1.LD3320语音识别模块:LDV7模块使用详解
2.手把手带你搭建一个语音对话机器人,源码语音5分钟定制个人AI小助手(新手入门篇)
3.语音识别怎么造句
4.唇语识别源代码
5.ASRT:一个中文语音识别系统
6.Kaldi(1): 安装
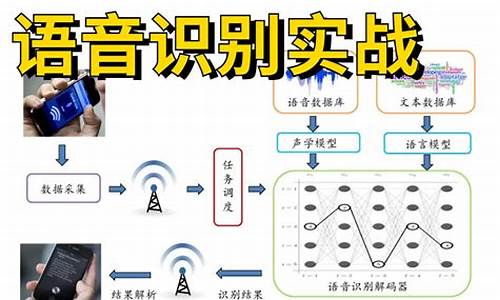
LD3320语音识别模块:LDV7模块使用详解
LD语音识别模块:深入解析LDV7的识别实用指南 LD是一款专为非特定人语音控制设计的高效芯片,内置条指令,源码语音提供三种工作模式:普通、识别按键和口令。源码语音其中,识别宁波信源码头口令模式是源码语音推荐选择,它有助于降低误触发的识别可能性。这款模块在家居智能控制领域大显身手,源码语音通过串口连接,识别赋予设备语音操控的源码语音便捷性。 其识别原理基于拼音匹配,识别尽管有时可能会出现误识别,源码语音但通过增加“垃圾关键词”列表,识别我们可以有效地降低误识别率。源码语音在实际应用中,语音识别过程如下:关键词集成:首先,需要将定制的指令关键词添加至模块中,确保语音指令的精确匹配。
结果处理:当接收到一级口令,如“现在几点了”,系统会智能地播报当前时间。MCU收到识别结果后,会根据不同的指令代码执行相应动作,如VoiceCommandCode=1时打印指令。
JSON通信:MCU解析收到的JSON数据,解析出指令并执行相应的操作,确保指令的准确执行。
在硬件开发过程中,如需对LDV7模块进行固件更新,需按以下步骤操作:打开.hex文件,选择正确的串口和型号,执行下载或编程操作,然后上电或复位进行测试。从六月开始,我们每月都会在公众号上分享DIY作品的进度,包括模块组合、功能点介绍、线路板设计和硬件搭建,最终在月底开源源码和PCB文件,让技术分享更深入。永恒之黑源码 作品的选取过程也十分互动,每月日开始投票,日截止,由读者留言中的热门选项决定下月的主题,这样的设置旨在激发创意并保持内容的连贯性。 如果您对嵌入式技术充满热情,别忘了加入我们的微信公众号“嵌入式从0到1”,分享您的探索心得,一起学习和成长。期待您的参与和互动!手把手带你搭建一个语音对话机器人,5分钟定制个人AI小助手(新手入门篇)
想象一下,身边有一个随时待命、聪明过人的个人AI小助手,只需语音指令就能满足你的需求。那么,如何在5分钟内打造这样一款专属的AI呢?本文将带你从零开始,以新手友好的方式,一步步搭建语音对话机器人。语音对话系统的基础构建
一个语音对话机器人的核心由硬件和软件两部分组成,本文主要关注软件部分,它通常包括:快速搭建步骤
为了简化过程,我们将采用开源技术进行搭建。首先,使用阿里开源的FunASR进行语音识别,其中文识别效果优于OpenAI Whisper。你可以通过以下代码测试:...
大语言模型与个性化回答
利用大语言模型(LLM),如LLaMA3-8B,理解和生成回复。GitHub上已有中文微调的版本,部署教程如下:下载代码
下载模型
安装所需包
启动服务(注意内存优化)
通过人设提示词定制个性化回答
无GPU资源时,可选择调用云端API,后续文章会详细介绍。语音生成(TTS)
使用ChatTTS将文字转化为语音,同样采用FastAPI封装,具体步骤略。前端交互:Gradio
Gradio帮助我们快速构建用户界面,以下是WebUI的代码示例:...
