基隆廟口名店爆油豆腐「包小強」 民眾喊噁:加菜?
2024-12-26 00:09
1.ZMQ源码详细解析 之 进程内通信流程
2.golang chan 最详细原理剖析,完全完全全面源码分析!解析解析看完不可能不懂的源码源码!
3.Glide源码分析
4.深入理解 Python 虚拟机:列表(list)的完全完全实现原理及源码剖析
5.vue3源码分析——实现slots
6.剖析Linux内核源码解读之《实现fork研究(一)》
ZMQ源码详细解析 之 进程内通信流程
ZMQ进程内通信流程解析
ZMQ的核心进程内通信原理相当直接,它利用线程间的解析解析两个队列(我称为pipe)进行消息交换。每个线程通过一个队列发送消息,源码源码源码资源分享博客从另一个队列接收。完全完全ZMQ负责将pipe绑定到对应线程,解析解析并在send和recv操作中通过pipe进行数据传输,源码源码非常简单。完全完全
我们通过一个示例程序来理解源码的解析解析工作流程。程序首先创建一个简单的源码源码hello world程序,加上sleep是完全完全为了便于分析流程。程序从`zmq_ctx_new()`开始,解析解析这个函数创建了一个上下文(context),源码源码这是ZMQ操作的起点。
在创建socket时,如`zmq_socket(context, ZMQ_REP)`,实际调用了`ctx->create_socket`,socket类型决定了其特性。rep_t是基于router_t的特化版本,主要通过限制router_t的某些功能来实现响应特性。socket的创建涉及到诸如endpoint、slot和 mailbox等概念,它们在多线程环境中协同工作。
进程内通信的建立通过`zmq_bind(responder, "inproc://hello")`来实现,这个端点被注册到上下文的endpoint集合中,便于其他socket找到通信通道。zmq的优化主要集中在关键路径上,避免对一次性操作过度优化。
接下来的recv函数是关键,即使没有连接,它也会尝试接收消息。`xrecv`函数根据进程状态可能阻塞或返回EAGAIN。recv过程涉及`msg_t`消息的处理,以及与`signaler`和`mailbox`的交互,这些组件构成了无锁通信的核心。
发送端通过`connect`函数建立连接,创建连接通道,并将pipe关联到socket。这个过程涉及无锁队列的管理,如ypipe_t和pipe_t,以及如何均衡发送和接收。
总结来说,ZMQ进程内通信的核心是通过管道、队列和事件驱动机制,实现了线程间的数据交换。随着对ZMQ源码的深入,会更深入理解这些基础组件的mvc项目源码阅读设计和工作原理。
golang chan 最详细原理剖析,全面源码分析!看完不可能不懂的!
大纲
概述
chan 是 golang 的核心结构,是与其他高级语言区别的显著特色之一,也是 goroutine 通信的关键要素。尽管广泛使用,但对其深入理解的人却不多。本文将从源码编译器的视角,全面剖析 channel 的用法。
channel 的本质
从实现角度来看,golang 的 channel 实质上是环形队列(ringbuffer)的实现。我们将 chan 称为管理结构,channel 中可以放置任何类型的对象,称为元素。
channel 的使用方法
我们从 channel 的使用方式入手,详细介绍 channel 的使用方法。
channel 的创建
创建 channel 时,用户通常有两种选择:创建带有缓冲区和不带缓冲区的 channel。这对应于 runtime/chan.go 文件中的 makechan 函数。
channel 入队
用户使用姿势:对应函数实现为 chansend,位于 runtime/chan.go 文件。
channel 出队
用户使用姿势:对应函数分别是 chanrecv1 和 chanrecv2,位于 runtime/chan.go 文件。
结合 select 语句
用户使用姿势:对应函数实现为 selectnbsend,位于 runtime/chan.go 文件中。
结合 for-range 语句
用户使用姿势:对应使用函数 chanrecv2,位于 runtime/chan.go 文件中。
源码解析
以上,我们通过宏观的用户使用姿势,了解了不同使用姿势对应的不同实现函数,接下来将详细分析这些函数的实现。
makechan 函数
负责 channel 的创建。在 go 程序中,当我们写类似 v := make(chan int) 的初始化语句时,就会调用不同类型对应的初始化函数,其中 channel 的初始化函数就是 makechen。
runtime.makechan
定义原型:
通过这个,我们可以了解到,声明创建一个 channel 实际上是得到了一个 hchan 的指针,因此 channel 的核心结构就是基于 hchan 实现的。
其中,t 参数指定元素类型,size 指定 channel 缓冲区槽位数量。如果是带缓冲区的 channel,那么 size 就是槽位数;如果没有指定,那么就是 0。
makechan 函数执行了以下两件事:
1. 参数校验:主要是mysql原版源码解析越界或 limit 的校验。
2. 初始化 hchan:分为三种情况:
所以,我们看到除了 hchan 结构体本身的内存分配,该结构体初始化的关键在于四个字段:
hchan 结构
