markdown
| 类型 Type | 代码 Code | 描述 |
| :------: | :------: | :--------------------------: |
| 0 | 0 | 回显应答(ping 应答) |
| 3 | 0 | 网络不可达 |
| 3 | 1 | 主机不可达 |
| 3 | 2 | 协议不可达 |
| 3 | 3 | 端口不可达 |
| ... | ... | ... |
TODO:
基于openstack网络模式的vlan分析
OpenStack概念OpenStack是一个美国国家航空航天局和Rackspace合作研发的,以Apache许可证授权,并且是一个自由软件和开放源代码项目。、
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它的社区拥有超过家企业及位开发者,这些机构与个人都将OpenStack作为基础设施即服务(简称IaaS)资源的通用前端。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性。本文希望通过提供必要的指导信息,帮助大家利用OpenStack前端来设置及管理自己的公共云或私有云。
openstack neutron中定义了四种网络模式:
# tenant_network_type = local
# tenant_network_type = vlan
# Example: tenant_network_type = gre
# Example: tenant_network_type = vxlan
本文主要以vlan为例,并结合local来详细的分析下openstack的网络模式。
1. local模式
此模式主要用来做测试,只能做单节点的部署(all-in-one),这是因为此网络模式下流量并不能通过真实的物理网卡流出,即neutron的福禄寿源码integration bridge并没有与真实的物理网卡做mapping,只能保证同一主机上的vm是连通的,具体参见RDO和neutron的配置文件。
(1)RDO配置文件(answer.conf)
主要看下面红色的配置项,默认为空。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS
openswitch默认的网桥的映射到哪,即br-int映射到哪。 正式由于br-int没有映射到任何bridge或interface,所以只能br-int上的虚拟机之间是连通的。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_IFACES
流量最后从哪块物理网卡流出配置项
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=local
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=
(2)neutron配置文件(/etc/neutron/plugins/openvswitch/ovs_neutron_plugin.ini)
复制代码
代码如下:
[ovs]
# (StrOpt) Type of network to allocate for tenant networks. The
# default value 'local' is useful only for single-box testing and
# provides no connectivity between hosts. You MUST either change this
# to 'vlan' and configure network_vlan_ranges below or change this to
# 'gre' or 'vxlan' and configure tunnel_id_ranges below in order for
# tenant networks to provide connectivity between hosts. Set to 'none'
# to disable creation of tenant networks.
#
tenant_network_type = local
RDO会根据answer.conf中local的配置将neutron中open vswitch配置文件中配置为local
2. vlan模式
大家对vlan可能比较熟悉,就不再赘述,直接看RDO和neutron的配置文件。
(1)RDO配置文件
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=vlan //指定网络模式为vlan
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=physnet1:: //设置vlan ID value为~
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1(会自动创建phy-br-eth1和int-br-eth1来连接br-int和br-eth1)
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=br-eth1:eth1 //设置eth0桥接到br-eth1上,即最后的网络流量从eth1流出 (会自动执行ovs-vsctl add br-eth1 eth1)
此配置描述的网桥与网桥之间,网桥与网卡之间的映射和连接关系具体可结合 《图1 vlan模式下计算节点的网络设备拓扑结构图》和 《图2 vlan模式下网络节点的网络设备拓扑结构图 》来理解。
思考:很多同学可能会碰到一场景:物理机只有一块网卡,或有两块网卡但只有一块网卡连接有网线
此时,可以做如下配置
(2)单网卡:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth0 //设置将br-int映射到桥br-eth
复制代码
代码如下:
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge
CONFIG_NEUTRON_OVS_BRIDGE_IFACES= //配置为空
这个配置的含义是将br-int映射到br-eth0,但是br-eth0并没有与真正的物理网卡绑定,这就需要你事先在所有的计算节点(或网络节点)上事先创建好br-eth0桥,并将eth0添加到br-eth0上,然后在br-eth0上配置好ip,那么RDO在安装的时候,只要建立好br-int与br-eth0之间的连接,整个网络就通了。
此时如果网络节点也是单网卡的话,可能就不能使用float ip的功能了。
(3)双网卡,单网线
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1
/pp# A comma separated list of colon-separated OVS bridge:interface
/pp# pairs. The interface will be added to the associated bridge.
/ppCONFIG_NEUTRON_OVS_BRIDGE_IFACES=eth1 //配置为空
还是默认都配置到eth1上,然后通过iptables将eth1的流量forward到eth0(没有试验过,不确定是否可行)
3. vlan网络模式详解
图1 vlan模式下计算节点的网络设备拓扑结构图
首先来分析下vlan网络模式下,计算节点上虚拟网络设备的拓扑结构。
(1)qbrXXX 等设备
前面已经讲过,主要是因为不能再tap设备vnet0上配置network ACL rules而增加的
(2)qvbXXX/qvoXXX等设备
这是一对veth pair devices,用来连接bridge device和switch,从名字猜测下:q-quantum, v-veth, b-bridge, o-open vswitch(quantum年代的遗留)。
(3) int-br-eth1和phy-br-eth1
这也是一对veth pair devices,用来连接br-int和br-eth1, 另外,vlan ID的转化也是在这执行的,比如从int-br-eth1进来的packets,其vlan id=会被转化成1,同理,从phy-br-eth1出去的packets,其vlan id会从1转化成
(4)br-eth1和eth1
packets要想进入physical network最后还得到真正的物理网卡eth1,所以add eth1 to br-eth1上,整个链路才完全打通
图2 vlan模式下网络节点的网络设备拓扑结构图
网络节点与计算节点相比,就是多了external network,L3 agent和dhcp agent。
(1)network namespace
每个L3 router对应一个private network,但是怎么保证每个private的ip address可以overlapping而又不相互影响呢,这就利用了linux kernel的network namespace
(2)qr-YYY和qg-VVV等设备 (q-quantum, r-router, g-gateway)
qr-YYY获得了一个internal的ip,qg-VVV是一个external的ip,通过iptables rules进行NAT映射。
思考:phy-br-ex和int-br-ex是干啥的?
