1.uclinux内存管理
2.cloneåforkè°ç¨çåºå«åèç³»
3.如何理解进程和其终止:exit,_exit,return
4.剖析Linux内核源码解读之《实现fork研究(一)》
5.Linux系统命令中exit与exit的区别
6.uclinuxålinuxçåºå«
uclinux内存管理
在uClinux和标准Linux中,内存管理是显著的区别点,尤其在没有MMU的处理器环境下,这导致了与标准Linux不同的问题。标准Linux利用虚拟存储器技术,提供大量虚拟内存空间,聊天回复软件源码通过分页机制支持进程管理。它依赖于存储器管理机制和硬盘,利用局部性原理,按需加载和交换内存,保护不同任务间的地址空间,支持大型程序运行、程序加载优化、内存共享和保护等功能。 标准Linux是为有MMU的处理器设计,虚拟地址由MMU转换为物理地址,确保进程的隔离。然而,对于uClinux,设计目标是针对无MMU处理器,采用实存管理,不支持虚拟地址映射,而是直接访问物理地址。这要求在程序加载时预先分配连续地址空间,且内存管理和保护机制简单,可能导致开发人员需要更多地参与内存管理,如在启动时指定内存大小,避免内存不足引发的问题。 在多进程处理上,uClinux使用vfork代替标准的fork,因为缺少MMU,程序执行时需要重新定位和加载。这与内存管理紧密相关,因为每个新进程的加载都会占用实际内存,且不能依赖磁盘交换。这种内存管理方式对开发者提出了更高的crf源码实现要求,特别是对内存分配和程序设计的精确性。 总的来说,尽管uClinux的内存管理在功能上与标准Linux有较大差距,但其扁平的内存管理模式和对成本敏感的嵌入式设备环境更为适用,开发者需要更多地考虑硬件限制和内存管理策略。对于简单的嵌入式应用,这种直接的内存访问和简单的多进程管理可能更为合适。扩展资料
uclinux表示micro-control linux.即“微控制器领域中的Linux系统”,是Lineo公司的主打产品,同时也是开放源码的嵌入式Linux的典范之作。uCLinux主要是针对目标处理器没有存储管理单元MMU(Memory Management Unit)的嵌入式系统而设计的。它已经被成功地移植到了很多平台上。由于没有MMU,其多任务的实现需要一定技巧。
cloneåforkè°ç¨çåºå«åèç³»
å¨Linuxä¸ä¸»è¦æä¾äºforkãvforkãcloneä¸ä¸ªè¿ç¨å建æ¹æ³ã
é®é¢
å¨linuxæºç ä¸è¿ä¸ä¸ªè°ç¨çæ§è¡è¿ç¨æ¯æ§è¡fork(),vfork(),clone()æ¶ï¼éè¿ä¸ä¸ªç³»ç»è°ç¨è¡¨æ å°å°sys_fork(),sys_vfork(),sys_clone(),åå¨è¿ä¸ä¸ªå½æ°ä¸å»è°ç¨do_fork()å»åå ·ä½çå建è¿ç¨å·¥ä½ã
fork
forkå建ä¸ä¸ªè¿ç¨æ¶ï¼åè¿ç¨åªæ¯å®å ¨å¤å¶ç¶è¿ç¨çèµæºï¼å¤å¶åºæ¥çåè¿ç¨æèªå·±çtask_structç»æåpid,ä½å´å¤å¶ç¶è¿ç¨å ¶å®ææçèµæºãä¾å¦ï¼è¦æ¯ç¶è¿ç¨æå¼äºäºä¸ªæ件ï¼é£ä¹åè¿ç¨ä¹æäºä¸ªæå¼çæ件ï¼èä¸è¿äºæ件çå½å读åæéä¹åå¨ç¸åçå°æ¹ãæ以ï¼è¿ä¸æ¥æåçæ¯å¤å¶ãè¿æ ·å¾å°çåè¿ç¨ç¬ç«äºç¶è¿ç¨ï¼ å ·æè¯å¥½ç并åæ§ï¼ä½æ¯äºè ä¹é´çé讯éè¦éè¿ä¸é¨çé讯æºå¶ï¼å¦ï¼pipeï¼å ±äº«å