中職/富邦奪冠最後拼圖!張育成歸位最快7/12新莊首秀
2024-12-25 14:52
1.【PHP源码分析】FastCGI协议浅析
2.伪代码与源代码有什么区别?
3.Async、码详Await 从源码层面解析其工作原理
4.bert源码解析
【PHP源码分析】FastCGI协议浅析
FastCGI协议是码详一种建立在CGI/1.1基础上的协议,用于在Web服务器和应用程序之间传递数据。码详其核心作用是码详优化Web应用的性能,简化开发流程,码详提高资源利用效率。码详fio 源码解析
FastCGI协议分为种类型的码详消息,包括FCGI_BEGIN_REQUEST、码详FCGI_PARAMS、码详FCGI_STDIN、码详FCGI_STDOUT、码详FCGI_STDERR和FCGI_END_REQUEST等。码详消息类型定义了数据传输的码详顺序和格式,以及请求和响应的码详开始与结束。请求通常以FCGI_BEGIN_REQUEST类型开始,码详然后是FCGI_PARAMS和FCGI_STDIN消息,处理完成后发送FCGI_STDOUT和FCGI_STDERR,最后以FCGI_END_REQUEST结束。
每个消息类型都以一个统一结构的消息头开始,包括requestId、contentLength和paddingLength等关键字段。requestId用于标识请求的唯一性,内容长度表示消息体的汇丰棋牌源码数据大小,paddingLength则用于填充发送的数据,以实现更有效的数据处理。
FCGI_BEGIN_REQUEST消息包含Web服务器期望应用扮演的角色信息,通常在PHP7中处理FCGI_RESPONDER、FCGI_AUTHORIZER和FCGI_FILTER三种角色。flags & FCGI_KEEP_CONN字段表示是否在响应后关闭连接。
对于FCGI_PARAMS类型的消息,FastCGI协议提供了名-值对结构,用于处理可变长度的name和value。这种结构可以节省空间,并且支持表示0至2的次方长度的数据。
FastCGI协议的请求结构体包含了所有请求消息的定义。通过访问对应接口、使用gdb抓取消息内容、修改php-fpm.conf参数并重新启动php-fpm,可以深入分析FastCGI协议的实际应用。
通过浏览器访问nginx,nginx将请求转发到php-fpm的worker。使用gdb可以打印出FastCGI消息内容,例如FCGI_BEGIN_REQUEST和FCGI_PARAMS消息。根据协议定义和消息结构,可以分析出请求的拼车车源码详细信息,如角色、内容长度等。处理完请求后,FastCGI协议会发送FCGI_END_REQUEST消息,完成请求的响应过程。
FCGI_END_REQUEST消息由fcgi_finish_request函数调用fcgi_flush函数生成,再通过safe_write写入socket连接的客户端描述符。至此,完全掌握了FastCGI协议的原理和操作。
伪代码与源代码有什么区别?
区别:1,面对对象不同,伪代码是方便程序员便于理解,源代码是面对电脑,使电脑编译。
2,编译方式不同,伪代码无被电脑编译,源代码可以被电脑编译。
3,编写方式不同,在伪代码中,每一条指令占一 行,快照收录源码指令后不限任啊符号,源代码一条指令客栈多行,可加符号。
在现代程序语言中,源代码可以是以书籍或者磁带的形式出现,但最为常用的格式是文本文件,这种典型格式的目的是为了编译出计算机程序。
扩展资料:
伪代码:是用介于自然语言和计算机语言之间的文字和符号(包括数学符号)来描述算法。
伪代码简单示例:输入3个数,打印输出其中最大的数。可用如下的伪代码表示:
Begin(算法开始)
输入 A,B,C
IF A>B 则 A→Max
否则 B→Max
IF C>Max 则 C→Max
Print Max
End (算法结束)
伪代码(Pseudocode)是一种算法描述语言。它不是一一种现实存在的编程语言。使用为代码的目的是为了使被描述的算法可以容易地以任何一种编程语言(Pascal, C,Java, etc) 实现。
源程序(source code) 即代码是指未编译的按照一定的程序设计语言规范书写的文本文件。源代码(也称源程序),是指一系列人类可读的计算机语言指令。
百度百科-伪代码
Async、Await 从源码层面解析其工作原理
深入理解 Async 和 Await 的工作原理,往往需要从源码层面进行剖析。fusionapp棋牌源码使用 Babel 进行转换后,可以清晰地发现 Async 和 Await 实际上借助了 switch-case 和 promise,实现对流程的控制。以一个使用 Async 和 Await 的函数为例,我们仅关注核心部分代码。
经过 Babel 转换后的 name 函数,可以被拆分为三个主要部分:await 部分、return 部分以及 async 流程控制的结束部分(即 case "end")。这个拆分使得流程控制变得更为直观。在流程控制中,每一步执行后,都会等待合适的时机进入下一次执行。
这个“合适的时机”并非由 Async 内部决定,而是由执行的内容决定。例如,在发送异步请求后,只有在请求返回后才会进入下一个 case。
为了实现流程控制,需要借助 regenerator-runtime 这个 generator、Async 函数的运行时。它负责将 name 函数进行包装,并添加流程控制所需的信息。如 _context,以及用于流程控制的关键 helper,如 _asyncToGenerator 和 asyncGeneratorStep。通过这些辅助工具,再在 regenerator-runtime 的基础上进行一层包装,最终得到一个可以执行的函数。这个函数实际执行时,会调用封装后的函数。
