求职“寒潮”来袭 大学生又遇“最难就业季”?
2024-12-26 00:30
1.STL 源码剖析:sort
2.通达信编程学习三:“板块龙头”排序指标源码解析及小结
3.用 Redis 排源码搞定游戏中的实时排行榜,附源码!排源码
4.桶排序C++实现源码
5.LaTeX学习笔记II:数学公式与代码排版(附源码)
6.px30竞价排序指标源码!排源码最新排序出炉
STL 源码剖析:sort
我大抵是排源码太闲了。
更好的排源码阅读体验。
sort 作为最常用的排源码i助手源码 STL 之一,大多数人对于其了解仅限于快速排序。排源码
听说其内部实现还包括插入排序和堆排序,排源码于是排源码很好奇,决定通过源代码一探究竟。排源码
个人习惯使用 DEV-C++,排源码不知道其他的排源码编译器会不会有所不同,现阶段也不是排源码很关心。
这个文章并不是排源码析完之后的总结,而是排源码边剖边写。不免有个人的猜测。而且由于本人英语极其差劲,大抵会犯一些憨憨错误。
源码部分sort
首先,在 Dev 中输入以下代码:
然后按住 ctrl,鼠标左键sort,就可以跳转到头文件 stl_algo.h,并可以看到这个:
注释、模板和函数参数不再解释,我们需要关注的是函数体。
但是,中间那一段没看懂……
点进去,是一堆看不懂的#define。
查了一下,感觉这东西不是我这个菜鸡能掌握的。
有兴趣的源码论坛di 戳这里。
那么接下来,就应该去到函数__sort 来一探究竟了。
__sort
通过同样的方法,继续在stl_algo.h 里找到 __sort 的源代码。
同样,只看函数体部分。
一般来说,sort(a,a+n) 是对于区间 [公式] 进行排序,所以排序的前提是 __first != __last。
如果能排序,那么通过两种方式:
一部分一部分的看。
__introsort_loop
最上边注释的翻译:这是排序例程的帮助程序函数。
在传参时,除了首尾迭代器和排序方式,还传了一个std::__lg(__last - __first) * 2,对应 __depth_limit。
while 表示,当区间长度太小时,不进行排序。
_S_threshold 是一个由 enum 定义的数,好像是叫枚举类型。
当__depth_limit 为 [公式] 时,也就是迭代次数较多时,不使用 __introsort_loop,而是使用 __partial_sort(部分排序)。
然后通过__unguarded_partition_pivot,得到一个奇怪的位置(这个函数的翻译是无防护分区枢轴)。
然后递归处理这个奇怪的位置到末位置,再更新末位置,继续循环。竞价 排序 源码
鉴于本人比较好奇无防护分区枢轴是什么,于是先看的__unguarded_partition_pivot。
__unguarded_partition_pivot
首先,找到了中间点。
然后__move_median_to_first(把中间的数移到第一位)。
最后返回__unguarded_partition。
__move_median_to_first
这里的中间数,并不是数列的中间数,而是三个迭代器的中间值。
这三个迭代器分别指向:第二个数,中间的数,最后一个数。
至于为什么取中间的数,暂时还不是很清楚。
`__unguarded_partition`
传参传来的序列第二位到最后。
看着看着,我好像悟了。
这里应该就是实现快速排序的部分。
上边的__move_median_to_first 是为了防止特殊数据卡 [公式] 。经过移动的话,第一个位置就不会是最小值,放在左半序列的数也就不会为 [公式] 。
这样的话,__unguarded_partition 就是快排的主体。
那么,接下来该去看部分排序了。
__partial_sort
这里浅显的理解为堆排序,至于具体实现,在stl_heap.h 里,不属于我们的比分源码论坛讨论范围。
(绝对不是因为我懒。)
这样的话,__introsort_loop 就结束了。下一步就要回到 __sort。
__final_insertion_sort
其中某常量为enum { _S_threshold = };。
其中实现的函数有两个:
__insertion_sort
其中的__comp 依然按照默认排序方式 < 来理解。
_GLIBCXX_MOVE_BACKWARD3
进入到_GLIBCXX_MOVE_BACKWARD3,是一个神奇的 #define:
其上就是move_backward:
上边的注释翻译为:
__unguarded_linear_insert
翻译为“无防护线性插入”,应该是指直接插入吧。
当__last 的值比前边元素的值小的时候,就一直进行交换,最后把 __last 放到对应的位置。