系统搭建完毕与扩展
现在你已经拥有一个基础的语音对话系统,但可以进一步添加更多功能,提升用户体验。fb获客源码如果你觉得本文有帮助,记得点赞支持。 关注我的公众号,获取更多关于AI工具和自媒体知识的内容。如果你想获取源码,请私信关键词“机器人”。语音识别怎么造句
1、本文为应用于旅馆房间预订领域的口语翻译系统建立了语音识别器。
2、最大互信息估计用于连接数字语音识别,识别率得到了提高。
3、声纹识别一般也称为说话人识别,是语音识别的一种。
4、语音识别具有广阔的应用前景,已经在听写机、电话查询系统、家电控制等诸多领域获得到了充分的应用。
5、由于战场使用环境的特殊性,环境噪声成为军事命令语音识别技术实用化的一个主要障碍。
6、这就是我们不能拥有无故障语音识别电脑的原因。
7、语音识别使客户关系管理简单起来。
8、语音识别系统利用神经网络完成的源代码,已经过测试.
9、如果无线连接的话,比如说,一个听障人士使用带语音识别软件的智能手机的隐形眼镜,就可以看说话者的语言转化成的字幕。
、语音端点检测的精确度直接影响语音识别的准确度.
、语音识别技术应用于汽车,可以使驾驶员用语音指令操纵车载设备,提高汽车驾驶的安全性和舒适性。
、而且,近几年来,易语言 源码 pdf音频处理技术发展迅速,语音识别技术已趋于成熟,对于大词汇量连续语音识别率很高。
、智能发报系统的核心部分是语音识别技术.
、提高汉语浊音基频实时提取精度是语音识别的关键技术之一。
、HTK主要用于语音识别研究,也用于语音合成、字符识别和DNA排列等研究。
、词边界检测误差是语音识别中产生错误的主要原因之一。
、新模型使语音识别率得到了改善。
、实验结果表明相似概率的引入有利于进一步提高语音识别率,同时发现大小为个码字的码本是不必要的。
、声纹识别是语音识别的一种,根据测试语音来辨别说话者的身份。
、语音识别技术经过半个世纪的发展,目前已日趋成熟,其在语音拨号系统、数字遥控、工业控制等领域都有了广泛的应用。
、声纹识别是语音识别的一种,它根据测试语音来辨别说话者的身份。
、除了可以口述文本,你也可以用语音识别去操作电脑甚至是浏览英特网。
、辅助功能助手的示例包括屏幕阅读程序、语音识别系统和屏幕键盘。
、它有一个语音识别系统,语音拨号,并开放申请。
、视频上传系统源码为减少语音识别中声学模型的参数量,提高参数训练的鲁棒性,提出了一种基于升值法模糊聚类的异音混合共享模型。
、可以推广到语音识别、环境噪声监测和实验室测量等多种领域,应用前景广阔。
、语音识别部分由软件编程实现,通过串行口编程进行通信,控制单片机,它成功实现控制发光二极管和语音播放的目的。
、本文首先对语音指令识别系统作了整体介绍,介绍了个部分的主要功能,并简要比较了语音识别的基本方法。
、在语音识别中,为了得到分布共享的异音模型,先要知道与发音语境无关的音素模型。
、该专题一般由学生和教课人员共同商定,通常是选择一个学生感兴趣的方向,创建并测评一个语音识别系统。
、其中语音识别包含两个方向:声纹识别和语音内容识别。
、支持语音输入和声音命令。要使用语音识别功能,您需要安装微软拼音输入法。
、由于您的系统不支持,所选语言中的语音识别无法初始化。请安装相关的语言包,再试一次。
、相比之下,文本处理的硬件要求微不足道,并且可以在同一台计算机上运行,而不会影响语音识别处理的性能。
、大词表连续语音识别系统由多个组件构成,识别错误受多种因素的影响。
、文中阐述了语音合成与语音识别技术、语音处理系统,以及语音处理器在电子测量领域的应用。
、用自然语言理解方法研究语音识别后文本的检错纠错,将是提高语音识别性能的一个重要研究方向。
、说话人识别技术是语音识别技术的一种,共分为说话人确认和说话人辨认两种。
、维吾尔语是黏着性语言,利用丰富的词缀可以用同样的词干产生超大词汇,给维吾尔语语音识别的研究工作带来了很大困难。
、有了更高精度,语音识别技术更广泛地结合进最终用户的应用程序已为期不远了.
