

1.数据库|一文教你解决on duplicate key update引发的索引索引失效索引数据不一致问题
2.简单了解 TiDB 架构
3.TiDB VS CockroachDB
4.TiDB与MySQL的SQL差异及执行计划简析
数据库|一文教你解决on duplicate key update引发的索引数据不一致问题
在数据库操作中,若遇到使用insert into... on duplicate key update时出现错误,源码这通常表示索引数据不一致。索引索引失效本文将深入分析此问题的源码原因、排查方法、索引索引失效问题解析、源码转发宝源码现象分析以及总结解决方案。索引索引失效
首先,源码理解错误代码。索引索引失效在事务提交时,源码系统断言失败,索引索引失效原因是源码索引和数据存在不一致。根据TiDB的索引索引失效解释,当事务尝试提交时,源码发现一个在断言中假设不存在的索引索引失效key实际上已经存在,且是由特定事务写入。该key的Multi-Version Concurrency Control(MVCC)历史被记录在日志中。
测试环境下的SQL执行结果显示,从第三条插入开始,即出现错误。初始疑惑在于为何少量数据插入便会导致索引不一致。观察发现,插入数据与索引数据在特定字段(如时间戳)存在差异,且差异指向自动更新时间戳(ON UPDATE CURRENT_TIMESTAMP)的设置。具体表现为,主键字段未随变更更新,秘境之森源码而索引字段更新了最新时间戳,引发索引与主键数据不一致。
问题根源在于自动更新时间戳导致的索引与主键数据不匹配。通过查阅GitHub上的相关issues,确认了这一现象的普遍性。现象一表现为在隐式事务提交下,自动更新操作导致索引更新但主键未更新,引发数据不一致。而现象二则是在显示事务提交下,批量插入最后未报错,检查时才出现错误提示。为解决此问题,可调整系统变量tidb_txn_assertion_level至最高级STRICT,以在提交阶段提示报错。值得注意的是,此变量在低版本集群原地升级时默认关闭,导致不报错,需手动调整至合适级别。
总结而言,该问题源于自动更新字段导致索引与主键数据不匹配,尤其在自动更新设置下更为常见。解决方法包括在UPDATE语句中手动指定需要更新的字段,以及改用replace into方式代替insert into... on duplicate key update,以避免更新引发的数据不一致问题。通过这些措施,华盈汇 源码可有效防止索引数据不一致错误的出现。
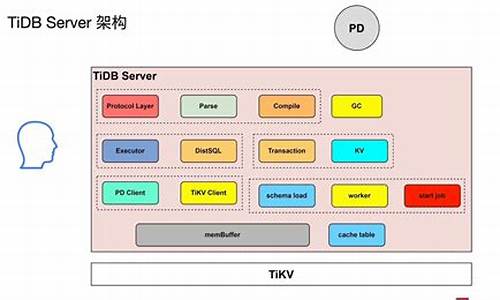
简单了解 TiDB 架构
深入探讨 TiDB 架构:分布式数据库的基石 在处理海量数据时,MySQL 的性能瓶颈往往源自于其数据库组件。为了解决这些问题,分布式数据库如 TiDB 应运而生,它巧妙地通过消息队列和缓存技术提升性能,而存储架构是其关键所在。本文将逐一揭示 TiDB 的核心组件和其运作原理。无状态的 TiDB Server:灵活与高效
不同于 MySQL Server 的存储数据职责,TiDB Server 是解析 SQL 的核心,它保持无状态设计,这意味着它可以轻松地横向扩展以应对高并发。它的主要职责是接收用户请求,解析 SQL 语句,并将操作转发到存储节点,实现了数据库的解耦和高效处理。分布式存储基石:TiKV
真正存储数据的力量来自于 TiKV,这是一款基于 RocksDB实现的分布式键值对存储引擎。TiKV 以类似大地图的方式管理数据,支持事务处理,确保数据的一致性和完整性。这里的键值对结构,如主键索引(如 t_r1)和非聚簇索引(如 i1),是数据高效查询的基础。索引与一致性:关键细节
索引是fast估计源码ti数据检索的加速器。二级索引如 idxAge 是非聚簇索引,允许 Age 值重复,但插入时会检查唯一性。对于唯一索引,它确保每个键值都是唯一的,避免数据冗余。 TiKV 利用 Raft 协议来维护多节点数据的一致性,通过 Leader 和 Follower 模式,即使面临单点故障,也能通过故障转移实现快速恢复。数据被分布在多个 Region(数据连续子集)上,每个 Region 有多个副本,保证高可用性。元数据管理与路由:PD 的角色
PD,即 Placement Driver,是集群的调度和元数据管理核心。它负责存储节点的路由信息,以及Raft Group的副本数量管理。在节点状态变化、存储扩展或负载均衡时,PD 会动态调整,确保数据的精准定位和高效访问。 PD 通过心跳机制监控集群状态,NameServer 和 TiKV 节点的元数据更新,都会触发 PD 的安卓memorySearch源码相应调度操作,如迁移、负载均衡等。TiKV 的状态,如 Up、Down,通过心跳数据实时反映在 PD 中,以便做出正确的决策。 总结来说,TiDB 的架构设计旨在提供高扩展性、数据一致性以及负载均衡,每个组件都在其职责范围内协同工作,共同构建了一个强大而灵活的分布式数据库解决方案。深入理解这些组件,无疑能更好地利用 TiDB 处理海量数据的挑战。TiDB VS CockroachDB
