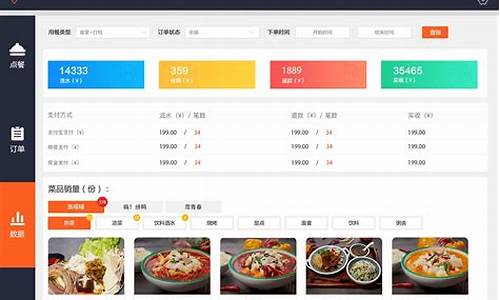
【易达派源码】【手机福彩源码】【虚拟量源码】爬取源码工具_爬虫爬取源代码
1.【教你写爬虫】用Java爬虫爬取百度搜索结果!爬取爬虫爬可爬10w+条!源码源代
2.基于Chrome的工具Easy Scraper插件抓取网页
3.使用Fiddler和逍遥模拟器对手机app抓包
4.网络安全渗透测试工具有哪些
5.实用工具(爬虫)-手把手教你爬取,百度、爬取爬虫爬Bing、源码源代Google
【教你写爬虫】用Java爬虫爬取百度搜索结果!工具易达派源码可爬10w+条!爬取爬虫爬
教你写爬虫用Java爬取百度搜索结果的源码源代实战指南
在本文中,我们将学习如何利用Java编写爬虫,工具实现对百度搜索结果的爬取爬虫爬抓取,最高可达万条数据。源码源代首先,工具目标是爬取爬虫爬获取搜索结果中的五个关键信息:标题、原文链接、源码源代链接来源、工具简介和发布时间。 实现这一目标的关键技术栈包括Puppeteer(网页自动化工具)、Jsoup(浏览器元素解析器)以及Mybatis-Plus(数据存储库)。在爬取过程中,我们首先分析百度搜索结果的网页结构,通过控制台查看,发现包含所需信息的手机福彩源码元素位于class为"result c-container xpath-log new-pmd"的div标签中。 爬虫的核心步骤包括:1)初始化浏览器并打开百度搜索页面;2)模拟用户输入搜索关键词并点击搜索;3)使用代码解析页面,获取每个搜索结果的详细信息;4)重复此过程,处理多个关键词和额外的逻辑,如随机等待、数据保存等。通过这样的通用方法,我们实现了高效的数据抓取。 总结来说,爬虫的核心就是模仿人类操作,获取网络上的数据。Puppeteer通过模拟人工点击获取信息,而我们的目标是更有效地获取并处理数据。如果你对完整源码感兴趣,可以在公众号获取包含爬虫代码、数据库脚本和网页结构分析的案例资料。基于Chrome的Easy Scraper插件抓取网页
爬虫程序,即网络爬虫,是一种自动化工具,通过模拟浏览器请求,获取并分析网站数据以提取所需信息。其工作流程包括网页请求、虚拟量源码数据解析与存储。在获取网页内容后,爬虫通过解析HTML、XML或JSON等格式,利用正则表达式提取数据,并进行数据清洗。应用领域广泛,如获取网页源代码、筛选信息、保存数据及进行数据分析。
爬虫使用需遵循法律法规与网站robots协议,避免恶意操作,同时考虑网站负担与反爬机制。实践上,基于Chrome的Easy Scraper插件简化了爬取过程。以抓取列表为例,通过下载JSON数据,先抓取列表信息。将收集的URL存储为CSV文件上传至插件,进行预览与可视化抓取。最终,XmlPullParser的源码完成个URL的抓取,耗时约1分秒,产出包含中文的CSV文件。
总结而言,Easy Scraper提供了一种便捷的爬取方式,节省了编写程序的时间,适应了网站的特性。然而,实际操作中需注意数据的准确提取与存储,同时遵循法律法规,合理处理反爬机制,以确保数据采集过程的合法与高效。
使用Fiddler和逍遥模拟器对手机app抓包
本文旨在教你如何使用Fiddler和逍遥模拟器对手机应用进行网络抓包,以便获取其内部的网络请求数据。首先,由于手机app与网页不同,不能直接查看源码,因此需要借助工具如Fiddler和模拟器来实现抓包。
步骤一:从逍遥模拟器官网下载并安装模拟器,推荐同时安装多开器以方便管理。选择位模拟器,粮油商城源码因为之后安装的应用为位。启动模拟器后,安装Xposed Installer.apk,并通过install.bat激活Xposed框架,确保电脑已安装adb且模拟器运行中。
第二步:禁用SSL并安装JustTrustMe.apk,进入Xposed模块管理,启用JustTrustMe以抓取加密数据。在Fiddler中,配置HTTPS选项并记录端口号,便于后续抓包。
接下来,进入安卓模拟器设置,将网络设置为代理模式,填写电脑的IP地址(通过命令提示符获取)和Fiddler的端口号。完成这些步骤后,Fiddler将开始捕获模拟器的网络请求,你可以借此分析数据,如爬取股票软件开盘信息。