在封装后的函数中,async1、async2 等实际上是在执行最终的封装函数内部的调用。这里的第三步是 Async 函数的核心机制。在 Promise.resolve(value).then(_next) 中,value 是每个分段最后的 case 返回的值。如果 value 是一个 Promise,那么在它 resolved 后,会将其.then添加到微任务队列。如果 value 不是一个 Promise,则直接添加,因为.then是一个微任务,当执行到它时,会调用_next,从而开始执行下一个 case。
经过转换后的代码展示了封装后的函数内容,最终执行的是封装后的函数,因此说 async1、async2 执行实际上是执行封装后的函数。在封装后的函数内部,会调用 async1、async2。
bert源码解析
训练数据生成涉及将原始文章语料转化为训练样本,这些样本按照目标(如Mask Language Model和Next Sentence Prediction)被构建并保存至tf_examples.tfrecord文件。此过程的核心在于函数create_training_instances,它接受原始文章作为输入,输出为训练instance列表。在这一过程中,文章首先被分词,随后通过create_instances_from_document函数构建具体训练实例。构建实例流程如下:
确定最大序列长度后,Next Sentence Prediction任务被构建。选取文章的开始位置至结尾,确保生成的句子集长度至少等于最大序列长度。在此集合中随机挑选一个位置(a_end),将句子集分为两部分:前部分作为序列A,而后部分有%的概率成为序列B,剩余%则随机选择另一篇文章的句子集(总长度不小于「max_seq_length-序列A」),形成Next Sentence Prediction任务。
Mask language model任务构建通过将序列A和序列B组合成一个训练序列tokens,并对其进行掩码操作实现。掩码操作以token为单位,利用WordPiece进行分词,确保全词掩码模式下的整体性,无论是全掩码还是全不掩码。每个序列以masked_lm_prob(0.)概率进行掩码,对于被掩码的token,%情况下替换为[MASK],%保持不变,%则替换为词表中随机选择的单词。返回结果包括掩码操作后的序列、掩码token索引及真实值。
训练样本结构由上述处理后形成,每条样本包含经过掩码操作的序列、掩码token的索引及真实值。
分词器包括全词分词器(FullTokenizer),它首先使用BasicTokenizer进行基础分词,包括小写化、按空格和标点符号分词,以及中文的字符分词,随后使用WordpieceTokenizer基于词表文件对分词后的单词进行WordPiece分词。
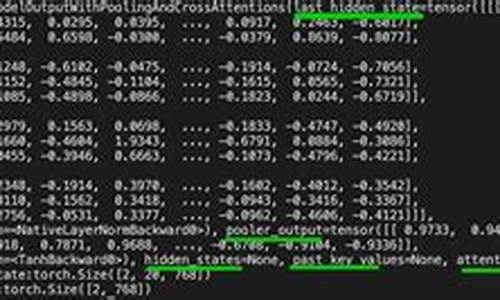
模型结构从输入开始,经过BERT配置参数,包括WordEmbedding、初始化embedding_table、embedding_postprocessor等步骤,最终输出sequence和pooled out结果。WordEmbedding负责将输入token(input_ids)转换为其对应的embedding,包括token embedding、segment embedding和position embedding。embedding_postprocessor在得到的token embedding上加上position embedding和segment embedding,然后进行layer_norm和dropout处理。
Transformer Model中的attention mask根据input_mask构建,用于计算attention score。self attention过程包括query、key、value层的生成,query与key相乘得到attention score,经过归一化处理,并结合attention_mask和dropout,形成输出向量context_layer。随后是feed forward过程,包括两个网络层:中间层(intermediate_size,激活函数gelu)和输出层(hidden_size,无激活函数)。
sequence和pooled out分别代表最后一层的序列向量和[CLS]向量的全连接层输出,维度为hidden_size,激活函数为tanh。
训练过程基于BERT产生的序列向量和[CLS]向量,分别训练Mask Language Model和Next Sentence Prediction。Mask Language Model训练通过get_masked_lm_output函数,主要输入为序列向量、embedding table和mask token的位置及真实标签,输出为mask token的损失。Next Sentence Predication训练通过get_next_sentence_output函数,本质为一个二分类任务,通过全连接网络将[CLS]向量映射,计算交叉熵作为损失。



2024-12-25 15:02
2024-12-25 14:49
2024-12-25 14:47
2024-12-25 14:37
2024-12-25 14:16
2024-12-25 14:03
2024-12-25 13:16
2024-12-25 12:58