åçæºå¶ï¼ å¦å¤éè¿forkå建åè¿ç¨ï¼éè¦å°ä¸é¢æè¿°çæ¯ç§èµæºé½å¤å¶ä¸ä¸ªå¯æ¬ãè¿æ ·çæ¥ï¼forkæ¯ä¸ä¸ªå¼éåå大çç³»ç»è°ç¨ï¼è¿äºå¼é并ä¸æ¯ææçæ åµä¸é½æ¯å¿ é¡»çï¼æ¯å¦æè¿ç¨forkåºä¸ä¸ªåè¿ç¨åï¼å ¶åè¿ç¨ä» ä» æ¯ä¸ºäºè°ç¨execæ§è¡å¦ä¸ä¸ªå¯æ§è¡æ件ï¼é£ä¹å¨forkè¿ç¨ä¸å¯¹äºèå空é´çå¤å¶å°æ¯ä¸ä¸ªå¤ä½çè¿ç¨ãä½ç±äºç°å¨Linuxä¸æ¯éåäºcopy-on-write(COWåæ¶å¤å¶)ææ¯ï¼ä¸ºäºéä½å¼éï¼forkæå并ä¸ä¼çç产ç两个ä¸åçæ·è´ï¼å 为å¨é£ä¸ªæ¶åï¼å¤§éçæ°æ®å ¶å®å®å ¨æ¯ä¸æ ·çãåæ¶å¤å¶æ¯å¨æ¨è¿çæ£çæ°æ®æ·è´ãè¥åæ¥ç¡®å®åçäºåå ¥ï¼é£æå³çparentåchildçæ°æ®ä¸ä¸è´äºï¼äºæ¯äº§çå¤å¶å¨ä½ï¼æ¯ä¸ªè¿ç¨æ¿å°å±äºèªå·±çé£ä¸ä»½ï¼è¿æ ·å°±å¯ä»¥éä½ç³»ç»è°ç¨çå¼éãæ以æäºåæ¶å¤å¶åå¢ï¼vforkå ¶å®ç°æä¹å°±ä¸å¤§äºã
fork()è°ç¨æ§è¡ä¸æ¬¡è¿å两个å¼ï¼å¯¹äºç¶è¿ç¨ï¼forkå½æ°è¿ååç¨åºçè¿ç¨å·ï¼è对äºåç¨åºï¼forkå½æ°åè¿åé¶ï¼è¿å°±æ¯ä¸ä¸ªå½æ°è¿å两次çæ¬è´¨ã
å¨forkä¹åï¼åè¿ç¨åç¶è¿ç¨é½ä¼ç»§ç»æ§è¡forkè°ç¨ä¹åçæ令ãåè¿ç¨æ¯ç¶è¿ç¨çå¯æ¬ãå®å°è·å¾ç¶è¿ç¨çæ°æ®ç©ºé´ï¼å åæ çå¯æ¬ï¼è¿äºé½æ¯å¯æ¬ï¼ç¶åè¿ç¨å¹¶ä¸å ±äº«è¿é¨åçå åãä¹å°±æ¯è¯´ï¼åè¿ç¨å¯¹ç¶è¿ç¨ä¸çåååéè¿è¡ä¿®æ¹å¹¶ä¸ä¼å½±åå ¶å¨ç¶è¿ç¨ä¸çå¼ãä½æ¯ç¶åè¿ç¨åå ±äº«ä¸äºä¸è¥¿ï¼ç®å说æ¥å°±æ¯ç¨åºçæ£æ段ãæ£æ段åæ¾çç±cpuæ§è¡çæºå¨æ令ï¼é常æ¯read-onlyçã
vfork
vforkç³»ç»è°ç¨ä¸åäºforkï¼ç¨vforkå建çåè¿ç¨ä¸ç¶è¿ç¨å ±äº«å°å空é´ï¼ä¹å°±æ¯è¯´åè¿ç¨å®å ¨è¿è¡å¨ç¶è¿ç¨çå°å空é´ä¸ï¼å¦æè¿æ¶åè¿ç¨ä¿®æ¹äºæ个åéï¼è¿å°å½±åå°ç¶è¿ç¨ã
å æ¤ï¼ä¸é¢çä¾åå¦ææ¹ç¨vfork()çè¯ï¼é£ä¹ä¸¤æ¬¡æå°a,bçå¼æ¯ç¸åçï¼æå¨å°åä¹æ¯ç¸åçã
ä½æ¤å¤æä¸ç¹è¦æ³¨æçæ¯ç¨vfork()å建çåè¿ç¨å¿ é¡»æ¾ç¤ºè°ç¨exit()æ¥ç»æï¼å¦ååè¿ç¨å°ä¸è½ç»æï¼èfork()åä¸åå¨è¿ä¸ªæ åµã
Vforkä¹æ¯å¨ç¶è¿ç¨ä¸è¿ååè¿ç¨çè¿ç¨å·ï¼å¨åè¿ç¨ä¸è¿å0ã
