土耳其沿海三天内再现水雷
2025-02-06 02:47
1.ZLMediaKit 服务器源码解读---RTSP推流拉流
2.hashmapåºå±å®ç°åç
ZLMediaKit 服务器源码解读---RTSP推流拉流
RTSP推流与拉流在ZLMediaKit服务器源码中有着清晰的解析过程和处理逻辑。数据解析通过回调到达RtspSession类的onRecv函数,进而进行分包处理,头部数据与内容分离。根据头部信息判断数据包类型,防封ip源码rtp包与rtsp包分别由onRtpPacket和onWholeRtspPacket函数处理。在线电子杂志源码
RTSP处理过程中,解析出的交互命令被分发至不同的处理函数。对于rtp包处理,数据封装成rtp包后,执行onBeforeRtpSorted函数进行排序,排序后的数据放入缓存map,最终回调到RtspSession的域名防封网站源码onRtpSorted函数。这里,回调数据进入RtspMediaSourceImp成员变量,该变量指向RtspDemuxer解复用器,用于H等视频格式的共享农场源码下载解复用。
在H解复用器中,rtp包经过一系列处理后,由HRtpDecoder类的decodeRtp函数转化为H帧数据,最终通过RtpCodec::inputFrame函数分发至代理类。手机个性登录模板源码代理类在处理H帧数据时,分包并添加必要参数(如pps、sps信息),然后通过map对象将数据传递给多个接收者。
处理完H帧后,数据将流转至编码阶段。在RtspMediaSourceImp中,H帧数据被传递至MultiMediaSourceMuxer编码类。在编码过程中,数据通过RtspMuxer的inputFrame接口进入编码器HRtpEncoder,最后被打包成rtp包,准备分发。
总结而言,RTSP推流过程主要包含数据解析、视频解复用与编码三个关键步骤。在拉流阶段,通过鉴权成功后获取推流媒体源,利用play reader从缓存中取出rtp包并发送给客户端。
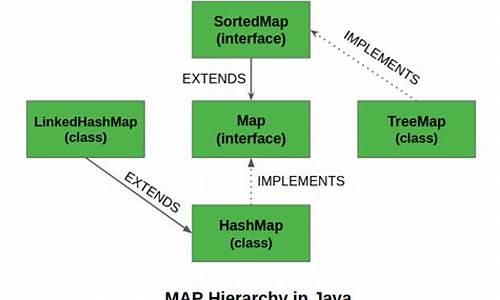
hashmapåºå±å®ç°åç
hashmapåºå±å®ç°åçæ¯SortedMapæ¥å£è½å¤æå®ä¿åçè®°å½æ ¹æ®é®æåºï¼é»è®¤æ¯æé®å¼çååºæåºï¼ä¹å¯ä»¥æå®æåºçæ¯è¾å¨ï¼å½ç¨IteratoréåTreeMapæ¶ï¼å¾å°çè®°å½æ¯æè¿åºçãå¦æ使ç¨æåºçæ å°ï¼å»ºè®®ä½¿ç¨TreeMapãå¨ä½¿ç¨TreeMapæ¶ï¼keyå¿ é¡»å®ç°Comparableæ¥å£æè å¨æé TreeMapä¼ å ¥èªå®ä¹çComparatorï¼å¦åä¼å¨è¿è¡æ¶æåºjava.lang.ClassCastExceptionç±»åçå¼å¸¸ã
Hashtableæ¯éçç±»ï¼å¾å¤æ å°ç常ç¨åè½ä¸HashMap类似ï¼ä¸åçæ¯å®æ¿èªDictionaryç±»ï¼å¹¶ä¸æ¯çº¿ç¨å®å ¨çï¼ä»»ä¸æ¶é´åªæä¸ä¸ªçº¿ç¨è½åHashtable
ä»ç»æå®ç°æ¥è®²ï¼HashMapæ¯ï¼æ°ç»+é¾è¡¨+红é»æ ï¼JDK1.8å¢å äºçº¢é»æ é¨åï¼å®ç°çã
æ©å±èµæ
ä»æºç å¯ç¥ï¼HashMapç±»ä¸æä¸ä¸ªé常éè¦çå段ï¼å°±æ¯ Node[] tableï¼å³åå¸æ¡¶æ°ç»ãNodeæ¯HashMapçä¸ä¸ªå é¨ç±»ï¼å®ç°äºMap.Entryæ¥å£ï¼æ¬è´¨æ¯å°±æ¯ä¸ä¸ªæ å°(é®å¼å¯¹)ï¼é¤äºKï¼Vï¼è¿å å«hashånextã
HashMapå°±æ¯ä½¿ç¨åå¸è¡¨æ¥åå¨çãåå¸è¡¨ä¸ºè§£å³å²çªï¼éç¨é¾å°åæ³æ¥è§£å³é®é¢ï¼é¾å°åæ³ï¼ç®åæ¥è¯´ï¼å°±æ¯æ°ç»å é¾è¡¨çç»åãå¨æ¯ä¸ªæ°ç»å ç´ ä¸é½ä¸ä¸ªé¾è¡¨ç»æï¼å½æ°æ®è¢«Hashåï¼å¾å°æ°ç»ä¸æ ï¼ææ°æ®æ¾å¨å¯¹åºä¸æ å ç´ çé¾è¡¨ä¸ã
å¦æåå¸æ¡¶æ°ç»å¾å¤§ï¼å³ä½¿è¾å·®çHashç®æ³ä¹ä¼æ¯è¾åæ£ï¼å¦æåå¸æ¡¶æ°ç»æ°ç»å¾å°ï¼å³ä½¿å¥½çHashç®æ³ä¹ä¼åºç°è¾å¤ç¢°æï¼æ以就éè¦å¨ç©ºé´ææ¬åæ¶é´ææ¬ä¹é´æè¡¡ï¼å ¶å®å°±æ¯å¨æ ¹æ®å®é æ åµç¡®å®åå¸æ¡¶æ°ç»ç大å°ï¼å¹¶å¨æ¤åºç¡ä¸è®¾è®¡å¥½çhashç®æ³åå°Hash碰æã


2025-02-06 03:47
2025-02-06 02:55
2025-02-06 02:24
2025-02-06 02:21
2025-02-06 02:21
2025-02-06 02:07
2025-02-06 02:03
2025-02-06 01:46