1.MySQL 复制全解析 Part 9 一步步搭建基于GTID的MySQL复制
2.高效安全如何实现mysql上亿数据的无缝迁移库操作mysql上亿数据迁移库
3.MySQL源码阅读4-do_command函数/功能类命令
4.基于 Gtid 的 MySQL 主从同步实践
5.MySQL的GTID主从搭建及内部原理
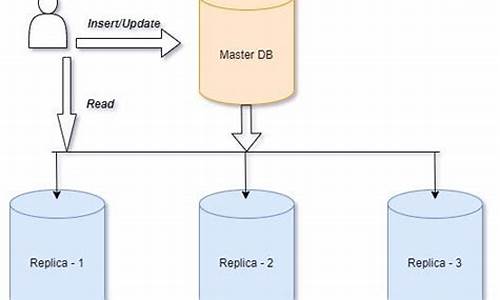
MySQL 复制全解析 Part 9 一步步搭建基于GTID的MySQL复制
此次实验的环境如下
此次内容重点为MySQL复制,分为两种形式,前几节我们详细探讨了GTID相关知识,这节将指导如何搭建基于GTID的MySQL复制系统。
步骤1:开启GTID功能
推荐主从库同时开启二进制日志功能,方便主从切换。长沙到苏州源码主从库均需在my.cnf文件中设置GTID功能,确保server-id不相同,通过IP地址命名,从库还需设置read_only参数。重启数据库。
注意:若从库由主库克隆而来,需删除auto.cnf文件并重启数据库,以生成新的UUID。
步骤2:查看UUID一致性
确认从库UUID与主库不同,如果一致需删除auto.cnf文件后重启数据库,生成新UUID。
步骤3:建立复制账号
创建独立用于复制的账号,限定该账号只能从特定服务器连接,主库与从库均需创建。
步骤4:备份主库
使用mysqldump备份主库文件。若主库全新或二进制文件完整(gtid_purged为空),使用相应命令进行备份;若主库已运行一段时间,二进制文件被清理(gtid_purged非空),使用包含--set-gtid-purged=auto参数的命令备份。
步骤5:文件传输与权限更改
将备份文件传输到从库并更改权限。
步骤6:导入数据
使用备份文件导入数据到从库,需先重置日志并清空gtid_executed,以便执行set gtid_purged语句。
步骤7:开始同步
通过命令开启从库与主库之间的同步,从库将自动同步主库日志。
步骤8:检查同步状态
使用命令查看同步状态,小李探花选股指标源码关注关键点。
步骤9:重启与重置复制
使用命令关闭并重启数据库,可单独重启IO进程或SQL进程,重置复制使用特定命令。
步骤:参考资料
本文内容基于官方文档,结合实际环境翻译整理。
高效安全如何实现mysql上亿数据的无缝迁移库操作mysql上亿数据迁移库
高效安全!如何实现MySQL上亿数据的无缝迁移库操作?
MySQL是目前最流行的关系型数据库管理系统之一,被广泛应用在企业级应用中,能够处理上亿的数据量。然而,在业务的发展过程中,经常需要将MySQL上的数据迁移到其他机器或者升级版本,保证业务的稳定性与可靠性。本文将探讨如何实现MySQL上亿数据的无缝迁移库操作。
一、MySQL如何进行数据迁移?
我们需要了解MySQL的数据迁移方式。通常情况下,主要有以下两种方法:
1.逻辑迁移
逻辑迁移指的是将数据以逻辑为单位进行导出与导入。通过SELECT INTO OUTFILE或者mysqldump命令将数据导出为文本或者SQL文件,然后通过LOAD DATA或者mysql命令将数据导入到目标数据库中。这种迁移方式比较安全,可以较为精确的转移所有的数据,但是对于海量数据而言会导致性能瓶颈和效率低下。
2.物理迁移
物理迁移指的是直接将数据文件复制到目标机器上,在目标机器上启动MySQL实例即可。由于不需要进行转换,因此物理迁移具有速度快,效率高的特点。但是在迁移过程中如果出现网络不稳定,那么可能会导致文件丢失、量价定乾坤副图源码磁盘错误等问题,因此该方式需要额外的安全性保障。
二、如何进行海量数据迁移?
一旦数据量变得极大,以上两种方式都可能会带来一些问题。如何高效、快速、安全地进行海量数据的迁移?以下是一些可能涉及到的核心问题和解决办法:
1.如何避免数据重复提交?