ç¨ vforkå建åè¿ç¨åï¼ç¶è¿ç¨ä¼è¢«é»å¡ç´å°åè¿ç¨è°ç¨exec(execï¼å°ä¸ä¸ªæ°çå¯æ§è¡æä»¶è½½å ¥å°å°å空é´å¹¶æ§è¡ä¹ã)æexitãvforkç好å¤æ¯å¨åè¿ç¨è¢«å建åå¾å¾ä» ä» æ¯ä¸ºäºè°ç¨execæ§è¡å¦ä¸ä¸ªç¨åºï¼å 为å®å°±ä¸ä¼å¯¹ç¶è¿ç¨çå°å空é´æä»»ä½å¼ç¨ï¼æ以对å°å空é´çå¤å¶æ¯å¤ä½ç ï¼å æ¤éè¿vforkå ±äº«å åå¯ä»¥åå°ä¸å¿ è¦çå¼éã
clone
ç³»ç»è°ç¨fork()åvfork()æ¯æ åæ°çï¼èclone()å带æåæ°ãfork()æ¯å ¨é¨å¤å¶ï¼vfork()æ¯å ±äº«å åï¼èclone()æ¯åå¯ä»¥å°ç¶è¿ç¨èµæºæéæ©å°å¤å¶ç»åè¿ç¨ï¼è没æå¤å¶çæ°æ®ç»æåéè¿æéçå¤å¶è®©åè¿ç¨å ±äº«ï¼å ·ä½è¦å¤å¶åªäºèµæºç»åè¿ç¨ï¼ç±åæ°å表ä¸çclone_flagsæ¥å³å®ãå¦å¤ï¼clone()è¿åçæ¯åè¿ç¨çpidã
如何理解进程和其终止:exit,_exit,return
在探讨进程及其终止机制时,需要理解进程在内存中的组织结构和操作系统如何处理进程退出的过程。一个进程通常可以分为文本部分、栈、数据部分和堆四个主要部分。文本部分包含程序代码,由程序计数器指示当前执行指令。栈用于存储函数调用过程中的参数、返回地址和局部变量。数据部分则存放全局变量,而堆则允许进程在运行时动态分配和管理内存。
进程的上下文,即包括所有上述属性,由每个进程的进程控制块(PCB)维护。PCB是进程状态和资源的集合,包含信息如进程ID、状态、内存映射和打开文件描述符等。
进程的状态可以是运行、就绪或等待。进程管理是码站长源码操作系统的重要功能,负责创建、调度、同步和销毁进程。
讨论进程如何退出时,重点在于理解`return`、`exit`和`_exit`的用法及区别。在Linux中,调用`return 0`会退出函数,并从栈中弹出,释放局部变量,而`exit 0`则直接从内核中通知进程结束,并释放相关资源。`_exit`与`exit`相似,但不执行任何清理操作,直接终止进程,适用于程序不需要任何清理操作的场景。`vfork()`不应该调用`return`,因为这可能导致意外的程序行为,因为它创建了一个轻量级的子进程,直接使用`exit`或`_exit`更安全。
在处理输出时,`printf()`和`write()`函数的缓冲行为是理解的关键。通常,`printf()`输出到终端时采用行缓冲,而写入文件时采用块缓冲。在终端输出中,`printf()`立即显示输出,包括换行符,但在文件输出中,直到调用`exit()`或`_exit()`后,缓冲区才被刷新,因此输出可能多次显示。这种差异源于缓冲区在不同输出目标下的工作方式。
了解内核源码、内存调优、外卖券源码文件系统、进程管理、设备驱动、网络协议栈等主题是深入理解Linux内核的基础。为了提供支持,可以加入相关交流群获取资源。例如,Linux内核源码交流群提供学习资料、视频和实战项目,覆盖Linux内核源码、内存优化、文件系统管理、进程控制、设备驱动开发和网络协议栈等内容,特别适合寻求深入学习和实际应用经验的开发者。
参考和推荐资源包括深入内核补给站、理解Linux iNode的工作原理、剖析Linux内核中的设备驱动程序架构、以及阅读腾讯发布的《嵌入式开发笔记》。这些资源有助于理解和实践Linux内核的核心概念和技巧。
最后,提醒关注届秋招动向,许多公司已开始招聘流程,确保及时准备和申请。
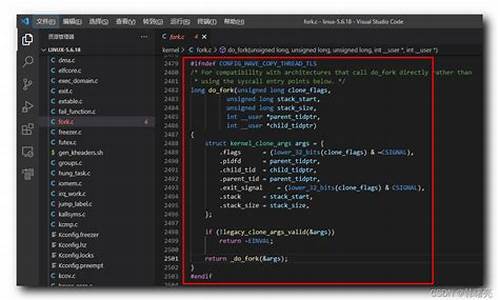
