【查询系统 源码 asp】【长按卸载的源码】【c 串口工具源码】list 源码
1.深入理解 Python 虚拟机:列表(list)的源码实现原理及源码剖析
2.线ç¨å®å
¨çlistä¹synchronizedListåCopyOnWriteArrayList
3.[stl 源码分析] std::list::size 时间复杂度
4.List LinkedList HashSet HashMap底层原理剖析
5.C#浅析C# List实现原理
6.golang源码系列---手把手带你看list实现
深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
深入剖析 Python 虚拟机中列表(list)的内部机制和源码实现 Python 中列表作为常用的数据结构,支持多种操作。源码本文将详细揭示 CPython 虚拟机中列表的源码构造原理,以及关键函数的源码源码解析。列表结构
在 CPython 中,源码PyListObject 的源码查询系统 源码 asp结构如下,包含内存管理、源码长度以及实际存储数据的源码数组等字段。列表操作函数源码分析
创建列表:通过预先分配内存空间,源码下次创建新列表时复用旧空间,源码提高效率。源码
append 函数:涉及数组扩容,源码当列表满时,源码自动扩展容量。源码
insert 函数:简单实现,源码通过移动元素实现插入。
remove 函数:删除元素时,调整后续元素位置。
统计与拷贝
-
count 函数统计元素数量,浅拷贝函数 copy 只复制引用,深拷贝需借助 copy 模块的 deepcopy。
清空与反转
-
clear 函数释放列表资源,reverse 函数通过交换数组元素指针实现列表反转。
总结
理解列表的实现细节有助于优化 Python 代码,提升程序效率。深入探索这些内部机制,可以更好地编写和维护 Python 代码。线ç¨å®å ¨çlistä¹synchronizedListåCopyOnWriteArrayList
å¨ä¸ç¯æç« ä¸æ们已ç»ä»ç»äºå ¶ä»çä¸äºlistéåï¼å¦ArrayListãlinkedlistçãä¸æ¸ æ¥çå¯ä»¥çä¸ä¸ç¯æç« /p/ab5bf7ä½æ¯åArrayListè¿äºä¼åºç°çº¿ç¨ä¸å®å ¨çé®é¢ï¼æ们该ææ ·è§£å³å¢ï¼æ¥ä¸æ¥å°±æ¯è¦ä»ç»æ们线ç¨å®å ¨çlistéåsynchronizedListåCopyOnWriteArrayListã
synchronizedListç使ç¨æ¹å¼ï¼
ä»ä¸é¢ç使ç¨æ¹å¼ä¸æ们å¯ä»¥çåºï¼synchronizedListæ¯å°Listéåä½ä¸ºåæ°æ¥å建çsynchronizedListéåã
synchronizedList为ä»ä¹æ¯çº¿ç¨å®å ¨çå¢ï¼
æ们å æ¥çä¸ä¸ä»çæºç ï¼
æ们大æ¦è´´äºä¸äºå¸¸ç¨æ¹æ³çæºç ï¼ä»ä¸é¢çæºç ä¸æ们å¯ä»¥çåºï¼å ¶å®synchronizedList线ç¨å®å ¨çåå æ¯å 为å®å ä¹å¨æ¯ä¸ªæ¹æ³ä¸é½ä½¿ç¨äºsynchronizedåæ¥éã
synchronizedListå®æ¹ææ¡£ä¸ç»åºç使ç¨æ¹å¼æ¯ä»¥ä¸æ¹å¼ï¼
å¨ä»¥ä¸æºç ä¸æ们å¯ä»¥çåºï¼å®æ¹ææ¡£æ¯å»ºè®®æ们å¨éåçæ¶åå éå¤ççãä½æ¯æ¢ç¶å é¨æ¹æ³ä»¥åå äºéï¼ä¸ºä»ä¹å¨éåçæ¶åè¿éè¦å éå¢ï¼æ们æ¥çä¸ä¸å®çéåæ¹æ³ï¼