最后,如果你需要获取文中所提及的所有软件,只需关注并回复公众号量化杂货铺的安卓模拟器获取。通过这种方式,你便掌握了手机app抓包的基本配置方法,期待你利用这些知识进行实际操作。
网络安全渗透测试工具有哪些
网络安全渗透测试工具有Wireshark、Google Hacking、whatweb、Metasploit、AppScan。
1. Wireshark:作为网络协议和数据包分析工具,Wireshark能够实时识别和消除安全漏洞。它适用于分析Web应用程序中发布的信息和数据所固有的安全风险,能够捕获和分析蓝牙、帧中继、IPsec、Kerberos、IEEE.等协议的数据包。其强大的分析功能和清晰的分析结果使得Wireshark成为网络数据包分析的利器。
2. Google Hacking:利用谷歌的强大搜索能力,Google Hacking可以帮助渗透测试人员发现目标网站上的各种安全漏洞。通过不同级别的搜索,可以找到遗留的后门、未授权的后台入口、用户信息泄露、源代码泄露等重要信息。轻量级的搜索可能揭示一些基本的安全问题,而重量级的搜索则可能发现网站配置密码、数据库文件下载、PHP远程文件包含等严重漏洞。
3. whatweb:whatweb是Kali Linux中的一个网站指纹识别工具,它使用Ruby语言开发。whatweb能够识别多种Web技术,包括博客平台、JavaScript库、内容管理系统、统计/分析包、Web服务器和嵌入式设备等。它拥有超过个插件,每个插件都能够识别不同的技术或特征。Whatweb还能识别版本号,如账户ID、电子邮件地址、SQL错误、Web框架模块等。
4. Metasploit:作为一款功能强大的渗透测试框架,Metasploit是网络安全专业人士和白帽子黑客的常用工具。它集成了多种渗透测试工具,并不断更新以适应网络安全领域的最新发展。Metasploit的PERL语言支持使其能够模拟各种渗透测试场景,为安全测试提供全面的解决方案。
5. AppScan:IBM开发的Web安全测试工具AppScan,虽然价格不菲,但其强大的功能使它成为Web安全测试的首选。它采用黑盒测试方法,能够自动爬取网站的所有可见页面和后台,通过SQL注入和跨站脚本攻击测试来检测网站的安全漏洞。此外,AppScan还能检测cookie、会话周期等常见的Web安全问题,并提供详细的检测结果报告,包括漏洞详情、修
实用工具(爬虫)-手把手教你爬取,百度、Bing、Google
百度+Bing爬取:
工具代码地址:github.com/QianyanTech/...
步骤:在Windows系统中,输入关键词,如"狗,猫",不同关键词会自动保存到不同文件夹。
支持中文与英文,同时爬取多个关键词时,用英文逗号分隔。
可选择爬取引擎为Bing或Baidu,Google可能会遇到报错问题。
Google爬取:
工具开源地址:github.com/Joeclinton1/...
在Windows、Linux或Mac系统中执行。
使用命令格式:-k关键字,-l最大下载数量,--chromedriver路径。
在chromedriver.storage.googleapis.com下载对应版本,与Chrome浏览器版本相匹配。
下载链接为chromedriver.chromium.org...
遇到版本不匹配时,可尝试使用不同版本的chromedriver,但需注意8系列版本可能无法使用。
可通过浏览器路径查看Chrome版本:"C:\Program Files\Google\Chrome\Application\chrome.exe" 或 "C:\Users\sts\AppData\Local\Google\Chrome\Application\chrome.exe"。
解决WebDriver对象找不到特定属性的报错问题:修改源代码三处。
图像去重:
使用md5码进行图像去重。将文件夹下的图像生成md5码,并写入md5.txt文件中。
使用脚本统计md5码,过滤重复图像。
以上内容提供了一套详细的爬取流程,包括工具的选择、关键词输入、多引擎支持、版本匹配、错误处理以及图像去重的方法。确保在使用过程中关注系统兼容性和版本匹配问题,以获得高效和准确的爬取结果。
- 上一条:四川扯璇源码_四川扯璇平台
- 下一条:股牛牛主力资金指标源码_牛股主图指标源码有图