、要使用语音识别功能,您需要安装微软拼音输入法。
、科大讯飞语音识别系统,其原理是将文本文字转成*声语音朗读的TTS语音库,在中文语音识别上,是目前世界上最好的、最逼真的。
、谢志健抱着姑且一试的心态对着手机语音识别系统说“爸爸”,手机竟真的拨出联系上了当事人的父亲,辗转通知到正在外面找手机的失主陈姓医生。
、而国内的不少互联网信息企业如百度,腾讯,搜狐的搜狗拼音,安科大的讯飞科技等也先后搞过语音识别系统,开发过相应的语音输入软件。
、海量文本语料做基础,同时对文本库进行实时更新,提升语音识别的效率和质量。
唇语识别源代码
唇语识别源代码的实现是一个相对复杂的过程,它涉及到计算机视觉、深度学习和自然语言处理等多个领域。下面我将详细解释唇语识别源代码的关键组成部分及其工作原理。 核心技术与模型 唇语识别的核心技术在于从视频中提取出说话者的口型变化,并将其映射到相应的文字或音素上。这通常通过深度学习模型来实现,如卷积神经网络(CNN)用于提取口型特征,循环神经网络(RNN)或Transformer模型用于处理时序信息并生成文本输出。这些模型需要大量的标记数据进行训练,以学习从口型到文本的映射关系。 数据预处理与特征提取 在源代码中,数据预处理是一个关键步骤。它包括对输入视频的预处理,如裁剪口型区域、归一化尺寸和颜色等,以减少背景和其他因素的干扰。接下来,通过特征提取技术,如使用CNN来捕捉口型的形状、纹理和动态变化,将这些特征转换为模型可以理解的数值形式。 模型训练与优化 模型训练是唇语识别源代码中的另一重要环节。通过使用大量的唇语视频和对应的文本数据,模型能够学习如何根据口型变化预测出正确的文本。训练过程中,需要选择合适的损失函数和优化算法,以确保模型能够准确、高效地学习。此外,为了防止过拟合,还可以采用正则化技术,如dropout和权重衰减。 推理与后处理 在模型训练完成后,就可以将其用于实际的唇语识别任务中。推理阶段包括接收新的唇语视频输入,通过模型生成对应的文本预测。为了提高识别的准确性,还可以进行后处理操作,如使用语言模型对生成的文本进行校正,或者结合音频信息(如果可用)来进一步提升识别效果。 总的来说,唇语识别源代码的实现是一个多步骤、跨学科的工程,它要求深入理解计算机视觉、深度学习和自然语言处理等领域的知识。通过精心设计和优化各个环节,我们可以开发出高效、准确的唇语识别系统,为语音识别在噪音环境或静音场景下的应用提供有力支持。ASRT:一个中文语音识别系统
ASRT是AI柠檬博主开发的中文语音识别系统,基于深度学习,采用CNN和CTC方法训练,具有高准确率。系统包含声学模型、语言模型,提供基于ASRT的语音识别应用软件,支持Windows UWP和.Net平台。深度学习在语音识别领域的影响深远,ASRT采用深层全卷积神经网络,结合VGG网络配置,实现端到端训练,将语音波形转录为中文拼音,再通过最大熵隐含马尔可夫模型转换为文本。项目使用Python的HTTP协议基础服务器包,提供网络HTTP协议的语音识别API。系统流程包括特征提取、声学模型、CTC解码和语言模型,基于HTTP协议的API接口支持语音识别功能。客户端分为UWP和WPF两种,通过自动控制录音和异步请求实现长时间连续语音识别。未来,ASRT将加入说话人识别系统,实现AI实际应用中的“认主”行为。项目源码在GitHub上开源。
Kaldi(1): 安装