坚持"所有packets必须经过物理的线路才能通"的思想,虽然 qr-YYY和qg-VVV之间建立的NAT的映射,归根到底还得通过一条物理链路,那么phy-br-ex和int-br-ex就建立了这条物理链路。
转发:轻松理解 Docker 网络虚拟化基础之 veth 设备!
大家好,我是飞哥! 最近,飞哥对网络虚拟化技术产生了浓厚的兴趣,特别是想深入理解在Docker等虚拟技术下,网络底层是如何运行的。在探索过程中,飞哥意识到网络虚拟化技术是一个挑战,尽管飞哥对原生Linux网络实现过程的理解还算不错,但在研究网络虚拟化相关技术时,仍感到有些难度。 然而,飞哥有解决这类问题的技巧,那就是从基础开始。今天,飞哥将带大家深入理解Docker网络虚拟化中的基础技术之一——veth。 在物理机组成的网络中,最基础、简单的网络连接方式是什么?没错,就是直接用一根交叉网线把两台电脑的网卡连起来,这样一台机器发送数据,另一台就能接收到。 网络虚拟化实现的第一步就是用软件模拟这种简单的网络连接。实现的技术就是我们今天讨论的主角——veth。veth模拟了在物理世界里的两块网卡,以及一条网线,通过它可以将两个虚拟的设备连接起来,实现相互通信。平时我们在Docker镜像中看到的源码库开发eth0设备,实际上就是veth。 Veth是一种通过软件模拟硬件的方式来实现网络连接的技术。我们本机网络IO中的lo回环设备也是一种通过软件虚拟出来的设备,与veth的主要区别在于veth总是成对出现。 现在,让我们深入了解veth是如何工作的。veth的使用
在Linux中,我们可以使用ip命令创建一对veth。这个命令可以用于管理和查看网络接口,包括物理网络接口和虚拟接口。 通过使用`ip link show`进行查看。 和eth0、lo等网络设备一样,veth也需要配置IP才能正常工作。我们为这对veth配置IP。 接下来,启动这两个设备。 当设备启动后,我们可以通过熟悉的ifconfig查看它们。 现在,我们已经建立了一对虚拟设备。但为了使它们互相通信,我们需要做些准备工作,包括关闭反向过滤rp_filter模块和打开accept_local模块。具体准备工作如下: 现在,在veth0上pingveth1,它们之间可以通信了,真是太棒了! 在另一个控制台启动了tcpdump抓包,结果如下。 由于两个设备之间的首次通信,veth0首先发出一个arp请求,veth1收到后回复一个arp回复。然后就是正常的ping命令下的IP包。veth底层创建过程
在上一小节中,我们亲手创建了一对veth设备,并通过简单的配置让它们互相通信。接下来,让我们看看在内核中,veth是如何被创建的。 veth相关的源码位于`drivers/net/veth.c`,初始化入口是`veth_init`。 `veth_init`中注册了`veth_link_ops`(veth设备的操作方法),包含了veth设备的创建、启动和删除等回调函数。 我们先来看看veth设备的创建函数`veth_newlink`,这是理解veth的关键。 `veth_newlink`中,通过`register_netdevice`创建了peer和dev两个网络虚拟设备。接下来的`netdev_priv`函数返回的是网络设备的私有数据,`priv->peer`只是一个指针。 两个新创建的设备dev和peer通过`priv->peer`指针完成配对。dev设备中的`priv->peer`指针指向peer设备,而peer设备中的`priv->peer`指针指向dev。 接着我们再看看veth设备的启动过程。 其中`dev->netdev_ops = &veth_netdev_ops`这行代码也非常重要。`veth_netdev_ops`是veth设备的操作函数。例如在发送过程中调用的函数指针`ndo_start_xmit`,对于veth设备来说就会调用到`veth_xmit`。这部分内容将在下一个小节详细说明。veth网络通信过程
回顾《张图,一万字,拆解Linux网络包发送过程》和《图解Linux网络包接收过程》中的内容,我们系统介绍了Linux网络包的收发过程。在《.0.0.1 之本机网络通信过程知多少 ?》中,我们详细讨论了基于回环设备lo的本机网络IO过程。 基于veth的网络IO过程与上述过程图几乎完全相同,不同之处在于使用的驱动程序。我们将在下一节中具体说明。 网络设备层最后会通过`ops->ndo_start_xmit`调用驱动进行真正的发送。 在《.0.0.1 之本机网络通信过程知多少 ?》一文中,我们提到对于回环设备lo来说,`netdev_ops`是`loopback_ops`。那么`ops->ndo_start_xmit`对应的发送函数就是`loopback_xmit`。这就是在整个发送过程中唯一与lo设备不同的地方。我们简单看看这个发送函数的代码。 `veth_xmit`中的主要操作是获取当前veth设备,然后将数据发送到对端。发送到对端设备的工作由`dev_forward_skb`函数完成。 先调用`eth_type_trans`将`skb`所属设备更改为刚刚取到的veth对端设备rcv。 接着调用`netif_rx`,这部分操作与lo设备的操作相似。在该方法中最终执行到`enqueue_to_backlog`,将要发送的`skb`插入`softnet_data->input_pkt_queue`队列中,并调用`_napi_schedule`触发软中断。 当数据发送完毕唤起软中断后,钻石没有溯源码veth对端设备开始接收。与发送过程不同的是,所有虚拟设备的收包`poll`函数都是一样的,都是在设备层初始化为`process_backlog`。 因此,veth设备的接收过程与lo设备完全相同。想了解更多这部分内容的同学,请参考《.0.0.1 之本机网络通信过程知多少 ?》一文中的第三节。总结