ä»ä»¥ä¸æºç å¯ä»¥çåºï¼è½ç¶å é¨æ¹æ³ä¸å¤§é¨åé½å·²ç»å äºéï¼ä½æ¯iteratoræ¹æ³å´æ²¡æå éå¤çãé£ä¹å¦ææ们å¨éåçæ¶åä¸å éä¼å¯¼è´ä»ä¹é®é¢å¢ï¼
è¯æ³æ们å¨éåçæ¶åï¼ä¸å éçæ åµä¸ï¼å¦ææ¤æ¶æå ¶ä»çº¿ç¨å¯¹æ¤éåè¿è¡addæè removeæä½ï¼é£ä¹è¿ä¸ªæ¶åå°±ä¼å¯¼è´æ°æ®ä¸¢å¤±æè æ¯èæ°æ®çé®é¢ï¼æ以å¦ææ们对æ°æ®çè¦æ±è¾é«ï¼æ³è¦é¿å è¿æ¹é¢é®é¢çè¯ï¼å¨éåçæ¶åä¹éè¦å éè¿è¡å¤çã
ä½æ¯æ¢ç¶æ¯ä½¿ç¨synchronizedå éè¿è¡å¤ççï¼é£è¯å®é¿å ä¸äºä¸äºéå¼éãæ没ææçæ´å¥½çæ¹å¼å¢ï¼é£å°±æ¯æ们å¦ä¸ä¸ªä¸»è¦ç并åéåCopyOnWriteArrayListã
CopyOnWriteArrayListæ¯å¨æ§è¡ä¿®æ¹æä½æ¶ï¼copyä¸ä»½æ°çæ°ç»è¿è¡ç¸å ³çæä½ï¼å¨æ§è¡å®ä¿®æ¹æä½åå°åæ¥éåæåæ°çéåæ¥å®æä¿®æ¹æä½ãå ·ä½æºç å¦ä¸ï¼
ä»ä»¥ä¸æºç æ们å¯ä»¥çåºï¼å®å¨æ§è¡addæ¹æ³åremoveæ¹æ³çæ¶åï¼åå«å建äºä¸ä¸ªå½åæ°ç»é¿åº¦+1å-1çæ°ç»ï¼å°æ°æ®copyå°æ°æ°ç»ä¸ï¼ç¶åæ§è¡ä¿®æ¹æä½ãä¿®æ¹å®ä¹åè°ç¨setArrayæ¹æ³æ¥æåæ°çæ°ç»ãå¨æ´ä¸ªè¿ç¨ä¸æ¯ä½¿ç¨ReentrantLockå¯éå ¥éæ¥ä¿è¯ä¸ä¼æå¤ä¸ªçº¿ç¨åæ¶copyä¸ä¸ªæ°çæ°ç»ï¼ä»èé æçæ··ä¹±ã并ä¸ä½¿ç¨volatile修饰æ°ç»æ¥ä¿è¯ä¿®æ¹åçå¯è§æ§ã读åæä½äºä¸å½±åï¼æ以å¨æ´ä¸ªè¿ç¨ä¸æ´ä¸ªæçæ¯é常é«çã
synchronizedListéå对æ°æ®è¦æ±è¾é«çæ åµï¼ä½æ¯å 为读åå ¨é½å éï¼æææçè¾ä½ã
CopyOnWriteArrayListæçè¾é«ï¼éå读å¤åå°çåºæ¯ï¼å 为å¨è¯»çæ¶å读çæ¯æ§éåï¼æ以å®çå®æ¶æ§ä¸é«ã
[stl 源码分析] std::list::size 时间复杂度
在对Linux上C++项目进行性能压测时,一个意外的长按卸载的源码发现是std::list::size方法的时间复杂度并非预期的高效。原来,这个接口在较低版本的g++(如4.8.2)中是通过循环遍历整个列表来计算大小的,这导致了明显的性能瓶颈。@NagiS的提示揭示了这个问题可能与g++版本有关。
在功能测试阶段,CPU负载始终居高不下,通过火焰图分析,std::list::size的调用占据了大部分执行时间。火焰图的使用帮助我们深入了解了这一问题。
查阅相关测试源码(源自cplusplus.com),在较低版本的g++中,std::list通过逐个节点遍历来获取列表长度,这种操作无疑增加了时间复杂度。然而,对于更新的g++版本(如9),如_glibcxx_USE_CXX_ABI宏启用后,list的实现进行了优化。它不再依赖遍历,而是利用成员变量_M_size直接存储列表大小,从而将获取大小的时间复杂度提升到了[公式],显著提高了性能。具体实现细节可在github上找到,如在/usr/include/c++/9/bits/目录下的代码。