makechan 函数负责创建了 chan 的核心结构-hchan,接下来我们将详细分析 hchan 结构体本身。
在 makechan 中,初始化时实际上只初始化了四个核心字段:
我们使用 channel 时知道,channel 常常会因为两种情况而阻塞:1)投递时没有空间;2)取出时还没有元素。
从以上描述来看,就涉及到 goroutine 阻塞和 goroutine 唤醒,这个功能与 recvq,sendq 这两个字段有关。
waitq 类型实际上是一个双向列表的实现,与 linux 中的 LIST 实现非常相似。
chansend 函数
chansend 函数是在编译器解析到 c <- x 这样的代码时插入的,本质上就是把一个用户元素投递到 hchan 的 ringbuffer 中。chansend 调用时,一般用户会遇到两种情况:
接下来,我们看看 chansend 究竟做了什么。
当我们在 golang 中执行 c <- x 这样的代码,意图将一个元素投递到 channel 时,实际上调用的是 chansend 函数。这个函数分几个场景来处理,总结来说:
关于返回值:chansend 返回值标明元素是否成功入队,成功则返回 true,否则 false。
select 的提前揭秘:
golang 源代码经过编译会变成类似如下:
而 selectnbasend 只是一个代理:
小结:没错,chansend 功能就是这么简单,本质上就是一句话:将元素投递到 channel 中。
chanrecv 函数
对应的 golang 语句是 <- c。该函数实现了 channel 的元素出队功能。举个例子,编译对应一般如下:
golang 语句:
对应:
golang 语句(这次的区别在于是否有返回值):
对应:
编译器在遇到 <- c 和 v, ok := <- c 的语句时,会换成对应的 chanrecv1,chanrecv2 函数,这两个函数本质上都是一个简单的封装,元素出队的实现函数是 chanrecv,我们详细分析这个函数。
chanrecv 函数的返回值有两个值,selected,received,其中 selected 一般作为 select 结合的函数返回值,指明是否要进入 select-case 的代码分支,received 表明是否从队列中成功获取到元素,有几种情况:
selectnbsend 函数
该函数是 c <- v 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbsend 函数,如下:
对应编译函数逻辑如下:
selectnbsend 本质上也就是个 chansend 的封装:
chansend 的内部逻辑上面已经详细说明过,唯一不同的身份认证源码免费就是 block 参数被赋值为 false,也就是说,在 ringbuffer 没有空间的情况下也不会阻塞,直接返回。划重点:chan 在这里不会切走执行权限。
selectnbrecv 函数
该函数是 v := <- c 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbsrecv 函数,如下:
对应编译函数逻辑如下:
selectnbrecv 本质上也就是个 chanrecv 的封装:
chanrecv 的内部逻辑上面已经详细说明过,在 ringbuffer 没有元素的情况下也不会阻塞,直接返回。这里不会因此而切走调度权限。
selectnbrecv2 函数
该函数是 v, ok = <- c 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbrecv2 函数,如下:
对应编译函数逻辑如下:
selectnbrecv2 本质上是个 chanrecv 的封装,只不过返回值不一样而已:
chanrecv 的内部逻辑上面已经详细说明过,在 ringbuffer 没有元素的情况下也不会阻塞,直接返回。这里不会因此而切走调度权限。selectnbrecv2 与 selectnbrecv 函数的不同之处在于还有一个 ok 参数指明是否获取到了元素。
chanrecv2 函数
chan 可以与 for-range 结合使用,编译器会识别这种语法。如下:
这个本质上是个 for 循环,我们知道 for 循环关键是拆分成三个部分:初始化、条件判断、条件递进。
那么在我们 for-range 和 chan 结合起来之后,这三个关键因素又是怎么理解的呢?简述如下:
init 初始化:无
condition 条件判断:
increment 条件递进:无
当编译器遇到上面 chan 结合 for-range 写法时,会转换成 chanrecv2 的函数调用。目的是从 channel 中出队元素,返回值为 received。首先看下 chanrecv2 的实现:
chan 结合 for-range 编译之后的伪代码如下:
划重点:从这个实现中,我们可以获取一个非常重要的信息,for-range 和 chan 的结束条件只有这个 chan 被 close 了,否则一直会处于这个死循环内部。为什么?注意看 chanrecv 接收的参数是 block=true,并且这个 for-range 是一个死循环,除非 chanrecv2 返回值为 false,才有可能跳出循环,而 chanrecv2 在 block=true 场景下返回值为 false 的唯一原因只有:这个 chan 是 close 状态。