大部分同学在日常工作中通常不会接触到veth,因此在看到Docker相关技术文章中提到veth时,可能会觉得它是一个高深的技术。实际上,从实现角度来看,虚拟设备veth与我们日常接触的lo设备非常相似。基于veth的本机网络IO通信图直接从《.0.0.1的那篇文章》中复制而来。只要你看过飞哥的《.0.0.1的那篇文章》,理解veth将变得非常容易。 只是与lo设备相比,veth是为了虚拟化技术而设计的,因此它具有配对的概念。在`veth_newlink`函数中,一次创建了两个网络设备,并将对方设置为各自的peer。在发送数据时,找到发送设备的peer,然后发起软中断让对方收取数据即可。 怎么样,是不是很容易理解! 轻松理解 Docker 网络虚拟化基础之veth设备!å¦ä½å¦ä¹ Docker
å¦ä½å¦ä¹ Docker
对äºå¨æ ¡å¦çèè¨ï¼åºè¯¥å¦ä½å»å¦ä¹ dockerï¼æ¯ç«å¦æ ¡æ²¡æå ·ä½çåºç¨éæ±ä½ä¸ºå¼å¯¼ï¼æ以åºè¯¥å¦ä½å»ç 究Dockerï¼è¿æï¼Dockerçæºä»£ç æ没æå¿ è¦å»ç 究ï¼
é¦å æ说æä¸ï¼ææ¯ä¸ä½å¨æµæ±å¤§å¦VLISå®éªå®¤äºè®¡ç®é¡¹ç®ç»çå¦çï¼ä½¿ç¨è¿Dockerï¼ç 究è¿Dockeråå ¶æºç ï¼ä¹å®å¶è¿Dockerã
对äºå¦çå¦ä½å¦ä¹ Dockerï¼æ认为é¦å è¦çä¸ä¸å¦ç个人çç¥è¯èæ¯ãè½å©ç¨çèµæºèµæºã以åä¸ªäººå ´è¶£ååå±æ¹åã
1.å¦ä¹ Dockerï¼å¦æ没æäºè®¡ç®çåºæ¬ç¥è¯ï¼ä»¥åå æ ¸çåºæ¬ç¥è¯ï¼é£ä¹å¦ä¹ 并ç解起æ¥ä¼ç¨ååãä½ä¸ºå®¹å¨ï¼Docker容å¨çä¼å¿å¨åªï¼ä¸è¶³å¨åªï¼æ好äºè§£å®¹å¨çå®ç°æ¯ææ ·çï¼ç®åäºè§£ï¼ï¼æ¥æéå管çï¼Dockerå该å¦ä½ä½ç°è½¯ä»¶å¼åï¼éæï¼é¨ç½²ï¼åå¸ï¼åè¿ä»£ç软件çå½å¨æ管çä¼å¿ã以ä¸ä¸¤ç¹æ认为æä¸ºå ³é®ï¼æè¿ä¸¤æ¹é¢ç认è¯å¿å¿ ä¼å¯¹ä¹åçå·¥ä½å¸®å©å·¨å¤§ã
2.å ³äºå¦ä¹ èµæºï¼èµ·ç ç硬件设æ½æ»æ¯è¦æçãDockeråå ¶çæçåå±å¾å¿«ï¼ä¸ä½¿ç¨çº¯ç论è¯å®æ¶æçå¾®ãå¦å¤ï¼èµæºè¿å æ¬Dockerå®æ¹ï¼å大çµååªä½å¹³å°ï¼ææ¯è®ºåï¼å¼æºç¤¾åºçï¼å¾å¾å¤§æ¿çè§ç¹è½ç¹ç ´èªå·±çå°æï¼æè 让èªå·±ç¥éåªæ¹é¢ç认è¯è¿å¾æ¬ 缺ï¼ä»¥å让èªå·±å°èµ°å¾å¤ç弯路ã
3.ä¸ªäººå ´è¶£çè¯ï¼å½ç»ä¸ºå¼ºæççä¸çãèµ·ç åºè¯¥è®¤åDockerç设计价å¼ï¼ä»¥åDockerçæªæ¥æ½åï¼å½ç¶æä¾æ®çæ¹å¤Docker并带å¨å¤§å®¶çæèï¼ä¹æ¯æ·±åå ³æ³¨ç表ç°ã
4.个人åå±æ¹åï¼æ认为å¦æéè¦æDockerå½ä½è½¯ä»¶çå½å¨æ管çå·¥å ·çè¯ï¼é£ç¨å¥½Dockeræ为éè¦ï¼APIåå½ä»¤çç解ä¸ä½¿ç¨æ¯å¿ éçãå¦æä¸æ³¨ç³»ç»è®¾è®¡æ¹é¢ï¼é£ä¹é¤Docker以ä¸çç¥è¯ä¸ç»éªä¹å¤ï¼è¥æDockeræºç çå¦ä¹ ä¸ç解ï¼é£ä¹è¿äºè¯å®ä¼è®©ä½ çDockeræ°´å¹³æé«ä¸ä¸ªå±æ¬¡ã
-- 8 0
xds
å¦ä¹ Dockerï¼æ大ç好å¤æ¯è·è¿æ°ææ¯åå±æ¹åãæè§å¾å¨æ ¡çåºè¯¥æ²¡æå¤å°ç¡¬æ§éæ±å¨Dockerçç 究ä¸ï¼è¿ä¹æ¯ä¸ºä»ä¹å¦æ ¡æ²¡åå ·ä½åºç¨è¦æ±çåå ãæå®é çåæ³æ¯çä¸äºDocker使ç¨æ¡ä¾ï¼èªå·±å®è·µåºä¸äºç»éªåºè¯¥ä¼å以åç社ä¼å®è·µä¸èµ·å°ä½ç¨ã
ç 究dockerçæºä»£ç ï¼åºè¯¥å°ä½ ä¸å®å³å¿ä»äºäºè®¡ç®æ¹é¢çäºä¸æè ç 究ï¼é£ä¹ä½ å°±éè¦ä»¥ç 究è ç身份å»åä»ç»çæºç åæçå·¥ä½ã
-- 3 0
ååGTDer