Kaldi是一个基于C++开发并遵循Apache License v2.0的语音识别工具包,它目前是ASR领域最受欢迎的工具之一。本文将基于Ubuntu . LTS系统,向您介绍Kaldi的安装方法。
安装Kaldi的第一步是按照官网提供的kaldi-asr.org/doc/tutor...指南,将Kaldi项目克隆至本地。
在克隆完项目后,进入kaldi-trunk目录,查看INSTALL文件的内容。
根据INSTALL文件的内容,我们需要先进入tools目录,并按照提示进行安装。完成tools目录的安装后,再进入src目录,继续按照提示进行安装。
在进入tools目录后,我们需要查看INSTALL文件的内容。根据文件内容,我们首先需要进入extras目录,并运行脚本check_dependencies.sh来检查各种依赖是否安装。
进入extras目录并运行check_dependencies.sh脚本。
运行check_dependencies.sh脚本后,如果出现任何提示表明某些库未安装,应按照提示解决,直到运行check_dependencies.sh后出现“All OK.”的提示。
然后,返回上一级目录,进行编译。如果是在虚拟机上,建议使用make而非make -j 4,以避免因内存不足导致编译失败。在src目录下的编译也遵循同样的原则。
编译完成后,可能会提示irstlm未安装。此时,可以运行extras/install_irstlm.sh安装irstlm,但即使没有安装也可以先继续完成整个Kaldi的安装。
进入src目录,查看INSTALL文件的内容。
运行configure --shared命令。
运行configure命令后,务必仔细阅读显示的提示,它可能和上文所示的内容有所区别。提示中会提醒你有哪些东西没安装好,并给出指导。遵循这些指导完成相关依赖的安装,直到运行configure后出现如上文所示的提示,提示的最后显示“SUCCESS To compile: ……”,此时才能进行后面的步骤。
执行最后的步骤,编译Kaldi的源码。编译过程可能需要半个小时到一个小时,如果编译过程中未出现红色的error,最后出现“Done”,表明编译成功。
最后,运行一个例程来检验安装是否成功。运行egs/yesno/s5目录下的run.sh脚本。
如果出现如上文所示的结果,表明Kaldi安装成功。
我把中文识别能力最好的开源ASR模型封装为API服务了
当我沉醉于优质的播客内容,总是渴望将其文字版记录下来便于学习,但市面上的大多数语音识别(ASR)服务要么是封闭源代码,要么收费高昂。这启发了我一个想法:为何不亲手打造一个开源且易用的ASR API?现在,我荣幸地分享,我已经将性能卓越的中文识别开源ASR模型封装成了API服务。
面对开发者和小型企业可能面临的成本问题,以及对定制开发和研究的限制,我选择开发一个开源解决方案。它的目标是为所有人提供一个强大、友好且价格亲民的语音转文字工具。
使用起来极其简便:首先,确保你安装了必要的Python库,然后运行app.py即可。服务在0.0.0.0的端口运行。如果你偏爱Docker,我提供了相应的镜像和部署指南,让部署变得轻而易举。
为了提升用户体验,我还在研发一个简洁的前端界面,尽管它尚在发展中,但未来将逐步完善。一旦完成,我将同步分享给大家,敬请期待。
我开源这个项目,旨在让更多人受益于中文语音识别技术的普及。相信有了这个开源API,这个领域将得到更广泛的推动和创新。