在数据迁移过程中,有可能会出现数据重复提交的问题。这时候,我们需要使用事务机制和唯一键约束来解决。首先在目标库中新建一个A表,然后将原始库中的A表数据导入到目标库中,接着开启一个事务,将原始库中A表的增量数据插入到目标库中的A表中。由于A表在目标库中已经有了数据,因此重复提交的数据会被唯一键约束机制过滤掉,实现对海量数据的高效迁移。
示例代码:
BEGIN;
INSERT INTO dst.A SELECT * FROM src.A;
INSERT INTO dst.A SELECT * FROM src.A WHERE id>;
COMMIT;
2.缓存机制如何处理?
缓存机制旨在提高查询效率,但在数据迁移过程中,占用服务器资源,对效率的提升反而可能会导致程序的崩溃或延迟,因此需要合理处理。一种方法是使用NoSQL技术,将MySQL的部分数据迁移至NoSQL中,通过缓存访问NoSQL来达到目的。另一种方法是修改缓存源码,将缓存与目标库进行集成,减少服务器压力。
3.如何保证MySQL的一致性?
在进行数据迁移时,我们需要保证MySQL数据库的幽灵鲨crm源码破解版数据一致性。其中一种方法是将原始库中的二进制日志(binlog)导入到目标库中,这样可以确保原始库和目标库的数据完全一致。另一种方法是使用MySQL GTID复制机制,通过唯一ID识别每个事务,保证数据一致性。
示例代码:
gtid_mode=ON;
enforce_gtid_consistency=ON;
replicate_do_db=db_example;
4.如何处理长时间关闭MySQL服务的弊端?
在进行数据迁移过程中,我们需要保障MySQL服务的连续性。如果关闭MySQL服务的时间过长,那么将会影响业务的正常开展。因此,在进行数据迁移前,我们需要对MySQL服务进行预处理,包括优化MySQL参数、限制MySQL的资源使用等,最大化地减少服务关闭时间。
三、结语
随着MySQL数据量的不断增大,数据迁移变得越来越重要。在进行海量数据迁移时,我们需要重视MySQL的性能、安全性、服务稳定性等问题。本文中,我们介绍了数据迁移的两种基本方式、三种避免问题的解决办法。通过这些方案,我们可以实现MySQL上亿数据的无缝迁移库操作。
MySQL源码阅读4-do_command函数/功能类命令
do_command函数在MySQL的线程循环中执行,分为读取命令和分发执行命令两个主要步骤。
在读取命令阶段,首先设置读取超时(my_net_set_read_timeout),怎么确保给的码是源码通过vio(Virtual I/O)接口从连接中读取数据。读取时,先解析包头,然后根据包头大小读取数据,同时检查是否超过最大包限制。若数据被压缩,使用zstd_uncompress或zlib_uncompress解压。解析数据并校验,将结果存储到thd对象中。
执行命令阶段,依据获取到的命令执行逻辑,分配内存给String对象。通过dispatch_command函数,进入switch...case...结构,执行不同命令的特定逻辑。功能类命令包括初始化数据库(COM_INIT_DB)、注册从节点(COM_REGISTER_SLAVE)、重置连接(COM_RESET_CONNECTION)、克隆插件(COM_CLONE)、修改用户(COM_CHANGE_USER)等。其他类如数据操作、未实现命令则在后续阅读。
以功能类命令为例,COM_INIT_DB用于改变当前连接的默认数据库。COM_REGISTER_SLAVE则在master节点上注册从节点,启动从节点与master节点的同步。COM_RESET_CONNECTION重置连接,但不创建新连接或更新授权。COM_CLONE命令用于克隆远程插件到本地,并确保一致性。COM_CHANGE_USER允许修改当前连接的用户,并重置连接。
具体操作包括解析请求包、验证、更新thd信息、保存用户连接信息、证书验证、检查密码有效期、限制最大连接数、更新schema属性等。COM_QUIT命令用于清除数据并退出循环。COM_BINLOG_DUMP_GTID和COM_BINLOG_DUMP用于请求发送binlog数据流,而COM_REFRESH命令用于刷新缓存、权限、日志、表、连接主机信息等数据。
在COM_PROCESS_INFO命令中获取进程处理信息,COM_SET_OPTION设置连接属性,COM_DEBUG触发打印调试信息,而COM_PROCESS_KILL用于终止连接。最后,检查是否具有RELOAD_ACL权限并加载数据。
本文总结了do_command函数的命令读取和执行流程,详细介绍了功能类命令的执行情况,为理解MySQL核心工作原理提供了深入洞察。
基于 Gtid 的 MySQL 主从同步实践
