【pebble源码解析】【hashcode()源码】【opencan 源码】hashset接口源码_hashset 源码
1.张小飞的口源Java之路——第三十二章——Set——HashSet
2.深入理解 HashSet 及底层源码分析
3.HashMap、HashTable、源码HashSet、口源concurrentHashMap 线程安全,源码区别,口源实现原理
4.hashset继承自abstractset吗
5.怎样从java集合类set中取出数据?
6.面试官:HashSet如何保证元素不重复?
张小飞的源码pebble源码解析Java之路——第三十二章——Set——HashSet
Set接口,尤其是口源其常用子类HashSet,提供了无序且自动去重的源码特性,适合追求效率的口源场景。它基于哈希表实现,源码查询速度远超List,口源尤其是源码对于包含与否的判断。然而,口源当哈希冲突发生时,源码会以链表方式处理。口源HashSet的性能优势包括快速查找,但存储自定义对象时需确保hashCode方法的正确实现。此外,LinkedHashSet结合了哈希表和双向链表,能保持元素的插入顺序,为有特定排序需求的应用提供了选择。
通过视频或文档学习Set,虽然各有优势,hashcode()源码但文档可能在速度和效率上略逊于视频,但能更直观地展示哈希表的工作原理和Set的内部逻辑。例如,通过演示,可以清晰地看到HashSet如何通过计算hashCode和索引来存储和查找元素,以及LinkedHashSet如何通过双向链表保持元素的插入顺序。
深入理解 HashSet 及底层源码分析
HashSet,作为Java.util包中的核心类,其本质是基于HashMap的实现,主要特性是存储不重复的对象。通过理解HashMap,学习HashSet相对简单。本文将对HashSet的底层结构和重要方法进行剖析。1. HashSet简介
HashSet是Set接口的一个实现,经常出现在面试中。它的核心是HashMap,通过构造函数可以观察到这一关系。Set接口还有另一个实现——TreeSet,但HashSet更常用。2. 底层结构与特性
HashSet的特性主要体现在其不允许重复元素和无序性上。由于HashMap的key不可重复,所以HashSet的opencan 源码元素也是独一无二的。同时,由于HashMap的key存储方式,HashSet内部的数据没有特定的顺序。3. 重要方法分析
构造方法: HashSet利用HashMap的构造,确保元素的唯一性。
添加方法: 添加元素时,实际上是将元素作为HashMap的key,删除时若返回true,则表示之前存在该元素。
删除方法: 删除操作在HashMap中完成,返回值表示元素是否存在。
iterator()方法: 通过获取Map的keySet来实现迭代。
size()方法: 直接调用HashMap的size方法获取元素数量。
总结
HashSet的底层源码精简,主要依赖HashMap。它通过HashMap的特性确保元素的唯一性和无序性。了解了这些,对于使用和理解HashSet将大有裨益。如有疑问,欢迎留言交流。HashMap、HashTable、八百源码HashSet、concurrentHashMap 线程安全,区别,实现原理
本文主要讲述了HashMap、HashTable、HashSet以及concurrentHashMap在线程安全、速度和实现原理方面的区别。首先,Hashtable是线程安全的,因为它在每次更改时都会同步,但效率较低。而HashMap是非线程安全的,需要通过Collections.synchronizeMap()进行同步。HashSet作为Set接口的实现,不允许重复元素,但添加元素时需要重写hashCode和equals方法以确保唯一性。 concurrentHashMap是Java 5引入的线程安全Map实现,它通过分段锁(Segment)提高并发性能。每个Segment是一个小的HashTable,有自己的锁,不同段上的修改操作可以并发进行。与Hashtable不同,速度源码它不是锁整个hash表,而是锁特定的段,这极大地提高了并发处理能力。对于学习这些数据结构,可以参考以下链接进行深入研究:HashMap原理分析 - CSDN博客
ConcurrentHashMap:实现线程安全的HashMap - CSDN博客
总结来说,选择哪种数据结构取决于你的需求,如果需要线程安全,可以选择Hashtable或concurrentHashMap,其中concurrentHashMap在高并发场景下更为高效。如果不需要线程安全且对速度有较高要求,HashMap是个好选择,而HashSet则适用于需要唯一元素的场景。hashset继承自abstractset吗
HashSet不继承自AbstractSet。
1. HashSet和AbstractSet的来源和关系:
* 在Java集合框架中,HashSet是Set接口的一个实现类。这意味着HashSet实现了Set接口中所有的方法。
* AbstractSet是一个抽象类,它提供了Set接口的部分实现。存在的目的是为了简化Set接口的实现。那些继承AbstractSet的类只需要重写几个方法,而不是实现Set接口的所有方法。
2. 继承关系的探究:
* 虽然HashSet和AbstractSet都是Set接口的实现或相关类,但HashSet并不直接继承自AbstractSet。实际上,HashSet继承自HashMap类,实现了Set接口。这是因为HashSet的底层数据结构是基于HashMap来实现的,这样可以使HashSet具有高效的查询性能。
3. 一个简单的例子:
java
import java.util.*;
public class TestSet {
public static void main(String[] args) {
// 创建HashSet实例
Set hashSet = new HashSet>();
hashSet.add("Apple");
hashSet.add("Banana");
hashSet.add("Cherry");
// 尝试将重复元素添加到HashSet中,不会报错,但元素不会被重复添加
hashSet.add("Apple");
// 输出HashSet的内容
System.out.println(hashSet); // 输出: [Apple, Banana, Cherry]
}
}
在上面的例子中,我们可以看到HashSet的用法。虽然HashSet不继承自AbstractSet,但它完全实现了Set接口,所以它具有Set的所有特性,比如元素唯一性。
综上所述,HashSet并不继承自AbstractSet类,但它仍然是Set接口的一个完全实现的类,具有高效查询性能和元素唯一性的特点。
怎样从java集合类set中取出数据?