æä½ä¸ºåå å·¥ä½çè¿æ¥äººæ¥è¯´ï¼æ认为åªæä½ çæ£åå å·¥ä½åï¼å¨å·¥ä½ä¸å¦ä¹ è·ææä¹ï¼æ¯ç«Dockerç¥è¯äºè®¡ç®å ¶ä¸çä¸ä¸ªè½¯ä»¶å¹³å°èå·²ï¼è¯´ä¸æ¥çä½ æ¯ä¸äºï¼æ°çææ¯åºç°Dockerä¸ä¸å®æ¯å¯ä¸éæ©ã
ä½ä¸ºå¦çäºè§£æ°ææ¯ç¡®å®æ å¯åéï¼ä¸å®è¦è½æç论转å为ç产åææ¯æ£éã
-- 3 0
9lives - ç±çæ´»ï¼ç±äºè®¡ç®ã
å¦ä¹ ä»»ä½ä¸ä¸ªå¼æºæ°ææ¯ï¼é¦å é®èªå·±å 个é®é¢ï¼
1. 为ä»è¦å¦ä¹ å®ï¼
2. å¦ä¹ å®éè¦äºè§£åªäºç¸å ³ç¥è¯ç¹ï¼
3. å¦ä½å¿«éå¦ä¹ ï¼
4. 该ææ¯ç使ç¨åºæ¯æ¯ä»ä¹ï¼
æ¿æ个人çå¦ä¹ ç»éªæ¥ä¸¾ä¾ï¼æ¬äººä¹åæ¯è¾äºè§£OpenStackï¼
为ä»è¦å¦ä¹ dockerï¼
åçï¼
dockeræ¯è½»é级èæåææ¯ï¼docker使linux容å¨ææ¯çåºç¨æ´å ç®ååæ åå
dockerçé度å¾å¿«,容å¨å¯å¨æ¶æ¯«ç§çº§ç
dockerå°å¼ååè¿ç»´èè´£åæ¸
docker解å³äºä¾èµå°ç±é®é¢
dockeræ¯æå ä¹æææä½ç³»ç»
dockeræçé£éåå±ççæå
å¾å¤IT巨头éæ¸å å ¥åæ¯æ
å¦ä¹ å®éè¦äºè§£åªäºç¸å ³ç¥è¯ç¹ï¼
åçï¼
äºè®¡ç®æ¦å¿µç¸å ³ï¼restapi, å¾®æå¡ï¼OpenStackï¼
Linux ç³»ç»ç®¡çï¼è½¯ä»¶å 管çï¼ç¨æ·ç®¡çï¼è¿ç¨ç®¡ççï¼
Linux å æ ¸ç¸å ³ï¼Cgroup, namespace çï¼
Linux æ件系ç»ååå¨ç¸å ³ï¼AUFSï¼BRFS,devicemapper çï¼
Linux ç½ç»ï¼ç½æ¡¥ï¼veth,iptablesçï¼
Linuxå®å ¨ç¸å ³ï¼Appmor,Selinux çï¼
Linuxè¿ç¨ç®¡çï¼Supervisord,Systemd etc)
Linux容å¨ææ¯ï¼LXCçï¼
å¼åè¯è¨ï¼Python, GO,Shell çï¼
3.å¦ä½å¿«éå¦ä¹ ï¼
åçï¼ä¸ªäººä½ä¼æ好æä¸ä¸ªå®é çéæ±æ项ç®æ¥è¾¹å®è·µè¾¹å¦ä¹ ï¼å ¥é¨å¯ä»¥åèï¼ç¬¬ä¸æ¬docker书ï¼åçä¸éï¼é常éåå ¥é¨ãé¤æ¤ä¹å¤ï¼é 读ç人çblogæ¯å¦å®æ¹blog /
BTW: ç读dockerææ¡£
-- 0 0
tuxknight
楼ä¸åä½è¯´çé½å¾å¥½ï¼æåè¡¥å ä¸ç¹ï¼
æ¾ä»½ç¸å ³çå®ä¹ å·¥ä½
-- 0 0
lancer
å·¥ä½åç 究æ¯ä¸¤ä¸ªæ¹åæ个人认为ï¼å·¥ä½éè¦éè¿ä½ çå®é æè½ä¸ºä¼ä¸å¸¦æ¥ç»æµæçï¼èç 究çè¯å¯ä»¥ä¸æ³¨æ个ç¹ãä½æ¯ç 究离ä¸å¼å·¥ä½ï¼å 为工ä½å¯ä»¥è®©ä½ æ´å¥½ççä¼ææ¯å¸¦æ¥çä»·å¼ï¼ä»¥åå¦ä½æä¾æ´å¥½çæå¡ï¼ç¨æ·ä½¿ç¨åºæ¯éè¦é£äºææ¯ççªç ´ãæäºè¿äºè®¤è¯ï¼ç¶åæ´å ä¸æ³¨çç 究æ个ææ¯ç¹ï¼è¿æ ·æ许å¯ä»¥è¯´ææ¯ååä¸æ¯åä¸å¼çã
-- 0 0
绿åè²å½±
dockerç°å¨ååç«çï¼å¼å¾å¦ä¹ ä¸ä¸ã
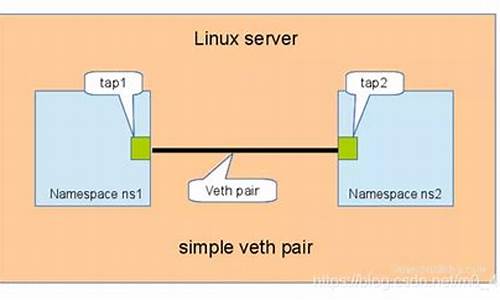
图解并茂|Linux中常用的虚拟网卡
在Linux的网络架构中,虚拟网卡(如tun, ifb)是内核提供的强大工具,随着虚拟化技术的发展,Linux源代码库不断扩展对网络虚拟化的支持。这不仅限于支持虚拟机,而是为用户和开发者提供了更多选择,适应了多样的网络应用场景。
网络虚拟化的技术种类繁多,从重量级的虚拟机技术,如支持每个虚拟机独立的协议栈,到轻量级的net namespace,它提供了独立的协议栈和网卡,适用于模拟多客户端网络连接,操作简便。例如,net namespace技术,虽然在去年已经有所实践,但学习过程中的探索精神和遇到新知识的惊喜感是持续的动力源泉。
本文将通过图形化的方式,介绍Linux中几种常见的与网络虚拟化相关的虚拟网卡,包括但不限于VETH、MACVLAN和IPVLAN。VETH,作为一对虚拟以太网卡,可以用于内核容器间通信,或通过桥接连接外部网络。MACVLAN则通过一个物理网卡虚拟出多个MAC地址,实现二层隔离,有bridge、VEPA和private模式。IPVLAN则在IP层进行流量分隔,支持L2或L3隔离。
对于MACVTAP,它是为了解决用户态虚拟机或协议栈模拟网卡的问题而设计,通过修改宿主机网卡的rx_handler,将数据直接发送到用户态设备,避免了传统TAP+Bridge的复杂性。