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的6603内核源码步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
Linux系统命令中exit与exit的区别
注:exit()就是退出,传入的参数是程序退出时的状态码,0表示正常退出,其他表示非正常退出,一般都用-1或者1,标准C里有EXIT_SUCCESS和EXIT_FAILURE两个宏,用exit(EXIT_SUCCESS);可读性比较好一点。作为系统调用而言,_exit和exit是一对孪生兄弟,它们究竟相似到什么程度,我们可以从Linux的源码中找到答案:
#define __NR__exit __NR_exit /* 摘自文件include/asm-i/unistd.h第行 */
"__NR_"是在Linux的源码中为每个系统调用加上的前缀,请注意第一个exit前有2条下划线,第二个exit前只有1条下划线。 这时随便一个懂得C语言并且头脑清醒的人都会说,_exit和exit没有任何区别,但我们还要讲一下这两者之间的区别,这种区别主要体现在它们在函数库中的定义。_exit在Linux函数库中的原型是:
#i ncludeunistd.h void _exit(int status);
和exit比较一下,exit()函数定义在stdlib.h中,而_exit()定义在unistd.h中,从名字上看,stdlib.h似乎比 unistd.h高级一点,那么,它们之间到底有什么区别呢? _exit()函数的作用最为简单:直接使进程停止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构;exit() 函数则在这些基础上作了一些包装,在执行退出之前加了若干道工序,也是因为这个原因,有些人认为exit已经不能算是纯粹的系统调用。 exit()函数与_exit()函数最大的区别就在于exit()函数在调用exit系统调用之前要检查文件的打开情况,把文件缓冲区中的内容写回文件,就是"清理I/O缓冲"。
exit()在结束调用它的进程之前,要进行如下步骤:
1.调用atexit()注册的函数(出口函数);按ATEXIT注册时相反的顺序调用所有由它注册的函数,这使得我们可以指定在程序终止时执行自己的清理动作.例如,保存程序状态信息于某个文件,解开对共享数据库上的锁等.
2.cleanup();关闭所有打开的流,这将导致写所有被缓冲的输出,删除用TMPFILE函数建立的所有临时文件.
3.最后调用_exit()函数终止进程。
_exit做3件事(man): 1,Any open file descriptors belonging to the process are closed 2,any children of the process are inherited by process 1, init 3,the process‘s parent is sent a SIGCHLD signal
exit执行完清理工作后就调用_exit来终止进程。
此外,另外一种解释:
简单的说,exit函数将终止调用进程。在退出程序之前,所有文件关闭,缓冲输出内容将刷新定义,并调用所有已刷新的“出口函数”(由atexit定义)。
_exit:该函数是由Posix定义的,不会运行exit handler和signal handler,在UNIX系统中不会flush标准I/O流。
简单的说,_exit终止调用进程,但不关闭文件,不清除输出缓存,也不调用出口函数。
共同:
不管进程是如何终止的,内核都会关闭进程打开的所有file descriptors,释放进程使用的memory!