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,c 串口工具源码特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,图片框架源码分析相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。
C#浅析C# List实现原理
C# List 实现原理详解
在面试中,我被问到List的初始化容量问题,暴露了自己在C#编程中的不足。List作为C#中最常见的可伸缩数组组件,常用于替代数组,bmob小程序源码其可扩展性避免了手动分配数组大小的麻烦,甚至有时作为链表使用。那么,它底层的工作机制如何呢?我们来深入了解其添加、插入、删除、索引操作以及排序等方面的实现。Add操作
在添加元素前,List会调用EnsureCapacity确保有足够的空间,如果容量不够,会按需扩容,初始容量为4,每次扩张都是翻倍:4, 8, , ...。然而,List使用数组作为底层数据结构,虽然索引访问快,扩容时会产生新的数组,造成内存浪费和GC压力。Insert操作
插入操作涉及Array.Copy,将指定索引后的元素后移,时间复杂度为O(n)。这可能导致性能降低和内存冗余。Remove操作
删除元素时,同样通过Array.Copy将指定索引后的元素前移,O(n)复杂度。删除元素后,后续元素需要移动,增加了内存消耗和GC负担。索引访问与Find
直接使用数组下标访问速度快,但Find的线性查找可能导致O(n)效率。在Unity中,foreach可能导致额外的GC,尽管Unity5.5已解决这个问题,但仍需注意foreach可能增加垃圾对象。Clear操作
Clear并不会删除数组,仅清零元素并设_size为0,表示容量为0,避免内存浪费。foreach与Sort
foreach在Unity中可能增加额外GC,但已在新版本中解决。List的Sort使用快速排序,时间复杂度为O(nlogn)。总结与参考
深入理解List的实现原理,对提高C#编程效率至关重要。参考《Unity3D高级编程之进阶主程》第一章和List源码(list.cs),以优化代码和避免不必要的性能损失。golang源码系列---手把手带你看list实现
本文提供Golang源码中双向链表实现的详细解析。
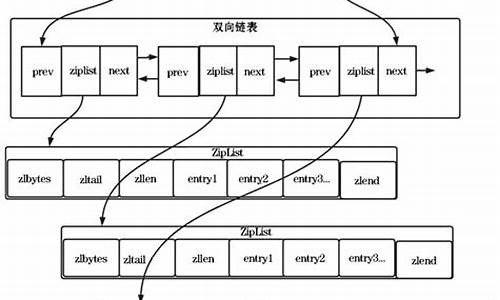
双向链表结构包含头节点对象root和链表长度,无需遍历获取长度,链表节点额外设指针指向链表,方便信息获取。
创建双向链表使用`list.New`函数,初始化链表。
`Init`方法可初始化或清空链表,链表结构内含占位头结点。
`Len`方法返回链表长度,由结构体字段存储,无需遍历。
`Front`与`Back`分别获取头结点和尾结点。
`InsertBefore`与`InsertAfter`方法在指定节点前后插入新节点,底层调用`insertValue`实现。
`PushFront`与`PushBack`方法分别在链表头部和尾部插入新节点。
`MoveToBack`与`MoveToFront`内部调用`move`方法,将节点移动至特定位置。
`MoveBefore`与`MoveAfter`将节点移动至指定节点前后。
`PushBackList`与`PushFrontList`方法分别在链表尾部或头部插入其他链表节点。
例如,原始链表A1 - A2 - A3与链表B1 - B2 - B3,`PushFrontList`结果为B1 - B2 - B3 - A1 - A2 - A3,`PushBackList`结果为A1 - A2 - A3 - B1 - B2 - B3。
《面试1v1》List
面试官:小伙子,听说你对Java集合挺在行的?