每个技术都有其适用的场景,选择哪种取决于具体的需求和环境。通过理解这些虚拟网卡的工作原理,开发者可以更好地利用Linux的网络虚拟化能力,提升网络管理和隔离的灵活性。
go-iptables功能与源码详解
介绍iptables之前我们先搬出他的父亲netfilter,netfilter是基于 Linux 2.4.x或更新的内核,提供了一系列报文处理的能力(过滤+改包+连接跟踪),具体来讲可以包含以下几个功能:
其实说白了,netfilter就是操作系统实现了网络防火墙的能力(连接跟踪+过滤+改包),而iptables就是用户态操作内核中防火墙能力的命令行工具,位于用户空间。快问快答,为啥计算机系统需要内核态和用户态(狗头)。
既然netfilter是对报文进行处理,那么我们就应该先了解一下内核是如何进行收发包的,发生报文大致流程如下:
netfilter框架就是作用于网络层中,在一些关键的报文收发处理路径上,加一些hook点,可以认为是一个个检查点,有的在主机外报文进入的位置(PREROUTING ),有的在经过路由发觉要进入本机用户态处理之前(INPUT ),有的在用户态处理完成后发出的地方(OUTPUT ),有的在报文经过路由并且发觉不是本机决定转发走的位置(FOWARD ),有的在路由转发之后出口的位置(POSTROUTING ),每个检查点有不同的规则集合,这些规则会有一定的优先级顺序,如果报文达到匹配条件(五元组之类的)且优先级最高的规则(序号越小优先级越高),内核会执行规则对应的动作,比如说拒绝,放行,记录日志,丢弃。
最后总结如下图所示,里面包含了netfilter框架中,报文在网络层先后经过的一些hook点:
报文转发视角:
iptables命令行工具管理视角:
规则种类:
流入本机路径:
经过本机路径:
流出本机路径:
由上一章节我们已经知道了iptables是用户态的命令行工具,目的就是为了方便我们在各个检查点增删改查不同种类的规则,命令的格式大致如下,简单理解就是针对具体的哪些流(五元组+某些特定协议还会有更细分的匹配条件,比如说只针对tcp syn报文)进行怎样的动作(端口ip转换或者阻拦放行):
2.1 最基本的增删改查
增删改查的命令,我们以最常用的filter规则为例,就是最基本的防火墙过滤功能,实验环境我先准备了一个centos7的docker跑起来(docker好啊,实验完了直接删掉,不伤害本机),并通过iptables配置一些命令,然后通过主机向该docker发生ping包,测试增删改查的filter规则是否生效。
1.查询
如果有规则会把他的序号显示出来,后面插入或者删除可以用 iptables -nvL -t filter --line
可以看出filter规则可以挂载在INPUT,FORWARD,OUTPUT检查点上,并且兜底的规则都是ACCEPT,也就是没有匹配到其他规则就全部放行,这个兜底规则是可以修改的。 我们通过ifconfig查看出docker的ip,然后主机去ping一波:
然后再去查一下,会发现 packets, bytes ---> 对应规则匹配到的报文的个数/字节数:
2. 新增+删除 新增一条拒绝的报文,我们直接把docker0网关ip给禁了,这样就无法通过主机ping通docker容器了(如果有疑问,下面有解答,会涉及docker的一些小姿势): iptables -I INPUT -s ..0.1 -j DROP (-I不指定序号的话就是头插) iptables -t filter -D INPUT 1
可见已经生效了,拦截了ping包,随后我删除了这条规则,又能够ping通了
3. 修改 通过-R可以进行规则修改,但能修改的部分比较少,只能改action,所以我的建议是先通过编号删除规则,再在原编号位置添加一条规则。
4. 持久化 当我们对规则进行了修改以后,如果想要修改永久生效,必须使用service iptables save保存规则,当然,如果你误操作了规则,但是并没有保存,那么使用service iptables restart命令重启iptables以后,规则会再次回到上次保存/etc/sysconfig/iptables文件时的模样。
再使用service iptables save命令保存iptables规则
5. 自定义链 我们可以创建自己的规则集,这样统一管理会非常方便,比如说,我现在要创建一系列的web服务相关的规则集,但我查询一波INPUT链一看,妈哎,条规则,这条规则有针对mail服务的,有针对sshd服务的,有针对私网IP的,有针对公网IP的,我这看一遍下来头都大了,所以就产生了一个非常合理的需求,就是我能不能创建自己的规则集,然后让这些检查点引用,答案是可以的: iptables -t filter -N MY_WEB
iptables -t filter -I INPUT -p tcp --dport -j MY_WEB
这就相当于tcp目的端口的报文会被送入到MY_WEB规则集中进行匹配了,后面有陆续新规则进行增删时,完全可以只针对MY_WEB进行维护。 还有不少命令,详见这位大佬的总结:
回过头来,讲一个关于docker的小知识点,就是容器和如何通过主机通讯的?