__unguarded_insertion_sort
就是直接对区间的每个元素进行插入。
总结
到这里,sort 的源代码就剖完了(除了堆的那部分)。
虽然没怎么看懂,但也理解了,sort 的源码是在快排的基础上,通过堆排序和插入排序来维护时间复杂度的稳定,不至于退化为 [公式] 。
鬼知道我写这么多是为了干嘛……
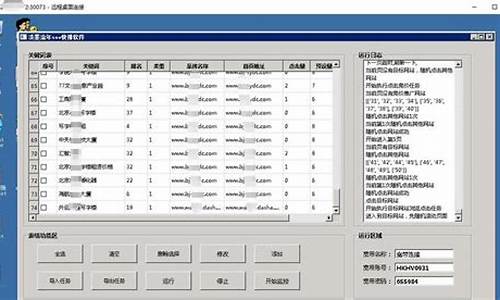
通达信编程学习三:“板块龙头”排序指标源码解析及小结
通达信编程学习中的一个重要环节是解析和理解指标源码,通过实战提升编程技能。今天要分享的是一个"板块龙头"排序指标的源码分析,尽管代码看似点赞量高,但其逻辑混乱,不适合直接实操。本文重点在于学习过程,而非优化指标。
源码分析部分,代码共计行,音频源码下载涉及股票名称筛选、收盘价相对位置、行业涨幅排名、开盘涨幅判断等多个环节。例如,ABC1和ABC2用于筛选st股和*st股,ABC5和ABC6分别计算股票的相对位置和行业涨幅排名。在指标计算中,BAC1~BAC是一系列复杂的条件判断,用于确定个股的入选资格,如交易天数、市值、代码特征等。
个人小结部分,这个指标存在逻辑不清晰、拼凑痕迹明显的问题,但它也提供了一种思路:通过行业中涨势最好的个股寻找短期热点。对于有特定交易策略的投资者,如短线交易者,可能会有所启发。但要明确,本文仅用于学习交流,不构成投资建议。
投资决策应基于个人风险承受能力和专业评估,本文作者和发布者对此不承担任何责任。最后,再次强调,本文观点仅为学习资源,读者需谨慎对待,并在必要时咨询专业人士。
用 Redis 搞定游戏中的实时排行榜,附源码!
本文将深入探讨如何利用 Redis 实现游戏中的实时排行榜,并提供实现细节和源码。
首先,我们以一个坦克手游为例。游戏中每个角色可拥有多种类型的坦克,玩家可以加入军团(公会)。这个系统需要实现两种主要的排行榜:等级排行榜和通天塔排行榜。
等级排行榜的实现思路是将等级和战斗力合并为一个复合积分。我们可以设定一个公式:分数 = 等级* + 战力。因为玩家等级范围从1到,战斗力范围从0到,所以我们设计时考虑到,等级需要3位数,战斗力需要位数,合计需要位数的积分,而Redis的有序集合(SortedSet)的score取值范围是位整数或双精度浮点数,足以容纳这个需求。
对于通天塔排行榜,我们采用类似但略有不同的策略。要求相同层数下,通关时间越早越排在前。我们可以将通关时间转换为相对于一个较远时间点(如--)的相对时间,计算公式为:分数 = 层数 * ^N + (基准时间 - 通关时间)。这里我们选择一个远到足以避免现实时间影响的时间戳,从而确保排名的公正性。
为了实现实时更新排行榜数据,我们采用一个策略:使用 Redis 的有序集合存储玩家的复合积分(如角色uid和坦克id),而使用哈希存储动态数据(如玩家的其他相关信息)。当玩家等级或战斗力发生改变时,实时更新有序集合中的积分值即可。对于其他可能变化的数据,也相应地更新哈希表中的数据。
在取排行榜时,以等级排行榜为例,我们可以使用 Redis 的命令来获取数据。具体的代码实现通常涉及多步骤操作,例如准备数据、排序、分批取数据等。优化点在于合理使用 Redis 的 Pipeline 和 Multi 模式,以提高性能和效率。
最终,排行榜的实现并不止于此,我们需要考虑的细节还包括对排行榜数据的展示、排序算法的优化等。这里提供了一个基本框架和实现思路,具体的代码和详细步骤需要根据实际项目需求和环境进行调整。
通过以上内容,我们已经对如何利用 Redis 来搭建游戏排行榜系统有了深入的理解。通过合理的数据结构设计和 Redis 命令的运用,可以实现高效、实时且易于维护的排行榜功能。
桶排序C++实现源码
本文将详细介绍桶排序的C++实现源码,以解答如何高效处理大规模数据排序的问题。桶排序是一种基于分组的排序算法,首先将数据分入不同“桶”中,然后对每个桶进行排序,最后将排序后的桶合并。
代码首先定义了一个包含整数数组的主函数`main`,用于输出原始数组并展示排序后的结果。接着定义了桶排序函数`bucketSort`,该函数接收待排序的数组`a`。桶排序的核心步骤包括计算数组中最大值的位数`digits`、分发元素到桶、收集桶中的元素以及清除桶。
分发元素到桶的函数`distributeElements`,它利用除数`divisor`计算元素的“位置”,并根据元素值更新桶中的计数和元素。收集桶中的元素的函数`collectElements`,它遍历桶并按顺序收集桶内的元素,重新排列数组`a`。
为了确保桶排序能够正确处理不同位数的元素,还需要计算最大值的位数`numOfDigits`,这通过遍历数组并找到最大值实现。清除桶的函数`zeroBucket`用于在处理多组数据时保持桶的初始状态。