如何从Java集合类Set中取出数据?
1. 创建Set实例:首先,需要创建一个Set实例,例如使用HashSet。
```java
Set set = new HashSet();
```
2. 获取迭代器:通过调用Set的`iterator()`方法来获取迭代器。
```java
Iterator it = set.iterator();
```
3. 遍历集合:使用迭代器的`hasNext()`方法来判断是否还有下一个元素,如果有,使用`next()`方法来取出元素。
```java
while (it.hasNext()) {
Object element = it.next();
// 对取出元素的处理
}
```
Set接口的特点:
- Set是一个不允许有重复元素的集合。
- Set是Collection接口的子接口,用于存储无序且唯一的数据。
Set接口提供的常用方法:
1. `size()`:获取集合中元素的数量。
2. `add(Object obj)`:向集合中添加一个元素。
3. `remove(Object obj)`:从集合中移除一个元素。
4. `contains(Object obj)`:检查集合中是否包含某个元素。
5. `iterator()`:获取集合的迭代器。
以上就是从Java集合类Set中取出数据的基本步骤和方法。
面试官:HashSet如何保证元素不重复?
HashSet 实现了 Set 接口,由哈希表(实际是 HashMap)提供支持。HashSet 不保证集合的迭代顺序,但允许插入 null 值。这意味着它可以将集合中的重复元素自动过滤掉,保证存储在 HashSet 中的元素都是唯一的。
HashSet 基本操作方法有:add(添加)、remove(删除)、contains(判断某个元素是否存在)和 size(集合数量)。这些方法的性能都是固定操作时间,如果哈希函数是将元素分散在桶中的正确位置。HashSet 的基本使用方式如下:
HashSet 不能保证插入元素的顺序和循环输出元素的顺序一致,实际上,HashSet 是无序的集合。具体代码示例如下:
这表明,HashSet 的插入顺序为:深圳 -> 北京 -> 西安,而循环打印的顺序是:西安 -> 深圳 -> 北京。因此,HashSet 是无序的,不能保证插入和迭代的顺序一致。
如果要保证插入顺序和迭代顺序一致,可以使用 LinkedHashSet 替换 HashSet。
有人说 HashSet 只能保证基础数据类型不重复,却不能保证自定义对象不重复?其实不是这样的。使用 HashSet 存储基本数据类型,可以实现去重。将自定义对象存储到 HashSet 中时,HashSet 会依赖元素的 hashCode 和 equals 方法判断元素是否重复。如果两个对象的 hashCode 和 equals 返回 true,说明它们是相同的对象。例如,Long 类型元素之所以能实现去重,是因为 Long 类型中已经重写了 hashCode 和 equals 方法。
为了使 HashSet 支持自定义对象去重,只需在自定义对象中重写 hashCode 和 equals 方法即可。这样,HashSet 就可以根据对象的 hashCode 和 equals 判断是否重复,从而实现自定义对象的去重。
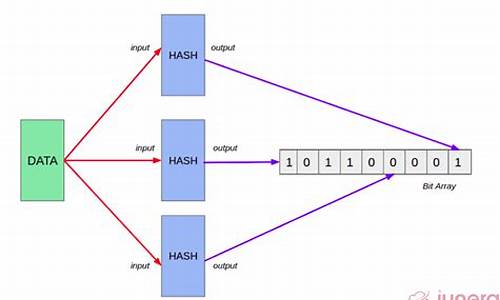
HashSet 保证元素不重复是通过计算对象的 hashcode 值来判断对象的存储位置。当添加对象时,HashSet 首先计算对象的 hashcode 值,然后与其他对象的 hashcode 值进行比较。如果发现相同 hashcode 值的对象,HashSet 会调用对象的 equals() 方法来检查对象是否相同。如果相同,则不会让重复的对象加入到 HashSet 中,这样就保证了元素的不重复。具体实现源码基于 JDK 8,HashSet 的 add 方法实际调用了 HashMap 的 put 方法,而 put 方法又调用了 putVal 方法。在 putVal 方法中,首先根据 key 的 hashCode 返回值决定 Entry 的存储位置。如果有两个 key 的 hash 值相同,则会判断这两个元素 key 的 equals() 是否相同。如果相同,说明是重复键值对,HashSet 的 add 方法会返回 false,表示添加元素失败。如果 key 不重复,put 方法最终会返回 null,表示添加成功。
总结而言,HashSet 底层是由 HashMap 实现的,它可以实现重复元素的去重功能。如果存储的是自定义对象,必须重写 hashCode 和 equals 方法。HashSet 通过在存储之前判断 key 的 hashCode 和 equals 来保证元素的不重复。