这就是veth-pair技术,一端连接彼此,一端连接协议栈,evth—pair 充当一个桥梁,连接各种虚拟网络设备的。
我们在容器内和主机敲一下ifconfig:
看到了吧,容器内的eth0和主机的vetha9就是成对出现的,然后各个主机的虚拟网卡通过docker0互联,也实现了容器间的通信,大致如下:
我们抓个包看一哈:
可以看出都是通过docker0网关转发的:
最后引用一波 朱老板总结的常用套路,作为本章结尾:
1、规则的顺序非常重要。
如果报文已经被前面的规则匹配到,IPTABLES则会对报文执行对应的动作,通常是ACCEPT或者REJECT,报文被放行或拒绝以后,即使后面的规则也能匹配到刚才放行或拒绝的报文,也没有机会再对报文执行相应的动作了(前面规则的动作为LOG时除外),所以,针对相同服务的规则,更严格的规则应该放在前面。
2、当规则中有多个匹配条件时,条件之间默认存在“与”的关系。
如果一条规则中包含了多个匹配条件,那么报文必须同时满足这个规则中的所有匹配条件,报文才能被这条规则匹配到。
3、在不考虑1的情况下,应该将更容易被匹配到的规则放置在前面。
4、当IPTABLES所在主机作为网络防火墙时,在配置规则时,应着重考虑方向性,双向都要考虑,从外到内,从内到外。
5、在配置IPTABLES白名单时,往往会将链的默认策略设置为ACCEPT,通过在链的最后设置REJECT规则实现白名单机制,而不是将链的默认策略设置为DROP,如果将链的默认策略设置为DROP,当链中的规则被清空时,管理员的请求也将会被DROP掉。
3. go-iptables安装
go-iptables是组件库,直接一波import " github.com/coreos/go-ip...",然后go mod tidy一番,就准备兴致冲冲的跑一波自带的测试用例集,没想到上来就是4个error:
这还了得,我直接去go-iptables的仓库issue上瞅瞅有没有同道中人,果然发现一个类似问题:
虽然都是test failures,但是错的原因是不一样的,但是看他的版本是1.8的,所以我怀疑是我的iptables的版本太老了,一个iptables -v看一眼:
直接用yum update好像不能升级,yum search也没看到最新版本,看来只能下载iptables源码自己编译了,一套连招先打出来:
不出意外的话,那就得出点意外了:
那就继续下载源码安装吧,然后发现libmnl 又依赖libnftnl ,所以直接一波大招,netfilter全家桶全安装:
Finally,再跑一次测试用例就成功了,下面就可以愉快的阅读源码了:
4. 如何使用go-iptables
5. go-iptables源码分析
关键结构体IPTables
初始化函数func New(opts ...option) (*IPTables, error) ,流程如下:
几个重要函数的实现:
其他好像也米有什么,这里面就主要介绍一下,他的命令行执行是怎么实现的:
6. Reference
二十分钟了解K8S网络模型原理
掌握K8S网络模型无需神秘,只需分钟,本文将带你轻松理解。首先,让我们预习一些基础网络知识:Linux网络命名空间:虚拟化网络栈,如同登录Linux服务器时的默认Host网络栈。
网桥设备:内核中的虚拟端口,用于转发网络数据。
Veth Pair:一对虚拟网卡,常用于连接不同网络命名空间。
VXLAN:扩展局域网,将L2数据包封装到UDP报文中,用于跨主机通信。
BGP:边界网关协议,实现自治系统间的路由可达性。
理解了这些,我们转向单机容器网络模型,这是Docker的基本架构。然后,我们进入K8S网络模型的探索,包括Flannel和Calico两种常见模型:Flannel:两种实现(UDP和VXLAN),分别涉及TUN设备或VXLAN隧道,以及Host-gw的三层解决方案。
Calico:非IPIP模式利用BGP维护路由,无网桥的直接路由规则;IPIP模式通过IP隧道解决跨子网通信问题。
最后,CNI网络插件是K8S的核心组件,负责在Pod创建时设置网络环境,如网络命名空间的配置和路由规则的设定。 通过本文,你将对K8S网络模型有深入理解,进一步实践将使理论更加扎实。详细教程和源代码可以参考相关资源。现在,你已经准备好了深入研究K8S网络的旅程。在Hyper-V中实现windows与linux共享上网
相信不少读者都会做(或者曾经做过)这么一项活动——把一个Linux系统安装到Windows系统下的虚拟机软件中,然后在Windows这个大环境中对Linux进行学习或者一些实验操作。在进行这么一项活动时,不知道各位读者是否感受到网络连通的重要性(这里指外网的Internet),而事实上,无论是在虚拟机中还是在真实的物理机上“玩”Linux,(外网)网络都扮演着一个非常重要的角色。试想一下,当我们的Linux无法(外网)网路,这时我们又需要安装一个gcc编译器,各位读者会怎么做?采用源码编译?我想,gcc的编译安装这并不是一般人所能够做到的。采用rpm包安装?那光解决rpm包的依赖性就可能要折腾不少的时间。采用yum,并且把源指向安装光盘?这,确实是可以解决gcc的安装问题。但是,各位读者是否又想过这么一个问题,虽然Linux的安装光盘确实已经为我们提供了不少的软件包,但是一个安装光盘才有多大呀,CentOS 6.4的安装光盘也就只有那个四个来G,这就意味着,光盘并不是万能的,还会有不少的软件我们是无法从光盘中获取的,比如Mono,我们就必须自己从官网中下载一个并自己编译安装。(外网)网络是如此的重要,我们是不能够失去它的,哪怕是在虚拟机中也不例外。