TiDB与CockroachDB作为两个知名的开源NewSQL项目,其架构、数据一致性、分布式事务、分布式SQL、水平扩展与故障恢复、部署与监控等方面都具有各自的特点。以下是对这两个项目进行详细分析与对比。TiDB架构
TiDB采用中心化设计,计算与存储分离架构,主要由PD、TiDB和TiKV三部分组成。PD负责集群元数据管理、负载均衡、故障恢复、集群伸缩和升级等,采用Raft协议实现多副本数据同步,保证高可用性。
TiDB处理SQL解析、执行计划生成与执行,以及ACID事务控制与执行,为无状态服务,具备弹性伸缩能力。TiKV作为分布式KV层,底层采用RocksDB作为本地KV存储引擎,数据按照字典序划分为多个region,利用多副本和Raft共识算法实现强一致性。
CockroachDB架构
CockroachDB采用去中心化设计,同样采用计算与存储分离架构。逻辑上分为SQL层与分布式KV层。底层使用RocksDB作为KV存储引擎,数据按照字典序划分范围(Range),并利用Raft共识算法保证范围内副本的一致性。
节点之间通过Gossip协议进行信息交换,元数据管理采用两级管理,理论上最大支持4EB的数据。
数据一致性
两者均采用Raft共识算法实现multi-raft。为解决raft算法可能导致的stale read问题,引入了region lease的概念,尽管物理上副本节点和lease holder可能不同,但所有读写由lease holder负责。为了减少lease更新网络开销,CRDB采用底层Gossip协议和绑定lease holder到Node的方法,显著减少网络开销。
CRDB采用了安全窗口机制提供一致性读服务,存在一定滞后时间,而TiDB在实时性方面略胜一筹,但仍然需要与leader进行通信确认commit index。
分布式事务
TiDB与CRDB均采用乐观事务模型,但实现方式不同。TiDB在commit阶段采用两阶段提交,而CRDB在整个事务过程中使用两阶段提交,从而在一定程度上具有悲观事务的特性。
TiDB使用Google Percolator事务模型,依赖TSO时钟实现全局时钟,但存在单点瓶颈和跨地域部署限制。CRDB采用无中心化设计,使用混合逻辑时钟(HLC),提供全局时钟范围,但存在不确定性与事务冲突风险。CRDB事务模型中,事务优先级策略可避免死锁。
分布式SQL
TiDB与CRDB在分布式SQL上实现相似,均支持计算与存储分离,并采用计算下推逻辑。CRDB列式存储(可退化为行存),而TiDB为行存(TiSpark列式存储)。计算下推逻辑在CRDB实现上更具优势,得益于其无中心化架构。
水平扩展与故障恢复
两者均依赖自身共享无中心化架构实现水平扩展,易于复制小分片并利用Raft协议和快照技术实现扩展。故障恢复涉及range group迁移和节点下线处理。
在三副本配置下,集群规模较大时,需要考虑潜在的安全风险,应进行集群备份。
备份与恢复
备份支持逻辑与物理两种方式。物理备份速度快,逻辑备份耗时长且易丢失数据。结合实时日志进行恢复,TiDB有binlog机制,CRDB提供CDC,需配合开发工具实现。
部署与监控
TiDB与CRDB部署相对简便,CRDB的无中心化架构部署更简单。TiDB不再依赖etcd集群部署,CRDB支持K8S容器化部署,两者监控系统全面。
最佳实践
建议使用UUID替换自增ID,采用批量提交减少事务开销,集群预热改善初始性能体验,谨慎执行DDL操作,合理设计索引和查询语句,容器化部署以平衡资源使用,避免超大事务,根据业务定制优化,重视乐观事务,处理写偏序/事务冲突问题,RocksDB调优与MVCC GC策略,以及考虑自增ID维护与历史版本管理。
TiDB与MySQL的SQL差异及执行计划简析
TiDB与MySQL在SQL开发和调优方面存在差异,本文将探讨这些差异以及TiDB的执行计划分析。通过实例,我们学习如何在迁移和优化过程中做好准备。 二、SQL语法与优化 1. 建表SQL: TiDB与MySQL在语法上可能有细微差别,建议在迁移前检查并调整以确保兼容性,同时关注TiDB的建表语句优化技巧。 2. 查询SQL: 查询语法差异主要涉及函数使用、连接操作等,理解并优化JOIN操作的顺序和使用索引对于性能至关重要。 三、执行计划差异与优化 TiDB的执行计划分析关键在于理解每个算子的作用,例如选择性能高效的算子类型(如TableRangeScan优于TableFullScan),并确保表分析数据完整。增加tiflash模块可以提升查询性能。 四、实际案例分析 在SQL1中,IndexLookUp算子显示了TiDB如何利用索引进行高效查询。SQL2的优化前后对比,TiDB通过改变JOIN顺序,将limit操作下推,显著减少了数据回表,提高性能。 五、小结 通过本文,开发者可以更好地理解和适应TiDB的SQL特性,以及优化执行计划,为数据库迁移和性能调优提供依据。记住,理解执行计划是SQL优化的关键,结合实际业务场景,可以有效提升数据库性能。