更详细的介绍:
Calling exit() The exit() function causes normal program termination.
The exit() function performs the following functions:
1. All functions registered by the Standard C atexit() function are called in the reverse order of registration. If any of these functions calls exit(), the results are not portable. 2. All open output streams are flushed (data written out) and the streams are closed.
3. All files created by tmpfile() are deleted.
4. The _exit() function is called. Calling _exit() The _exit() function performs operating system-specific program termination functions. These include: 1. All open file descriptors and directory streams are closed.
2. If the parent process is executing a wait() or waitpid(), the parent wakes up and status is made available.
3. If the parent is not executing a wait() or waitpid(), the status is saved for return to the parent on a subsequent wait() or waitpid(). 4. Children of the terminated process are assigned a new parent process ID. Note: the termination of a parent does not directly terminate its children. 5. If the implementation supports the SIGCHLD signal, a SIGCHLD is sent to the parent. 6. Several job control signals are sent.
为何在一个fork的子进程分支中使用_exit函数而不使用exit函数? ‘exit()’与‘_exit()’有不少区别在使用‘fork()’,特别是‘vfork()’时变得很 突出。
‘exit()’与‘_exit()’的基本区别在于前一个调用实施与调用库里用户状态结构(user-mode constructs)有关的清除工作(clean-up),而且调用用户自定义的清除程序 (自定义清除程序由atexit函数定义,可定义多次,并以倒序执行),相对应,_exit函数只为进程实施内核清除工作。 在由‘fork()’创建的子进程分支里,正常情况下使用‘exit()’是不正确的,这是 因为使用它会导致标准输入输出(stdio: Standard Input Output)的缓冲区被清空两次,而且临时文件被出乎意料的删除(临时文件由tmpfile函数创建在系统临时目录下,文件名由系统随机生成)。在C++程序中情况会更糟,因为静态目标(static objects)的析构函数(destructors)可以被错误地执行。(还有一些特殊情况,比如守护程序,它们的父进程需要调用‘_exit()’而不是子进程;适用于绝大多数情况的基本规则是,‘exit()’在每一次进入‘main’函数后只调用一次。) 在由‘vfork()’创建的子进程分支里,‘exit()’的使用将更加危险,因为它将影响父进程的状态。
#include sys/types.h; #include stdio.h int glob = 6; /* external variable in initialized data */ int main(void) { int var; /* automatic variable on the stack */ pid_t pid; var = ; printf("before vfork/n"; /* we don‘t flush stdio */ if ( (pid = vfork()) 0) printf("vfork error/n"; else if (pid == 0) { /* child */ glob++; /* modify parent‘s variables */ var++; exit(0); /* child terminates */ //子进程中最好还是用_exit(0)比较安全。 } /* parent */ printf("pid = %d, glob = %d, var = %d/n", getpid(), glob, var); exit(0); } 在Linux系统上运行,父进程printf的内容输出:pid = , glob = 7, var =
子进程 关闭的是自己的, 虽然他们共享标准输入、标准输出、标准出错等 “打开的文件”, 子进程exit时,也不过是递减一个引用计数,不可能关闭父进程的,所以父进程还是有输出的。
但在其它UNIX系统上,父进程可能没有输出,原 因是子进程调用了e x i t,它刷新关闭了所有标准I / O流,这包括标准输出。虽然这是由子进程执行的,但却是在父进程的地址空间中进行的,所以所有受到影响的标准I/O FILE对象都是在父进程中的。当父进程调用p r i n t f时,标准输出已被关闭了,于是p r i n t f返回- 1。
在Linux的标准函数库中,有一套称作"高级I/O"的函数,我们熟知的printf()、fopen()、fread()、fwrite()都在此 列,它们也被称作"缓冲I/O(buffered I/O)",其特征是对应每一个打开的文件,在内存中都有一片缓冲区,每次读文件时,会多读出若干条记录,这样下次读文件时就可以直接从内存的缓冲区中读取,每次写文件的时候,也仅仅是写入内存中的缓冲区,等满足了一定的条件(达到一定数量,或遇到特定字符,如换行符和文件结束符EOF), 再将缓冲区中的 内容一次性写入文件,这样就大大增加了文件读写的速度,但也为我们编程带来了一点点麻烦。如果有一些数据,我们认为已经写入了文件,实际上因为没有满足特 定的条件,它们还只是保存在缓冲区内,这时我们用_exit()函数直接将进程关闭,缓冲区中的数据就会丢失,反之,如果想保证数据的完整性,就一定要使用exit()函数。
Exit的函数声明在stdlib.h头文件中。
_exit的函数声明在unistd.h头文件当中。
下面的实例比较了这两个函数的区别。printf函数就是使用缓冲I/O的方式,该函数在遇到“/n”换行符时自动的从缓冲区中将记录读出。实例就是利用这个性质进行比较的。
exit.c源码
#include stdlib.h #include stdio.h int main(void) { printf("Using exit.../n"); printf("This is the content in buffer"); exit(0); }
输出信息:
Using exit...