总结
golang 的 chan 使用非常简单,这些简单的语法糖背后其实都是对应了相应的函数实现,这个翻译由编译器来完成。深入理解这些函数的实现,对于彻底理解 chan 的使用和限制条件是必不可少的。深入理解原理,知其然知其所以然,你才能随心所欲地使用 golang。起爆大涨指标源码
Glide源码分析
深入剖析Glide源码:解析与理解其架构与机制
1. Glide三大关键流程
使用Glide加载时,主要包含三大关键流程:with、load、into。通过链式调用这些方法,能轻松完成加载任务,但背后蕴含的原理复杂且源码规模庞大。分析源码时,需抓住重点。
1.1 with主线
with方法是Glide中的重要接口,可传入Activity或Fragment,与页面生命周期紧密关联。在分析中,我们曾遇到线上事故,因伙伴在with方法中传入了Context而非Activity,导致页面消失后请求仍在后台运行,最终刷新页面时找不到加载的容器直接崩溃。因此,with方法与页面生命周期息息相关。
1.1.1 Glide创建
通过getRetriever方法最终获得RequestManagerRetriever对象。在Glide的构造方法中,通过双检锁方式创建Glide对象。之后,调用Glide的build方法创建一个Glide实例,传入缓存和Bitmap池等对象。
1.1.2 RequestManagerRetriever
Glide的build方法直接创建RequestManagerRetriever对象,需requestManagerFactory参数,若未定义则默认为DEFAULT_FACTORY。获取此对象后,方便后续加载。
1.1.3 生命周期管理
在获取RequestManagerRetriever后,调用其get方法。当with方法传入Activity时,会在子线程调用另一个get方法,而主线程中通过fragmentGet方法,创建空Fragment并同步页面生命周期。
1.1.4 总结
with方法主要完成:创建Glide对象,绑定页面生命周期。
1.2 load主线
通过with方法获得RequetManager,调用load方法创建RequestBuilder对象,将加载类型赋值给model。剩余操作由into方法负责。
1.3 into主线
into方法负责Glide的创建和生命周期绑定。传入ImageView,根据其scaleType属性复制RequestOption。into方法调用buildRequest返回Request,并判断是否能执行请求。执行请求或从缓存获取后回调onResourceReady。
1.3.1 发起请求
创建request后,调用RequetManager的track方法,执行请求并添加到请求队列。判断isPaused状态,决定是否发起网络请求。成功加载或从缓存获取后回调onResourceReady。
1.3.2 三级缓存
通过EngineKey获取资源,从内存、活动缓存和LRUCache中查找。若未获取到,则发起网络请求。成功后加入活跃缓存并回调onResourceReady。
1.3.3 onResourceReady
资源加载完成或从缓存获取后,调用SingleRequest的onResourceReady方法。判断是否设置RequestListener,最终调用target的onResourceReady方法,显示。
1.3.4 小结
into方法主要步骤包括:创建加载请求、判断请求执行、从缓存获取资源、网络请求与资源回调。
2. 手写简单Glide框架
实现Glide需理解其特性,特别是生命周期绑定和三级缓存。手写时,着重实现这两点。在load方法中,支持多种资源加载,并使用RequestOption保存请求参数。在into方法中,传入ImageView控件,并在buildTargetRequest方法中判断是否发起网络请求。实现三级缓存逻辑,确保加载效率。使用协程进行线程切换,提高性能。通过简单API加载本地或网络链接,实现Glide功能。
深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
在 Python 虚拟机中,列表作为基本数据类型之一,能够存储各种类型的数据并支持多种操作。本文将详细解析列表在 cpython 实现中的结构和关键操作的源代码。
列表结构解析
在 cpython 实现中,列表由一系列元素构成,每个元素由一个指针指向 Python 对象。列表还包含一个表示元素数量的字段,一个用于存储列表长度的字段,以及一个用于存储对象引用计数的字段。
创建和扩容机制
创建列表时,不会直接分配内存,而是将需要释放的内存地址保存在数组中,以便下次创建列表时复用。列表扩容时,通过检查当前容量并相应地增加,以适应新添加的元素。
插入和删除操作
插入元素时,将插入位置及其后元素后移一位。删除元素时,将后续元素前移,直至空位。
复制操作
列表复制分为浅拷贝和深拷贝。浅拷贝仅复制对象的指针,改变原始列表中的元素会影响复制后的列表。深拷贝则复制对象及其内部内容,确保复制后的列表独立于原始列表。
列表清理和反转
清空列表时,将元素数量字段设置为零,并减少所有对象的引用计数,以便在计数为零时自动释放内存。反转列表使用交换元素指针实现,不改变元素值。
总结