在现实生活中,虚拟机软有非常多的种类,比较有名并且常用的有VM、VirtualBox等。如果各位正在阅读此文的读者是使用VM机作为自己的Linux虚拟机的,那么你们是幸福的,因为VM这款软件做得非常好,它自带的NAT技术一下子就可以帮各位读者解决联网问题,换句话说,只要作为大环境的Windows可以正常的访问网络,那么只需要在VM的网卡设置用选择“nat”选项或者采用“8号网卡(vmnet8)”,安装在VM中的Linux就已经获得了访问(外网)网络的权利了,用户完全无需为了网络的事情而烦恼和折腾。
但是,既然在本文中是选择了Hyper-V作为虚拟机软件,那就代表着我们就没有VM那么幸福了,我们还得自己折腾一番才能争取到获得网络访问这个权利。
好的,正是进入主题,本文中,我们将讨论研究:
1、本文网络背景的介绍
2、如何在Linux中添加一张新网卡
3、如何实现Linux在Hyper-V中实现与Windows的共享宽带上网
4、TTL检测(路由封杀)网络环境的应对策略
1、当前实验网络背景的介绍
之前在网络中心常驻时,上网账号理论上是用不完的,当虚拟机中Linux想访问网络时,我们所采取的办法是正常的拨号上网,一台Linux要上网就拨一个号,十台Linux上网就拨十个号,通过这个方法,虚拟机中所有的Linux都能够访问网络。不过,这种方法是异常“奢侈”的,并且对于大部分读者来说也是非常不现实的。各位读者更多的则是像我当前的情况,从网络中心中撤离出来,回到宿舍,一共也就那么一个上网账号(还是自己花钱供养的),只能供一个主机同一时间访问网络的需要。
此外,当前的环境除了只有一个宽带账号的限制外,由于这里是一个校园网(包括许多高校的校园网、宽带小区或者部分地区电信、联通宽带用户),它们都会有防蹭网(路由器封杀)的这么一个功能,还真的只是一个宽带账号只能供一个主机访问网络(在这里,VM用户仍然不用担心这个问题)。
想要让Hyper-V中的Linux能够访问网络,各位读者可以通过一以下几个办法:
A、多开几个上网账号(非常耗费金钱)
B、买一个放封的路由(一次投资,多次回报,还是个不错的选择)
C、参考本文中的方法(虽不能保证一定能够成功,不过仍然值得一试,不行再采用前一种办法)
2、为Linux添加一块网卡
正式进入到我们的实验,为了不对当前的Linux环境造成干扰,我们决定采用为Linux添加一张新的网卡来进行我们当前的这个实验。
首先,先确保Hyper-V的“虚拟交换机管理器”中存在一个属性为“内部”适配器(如果没有,则需要自己添加一个,这里采用一张已有的网卡,各位读者不必为了这么长的名字而纠结)。
然后为Linux虚拟机添加一张网卡:
在这里,有几点是需要注意的:
(1)、虚拟交换机中请务必要选择“内部”属性的适配器(在这里选择的是刚刚新建的那张,名为:“Windows phone ……”)
(2)、添加硬件时,建议选择“旧版的网络适配器”,以防止一些版本的Linux系统缺少对新版网卡的驱动。
然后启动我们的Linux系统,直接使用“setup”设置网卡:
我们发现刚才新增的网卡是并没有被Linux识别的(在这里,我们使用的是CentOS 6.4 X_ 版本,其他发行版的Linux可能会有所出入),我们需要手动的添加一个网卡配置文件。添加方法非常简单,进入“/etc/sysconfig/network-scripts/”目录,然后执行“cp ifcfg-eth0 ifcfg-eth1”(把eth0的配置文件再拷贝一份到eth1中),然后使用vi编辑器打开刚刚拷贝得到的“ifcfg-eth1”配置文件:
然后对该配置文件作出以下修改:
(1)、把“DEVICE”中由eth0改为eth1
(2)、删除“HWADDR”这一行(删除配置文件记录的网卡硬件地址)
(3)、删除“UUID”这一行(删除配置文件中硬件的唯一标识)
然后保存并退出。
继续使用vi编辑器打开“/etc/udev/rules.d/-persistent-net.rules”,然后把里面的所有内容清空,保存并退出后重启Linux。
现在再setup就可以看到新添加的网卡了。
好的。就这样,我们成功的为Linux添加了一张新网卡。
3、对Hyper-V中的Linux赋予网络访问的权利
上一个小节中,我们添加了一张“内部”属性的适配器,现在我们把Windows中的宽带连接共享到这张“内部”适配器,让Linux能够共享Windows中的网络。
打开Windows中的“网络连接”:
里面有非常之多的网络适配器,这些大家都不用管,只需要留意图中两个蓝色框起来的适配器,一个为“宽带连接”(也就是Windows中的宽带连接),另一个是“vEthement(Internal Ethernet……)”(也就是在Hyper-V中新建的那一张内部网络适配器)。