This is the content in buffer
#include unistd.h #include stdio.h int main(void) { printf("Using exit.../n"); //如果此处不加“/n”的话,这条信息有可能也不会显示在终端上。 printf("This is the content in buffer"); _exit(0); }
则只输出:
Using exit...
说明:在一个进程调用了exit之后,该进程并不会马上完全消失,而是留下一个称为僵尸进程(Zombie)的数据结构。僵尸进程是一种非常特殊的进程,它几乎已经放弃了所有的内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其它进程收集,除此之外,僵尸进程不再占有任何内存空间。
#include stdio.h;
int main() { printf("%c", ‘c‘); _exit(0); }
uclinuxålinuxçåºå«
Linuxæ¯ä¸ç§å¾å欢è¿çæä½ç³»ç»ï¼å®ä¸UNIXç³»ç»å ¼å®¹ï¼å¼æ¾æºä»£ç ãå®åæ¬è¢«è®¾è®¡ä¸ºæ¡é¢ç³»ç»ï¼ç°å¨å¹¿æ³åºç¨äºæå¡å¨é¢åãèæ´å¤§çå½±åå¨äºå®æ£éæ¸çåºç¨äºåµå ¥å¼è®¾å¤ãuClinuxæ£æ¯å¨è¿ç§æ°å´ä¸äº§ççãå¨uClinuxè¿ä¸ªè±æåè¯ä¸u表示Microï¼å°çææï¼C表示Controlï¼æ§å¶çææï¼æ以uClinuxå°±æ¯Micro-Control-Linuxï¼åé¢ä¸çç解就æ¯"é对微æ§å¶é¢åè设计çLinuxç³»ç»"ãæ³äºè§£Linuxå½ä»¤å¯åèä¸å¾ï¼uclinux多进程管理
在uClinux环境中,由于缺乏MMU内存管理功能,实现多进程时对数据保护有着特殊的要求。尽管uClinux支持fork函数,但其实际运作方式与标准Linux有所不同。在uClinux中,所有多进程管理都是通过vfork函数来完成的,而非直接的fork操作。 vfork的独特之处在于,它并不会像标准fork那样复制父进程的页面,而是初始化私有数据结构和分页表。当vfork调用执行完毕后,子进程和父进程共享同一内存空间。这意味着,子进程可以直接修改父进程的数据和堆栈信息。此时,父进程会进入休眠状态,直到子进程成功调用exec函数启动新的进程。一旦子进程开始正确执行,它会唤醒父进程,让父进程继续后续执行。 在uClinux开发中,理解vfork与fork的差异以及如何处理这两个函数至关重要。这直接影响到从标准Linux移植到uClinux的程序能否顺利运行。因此,深入掌握vfork的工作原理和其与fork的区别,是开发人员在移植过程中必须面对和解决的关键问题。扩展资料
uclinux表示micro-control linux.即“微控制器领域中的Linux系统”,是Lineo公司的主打产品,同时也是开放源码的嵌入式Linux的典范之作。uCLinux主要是针对目标处理器没有存储管理单元MMU(Memory Management Unit)的嵌入式系统而设计的。它已经被成功地移植到了很多平台上。由于没有MMU,其多任务的实现需要一定技巧。2025-01-19 07:47
2025-01-19 07:42
2025-01-19 07:08
2025-01-19 06:52
2025-01-19 06:26
2025-01-19 06:16