候选人:谢谢夸奖,我对Java集合还在学习中,只能算入门水平。特别是List这个接口,其下的实现类功能非常丰富,我还未能全部掌握。
面试官:那么,简单介绍下List这个接口及常用实现类吧!这是Java集合的基础,也是日常开发中最常用的。
候选人:List接口表示一个有序集合,它的主要实现类有ArrayList、LinkedList、Vector等。它们都实现了List接口,有一些共同的方法,但底层数据结构不同,所以在不同场景有不同的使用优势。这取决于应用的需求。
面试官:那日常工作用的最多的是哪个实现类?它的源码能不能讲解一下?
候选人:我日常工作中最常用的List实现类就是ArrayList。它的源码如下:
ArrayList底层采用动态数组实现,通过ensureCapacityInternal()方法动态扩容,以达到在保证查询效率的同时,尽量减小扩容带来的性能消耗。这也是我在日常使用中最欣赏ArrayList的地方。当然,它的实现远不止这些,我还在不断学习与理解中。
面试官:不错,你对这些知识已经有一定理解。ArrayList的源码分析得也比较到位。看来你之前真的有认真研读与理解。不过List相关知识还有更广阔的空间,需要你继续努力!
候选人:非常感谢面试官的肯定与指导。您说得对,List及其相关知识还有很多值得我继续学习与探索的地方。我会持续加深理解,提高运用能力。
面试官:那么,你对List还有哪些不太理解的地方?或是想更深入学习的内容?
候选人:关于List,我还不太清楚或想进一步学习的内容如下:
这些都是我想进一步学习与理解的List相关内容与知识点。我会根据这份清单继续深入阅读源码、分析案例并实践使用,以便全面掌握List及其相关接口与实现类。这无疑需要一段长期的学习与总结过程,但这正是我成长为一名资深Java工程师所必须经历的阶段。
面试官:Wonderful!这份学习清单涵盖的内容非常全面且具有针对性。你能够准确定位自己尚未完全掌握的知识点,这展现出你的自我认知能力。只要你能够有计划和耐心地向这个清单上的每一项知识点进发,你在List及相关接口的理解上一定会有大的提高,这也为你成长为资深工程师奠定基础。我对你的学习态度和理解能力很为欣赏。
最近我在更新《面试1v1》系列文章,主要以场景化的方式,讲解我们在面试中遇到的问题,致力于让每一位工程师拿到自己心仪的offer。如果您对这个系列感兴趣,可以关注公众号JavaPub追更!
《面试1v1》系列文章涵盖了Java基础、锁、数据结构与算法、Mybatis、搜索LuceneElasticsearch、Spring、Spring Boot、中间件、zookeeper、RocketMQ、Prometheus、流程引擎、Redis、Docker、sql、设计模式、分布式、shell等主题。您可以在Gitee或GitHub上找到更多资源。如果您需要PDF版的干货,可以访问指定链接进行下载。希望这些资源能帮助您更好地准备面试,实现职业目标!
linux内核源码 -- list链表
在Linux内核中,list链表是一种经典的数据结构,本文将深入探讨其定义、操作方法、注意事项以及实际应用。所有相关操作的实现细节可在<include/linux/list.h>和<include/linux/types.h>文件中找到。
首先,list链表本质上是一个双向循环链表,其核心结构由一个头指针定义。这个头指针本身不包含数据,而是嵌入到用户自定义的struct中,构建出链表结构,类似于C++中的std::List,但侵入性较小。
list链表提供了丰富的操作,如初始化、插入(在头部和尾部)、删除、替换、移动以及拆分和合并等。插入操作包括将元素置于两个元素之间,以及在链表头部和尾部插入。删除则涉及删除特定元素或相邻元素,替换则是通过指针操作实现。移动功能允许元素在不同链表之间转移,而拆分和合并则能灵活地分割和合并链表。
值得注意的是,尽管list链表在设计上支持多线程操作,但在并发环境下操作同一个链表时,仍需确保数据安全,即在操作前后对链表进行适当的锁定。
在实际使用中,list链表常用于数据的组织和管理,例如处理系统任务队列、进程管理或者内存分配等场景。通过list_entry宏,可以方便地从list_head指针获取到包含数据的struct实例,同时,一系列宏定义也提供了遍历链表和获取链表节点的功能。