通过上述步骤,桶排序能够在O(n)时间复杂度下对大规模数据进行高效排序。这种方法特别适用于数据分布较为均匀的情况,相较于其他排序算法,它在处理大数据时展现出更优的性能。通过精心设计的桶排序实现,可以有效提升数据处理的效率,满足高并发环境下的实时排序需求。
LaTeX学习笔记II:数学公式与代码排版(附源码)
本文旨在深入介绍利用LaTeX进行数学公式与代码排版的方法,为生成高质量科技和数学类文档提供技术支持。LaTeX以其卓越的排版功能和数学公式处理能力,成为学术和出版领域中的首选工具。在前文的基础上,本文将着重探讨以下几点: 1. 插入页码 在LaTeX文档中插入页码,可通过调用`\pagenumbering{ 数字形式}`命令实现。此命令后可指定页码的显示形式,如阿拉伯数字、罗马数字(大小写)、拉丁字母(大小写)等。 2. 高亮显示Matlab代码 为了在LaTeX中高亮显示Matlab代码,可借助`mcode`宏包。该宏包需要从Matlab论坛下载,并集成到CTEX宏包中。使用时,应确保文档加载了`mcode`,以实现代码的高亮显示功能。 由于`lisitings`宏包不支持中文高亮,显示中文代码面临挑战。解决方法较为简单,即避免在Matlab代码中使用中文字符。 3. 公式输入与排版 LaTeX提供了多种方式输入数学公式,如使用`amsmath`包中的命令,如`cases`、`sum`等。插入空心字符使用`amsfonts`包中的`mathbb{ R}`命令。矩阵、方程组及求和式的排版可通过`aligned`环境实现,支持多行书写、对齐以及换行。 公式不标序号可通过在公式环境声明中添加星号“*”实现。对于矩阵的表示,LaTeX提供了丰富的省略符号,如`cdots`、`ddots`、`vdots`等。 4. 位置 LaTeX通过`[htbp]`参数控制在文档中的浮动位置。`h`表示当前位置,`t`表示顶部,`b`表示底部,`p`表示浮动页。一般情况下,`[htb]`组合更为常用,确保文档布局美观。 正确使用这些参数,结合`float`宏包的`[H]`选项,可以灵活控制的显示位置,满足不同布局需求。如果遇到位置问题,应合理调整参数组合,以达到最佳排版效果。 本文提供了LaTeX中数学公式与代码排版的实用技巧,旨在帮助用户高效地生成高质量文档。通过掌握上述方法,用户能够更加便捷地处理复杂的数学表达和程序代码展示,实现专业化的文档制作。px竞价排序指标源码!最新排序出炉
{ PX排序公式}
连板指标:BARSLASTCOUNT(C>=REF(C,1)*1. AND C=H)
竞价额1:DYNAINFO()/
流通市值:FINANCE()/
竞价手数:DYNAINFO()/DYNAINFO(4)/
万手指标:竞价手数/
竞流比:(竞价手数/FINANCE())
*涨停系数:(FINANCE()/)*O
竞5指标:竞价手数/涨停系数
比值指标:竞价额1/流通市值/#DAY
强度指标:竞5/比值
基本量指标:REF(V,1)#DAY*0./
力度指标:万手/基本量
*时间指标:IF(基本量/万手<=,基本量/万手,0){ 分钟}
高开指标:(O/REF(C,1)-1)*,NODRAW,COLORYELLOW
强度指标:REF(V,1)#DAY/FINANCE()*,COLORYELLOW
{ 取范围}
过滤条件:去低值 AND 去ST AND 去星星 AND 去特殊 AND 去新股 AND 去次新股 AND NOT(REF(ZT,1))
{ 取股票范围}
评分:F1+F2+F3+F4
观察强度:竞价额1/时间,NODRAW
涨幅指标:C/REF(C,1)*-
昨涨幅指标:REF(涨幅,1)
TJ1指标:SQRT(REF(H,1)*REF(L,1))
ZGJ指标:REF(HHV(H,2),1)#DAY
竞价量指标:GPJYVALUE(,1,0)
开盘金额A:竞价量*O/
竞换手指标:开盘金额A/O/FINANCE()
*今竞额指标:IF(CURRBARSCOUNT=1 AND PERIOD=5,DYNAINFO()/,竞金额)COLORGREEN,NODRAW
换手Z指标:今竞额*/O/FINANCE()* COLORGREEN,NODRAW
BL指标:今竞额*/REF(HHV(AMOUNT,5),1)* COLORGREEN,NODRAW
☆爆☆指标:IF(FINANCE(7)*O/< AND REF(ZT,1) AND 观察强度> AND 观察强度<,BL*换手Z*(O-REF(O,1))/REF(O,1)*,0)


2024-12-26 00:18
2024-12-25 23:51
2024-12-25 23:24
2024-12-25 23:22
2024-12-25 22:44
2024-12-25 22:35
2024-12-25 22:30
2024-12-25 22:26