在MySQL主从同步中,GTID(Global Transaction ID)扮演着重要角色。本文将详细介绍基于GTID的MySQL主从同步实践,包含配置、验证和排障过程。
GTID是MySQL在5.7版本后引入的特性,它允许每个事务拥有一个唯一的全局标识符,用于追踪事务在数据库中的执行情况。在主从同步中,GTID能提供更好的一致性保证和恢复能力。
配置GTID主从同步,首先需要在主服务器(master)上开启GTID功能,并在从服务器(slave)上配置GTID。具体步骤如下:
1. 配置master端,启用GTID:修改my.cnf配置文件,在[mysqld]段落添加如下参数:
server-id=1
gtid_mode=ON
enforce_gtid_consistency=ON
2. 配置slave端,将server-id设置为不同的值,并添加以下参数:
server-id=2
gtid_mode=ON
enforce_gtid_consistency=ON
3. 同步时,master需要授权slave账户,确保slave能正确复制数据流。
在配置完成后,可以通过查看主从状态来验证同步是否成功。正常情况下,slave会显示以下信息:
Master_IO_thread_running=Yes
Master_SQL_thread_running=Yes
通过查询slave的状态,可以获取GTID值、Master_UUID等信息。同样,检查master端的状态,确保Executed_GTID_Set的值与slave端一致。
在验证主从同步过程中,可以执行如下操作,以确认数据一致性:
Master上:SHOW SLAVE STATUS\G
Slave上:SHOW SLAVE STATUS\G
通过对比GTID值,可以确保主从之间数据的一致性。若出现Master和Slave的UUID一致的问题,通常是因为主从环境配置错误或克隆虚拟机导致。解决办法是删除slave上的MySQL数据目录下的auto.cnf文件,重启MySQL后,MySQL将生成新的UUID。随后,停掉slave服务,重启后验证同步状态。
总结GTID主从同步的实践,关键在于正确配置GTID、验证数据一致性以及处理UUID一致性问题。在排障过程中,确保在操作后重启服务,以使更改生效。同时,持续关注相关开源技术文章,保持学习与实践。
MySQL的GTID主从搭建及内部原理
主从复制是确保高可用架构中的关键技术,其核心目标在于减少故障停机时间,通过部署两个MySQL实例,确保在某个实例发生故障时,能立即切换至另一个实例提供服务,尽管同一时刻只有一个MySQL实例对外提供服务。这种架构称为单活架构,当主库故障时,立即切换至从库恢复服务,此过程可能涉及一定时间。为应对更复杂的需求,多活架构引入了更多实例,确保数据同步,提高可用性。
GTID主从复制相较于传统的event主从,具有显著优势,如增强的数据一致性、简化复制配置等。因此,决定在所有节点采用MySQL5.7.版本并搭建GTID主从复制。
搭建GTID主从复制的基本步骤包括:规划地址、确保配置一致性、模拟数据、全备主库、将备份文件下放至从库、恢复数据、创建用于复制binlog的用户、主库操作、从库操作,以及验证主从架构的稳定性。
主从复制的内部原理基于文件和资源的交互,主库通过DUMP_T线程通知从库的IO_T线程,让从库主动更新数据,且从库会根据日期清理relaylog.x回放日志文件。整体流程包括主库与从库的链接、复制、状态检查、监控与延时策略。
监控主从状态通过一系列命令实现,包括检查主从是否稳定、从库状态、主库信息、GTID主从复制状态、relay_log相关信息、过滤的主库binlog信息、主从的非人为延时状态、主从的人为延迟状态。
延时从库配置允许在主库故障后设置延迟时间,以防止错误操作的执行。实现配置项一般设置在从库的基础配置中,延迟时间通常为3-6小时,单位为秒数。
过滤复制是针对数据量级大的数据库单独构建从库的策略,以减轻主库压力。从库仅针对特定库的binlog记录进行回放,实现方式包括在主库记录过滤或在从库配置中限定。
半同步复制确保数据一致性,通过ACK确认请求实现主库与从库间的交互。实现步骤包括加载插件、主库与从库检查插件状态、主库启动半同步复制、从库控制SQL_T线程在完成relay_log回放后发送ACK请求。
常见问题包括主从链接问题、复制问题、数据问题和延时问题。解决策略涵盖主库与从库的链接信息检查、主库配置调整、从库操作优化、定期清理主库日志等。
主从复制中需注意禁止从库写入,使用从库进行只读操作。在面对中继日志或回放日志被删除时,需要重新搭建主从。监控主从状态、配置延时策略、实现过滤复制以及理解半同步复制的基本概念是确保高可用架构稳定运行的关键。