在“宽带连接”中点击右键,选择“属性”,打开设置窗口,打开“共享”这个选项卡,勾上“允许其他网络用户通过此计算机的Internet连接来连接”,“家庭网络连接”这个下拉菜单中选择刚刚我们新建的“内部”网络适配器。
点击确定保存退出,断开当前的Windows宽带连接,重新拨号之后,刚才的设置即可生效。
然后继续设置我们的“内部”适配器的IP,如图所示,只要随意的设置一个与宽带连接不同网段的IP即可
然后,在Linux中的eth1网卡设置中采用DHCP的方式获取IP地址(有兴趣的读者可以分别尝试使用静态IP的方式和DHCP的方式获取Linux的IP,然后再对比一下“/etc/resolv”中的不同)
保存退出,并执行“service network restart”重启网络配置
现在尝试一下看能不能解析“www.baidu.com”的域名
嗯,非常好,我们的百度域名能够正常的解析,由于域名解析需要连网到DNS服务器,现在能够看到解析,这就表示,我们的Linux已经能够连网,具有网络访问的能力了。
4、应对拨号服务器的TTL检测
或许有一些读者遇过这么一种情况:现在有一个宽带的上网账号,由于某些原因(比如添置了一些新电脑之类的),想让几台电脑都能够共享这个宽带账号来上网,结果从电脑城中买回来一个路由器,非常正确的设置好相关的参数之后,竟然发现没有办法浏览网页,从路由器中的数据包监控中还发现,数据包不断的发送出去,却一个数据包都没有办法接收到。把路由器拿回电脑城中,路由器在哪里又能够正常的使用。
如果各位读者遇到了这种现象,并且排除了路由器故障这一问题之后,那就只能证明了一件事:当前的网路环境中存在对路由器使用的封杀,也就是在拨号服务器中有TTL的检测(当然,想要封杀路由器的使用方法有很多种,比较常用而且比较流行的办法就是采用TTL的检测,在本文中也是只针对TTL检测采取解决措施)。
关于什么是TTL值,各位读者可以用网上搜索详细的资料。在这里我只简单的解说一下:我们的数据包在网络中的传输,从一个网段的网络传输到另外一个网段的网络,这是需要路由器在其中发挥作用的,但是一个由多网段所组成的网络往往是非常庞大的(比如Internet),如果数据包没有一个传输次数的限制,那么就有可能发生这么一个事件:“数据包不断的在网络中传来传去,走遍了整个网络,并且还不断的重复这个动作”。这样,不仅使得网络的拥塞程度一下子大增甚至把整个网络挤垮,并且发送这个数据包的主机还无法获知这个数据包是否可达(也就是是否找到接收方或者接收方到底是否存在)。因此,为了解决这么一个问题,我们在发送数据包的时候,都会在数据包中设置一个TTL值,每当这个数据包经过一个路由器进行转发,数据包中的TTL值就会减1,直到数据包中的TTL值变为0,路由器就会自动的认为这个数据包是不可达的并自把这个数据包丢弃。
针对TTL值的这一个特性,只要在拨号服务器中增加一个TTL值的检测,只要用户是采用路由器上网的(具有放封功能的或者刷了放封固件的除外),到达拨号服务器中的数据包的TTL值就不是默认的TTL值(Windows默认的TTL为,Linux默认的TTL值为),如果在拨号服务器中再做这么一个小动作:“把所有不是默认TTL值的数据包全部丢弃”,这样就达到了对路由器封杀的效果。也就是各位读者在路由器的数据包监测中所看到的不断有数据包发出却一个数据包都没有办法收到的原因。
在本文中所介绍的Hyper-V共享上网中就遇到了这么一个问题(不一定所有读者都会遇到),比如我想从网上下载一个东西:
虽然DNS能够解析域名,但是却无法从网上下载东西。造成此现象的其中的原因就是:共享上网的原理跟使用路由器一样,而当前的校园网对路由器的使用有封杀。
要解决TTL检测并封杀路由器使用的方法比较直接,那就是修改数据包从网卡送出时的TTL值。
针对本文中的配置,我用excel画了一个简单的原理图,当虚拟机中的Linux通过eth1发送出一个数据包,该数据包会被发送到“内部”适配器中,然后“内部”适配器会充当一个路由的功能,把数据包转发到宽带连接中,接着,宽带连接也同样的充当同样的功能,把数据包转发出去。这里就存在着一个简单的算术题:“Windows默认的TTL值为,也就是从宽带连接中出来的数据包必须是的才不会被拨号服务器丢弃,而数据包每经过一次路由的转发TTL值就会减1,问从eth0中出来的数据包是多少时数据包才不会被拨号服务器丢弃?”聪明的读者一定能给很快的计算得出答案——!!!
好的,既然我们已经计算出合适的TTL值,我们二话不多说的去设置Linux的数据包TTL值。我们只需使用vi编辑器打开“/etc/sysctl.conf”,然后再最后的地方添加上这么一句“net.ipv4.ip_default_ttl=”,然后保存退出并重启网络。
这样,我们就可以突破了当前网络对路由器使用的封杀了。
瞧,这就可以下载东西了。
同时,这里还有一项需要读者们非常注意的地方:要时时刻刻的警惕seLinux和iptables所产生的作用,在本文中,如果这两项开启了的话,同样是无法下载东西的。各位读者要切记了。
至此,Linux(CentOS)如何在Hyper-V中实现与Windows宽带共享上网就到此结束了。