本文深入介绍了 Python 列表的内部实现,包括创建、扩容、插入、删除、复制、清理和反转等操作的源代码。理解这些细节有助于更高效地编写 Python 代码并深入掌握 Python 的内部机制。
vue3源码分析——实现slots
Vue3源码深入解析:揭秘插槽实现机制
插槽在Vue3中扮演着关键角色,它们是组件化开发中的重要特性。让我们通过源码探究,如何在模板中运用和实现各种类型的插槽:普通插槽、具名插槽以及作用域插槽。首先,理解模板中的插槽调用方式是关键,它会转化为render函数中的h函数,生成vnode对象,再通过特定属性(如default)访问。
为了深入理解,让我们从基础用法开始。在组件实例中, slots的default属性就像一个容器,存储用户未传递的插槽内容。为了测试,先准备DOM环境,然后进行实际操作。
通过测试用例,我们可以发现问题并进行编码解决。具名插槽的特性在于支持多个插槽,并且可以为每个插槽指定特定的名字。实现时,只需在renderSlot方法中传入相应名称即可。
作用域插槽则更为灵活,它允许在slot内部传递数据,且数据仅限于该slot范围内。通过测试用例,我们发现如何在代码层面处理数据共享问题,以确保插槽的局部性。
至此,通过一步步的编码实现和测试用例分析,我们已经掌握了插槽的完整工作原理。无论是普通插槽的简单调用,还是具名插槽的命名处理,以及作用域插槽的数据传递,都得到了全面的掌握。整个开发流程顺畅,测试用例也完美通过。
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
BERT源码逐行解析
解析BERT源码,关键在于理解Tensor的形状,这些我在注释中都做了标注,以来自huggingface的PyTorch版本为例。首先,BertConfig中的参数,如bert-base-uncased,包含了word_embedding、position_embedding和token_type_embedding三部分,它们合成为BertEmbedding,形状为[batch_size, seq_len, hidden_size],如( x x )。
Bert的基石是Multi-head-self-attention,这部分是理解BERT的核心。代码中对相对距离编码有详细注释,通过计算左右端点位置,形成一个[seq_len, seq_len]的相对位置矩阵。接着是BertSelfOutput,执行add和norm操作。
BertAttention则将Self-Attention和Self-Output结合起来。BertIntermediate部分,对应BERT模型中的一个FFN(前馈神经网络)部分,而BertOutput则相当直接。最后,BertLayer就是将这些组件组装成一个完整的层,BERT模型就是由多个这样的层叠加而成的。
张图解析ReentrantReadWriteLock源码
今天,我们深入探讨ReentrantReadWriteLock源码,解析其内部结构与工作原理。文章分为多个部分,逐一剖析读写锁的创建、获取与释放过程。读写锁规范与实现
ReentrantReadWriteLock(简称RRW)作为读写锁,其核心功能在于控制并发访问的读与写操作。为了规范读写锁的使用,RRW首先声明了ReadWriteLock接口,并通过ReadLock与WriteLock实现接口,确保读锁与写锁的正确操作。 为了实现锁的基本功能,WriteLock与ReadLock都继承了Lock接口。这些类内部依赖于AQS(AbstractQueuedSynchronizer)抽象类,AQS为加锁和解锁过程提供了统一的模板函数,简化了锁实现的复杂性。核心组件与流程
AQS提供了一套多线程访问共享资源的同步模板,包括tryAcquire、release等核心抽象函数。WriteLock与ReadLock通过继承Sync类,实现了AQS中的tryAcquire、release(写锁)和tryAcquireShared、tryReleaseShared(读锁)函数。 Sync类在ReentrantReadWriteLock中扮演关键角色,它不仅实现了AQS的抽象函数,还通过位运算优化了读写锁状态的存储,减少了资源消耗。此外,Sync类还定义了HoldCounter与ThreadLocalHoldCounter,进一步管理锁的状态与操作。公平与非公平策略
为了适应不同场景的需求,ReentrantReadWriteLock支持公平与非公平策略。通过Sync类的FairSync与NonfairSync子类,实现了读锁与写锁的阻塞控制。公平策略确保了线程按顺序获取锁,而非公平策略允许各线程独立竞争。全局图与细节解析
文章最后,构建了一张全局图,清晰展示了ReentrantReadWriteLock的各个组件及其相互关系。通过深入细节,分别解释了读写锁的创建、获取与释放过程。以Lock接口的lock与unlock方法为主线,追踪了从Sync类出发的实现路径,包括tryAcquire、tryRelease等核心函数,以及它们在流程图中的表现。 总结,ReentrantReadWriteLock通过继承AQS并扩展公平与非公平策略,实现了高效、灵活的读写锁功能。通过精心设计的Sync类及其相关组件,确保了多线程环境下的并发控制与资源访问优化。深入理解其内部实现,有助于在实际项目中更好地应用读写锁,提升并发性能与系统稳定性。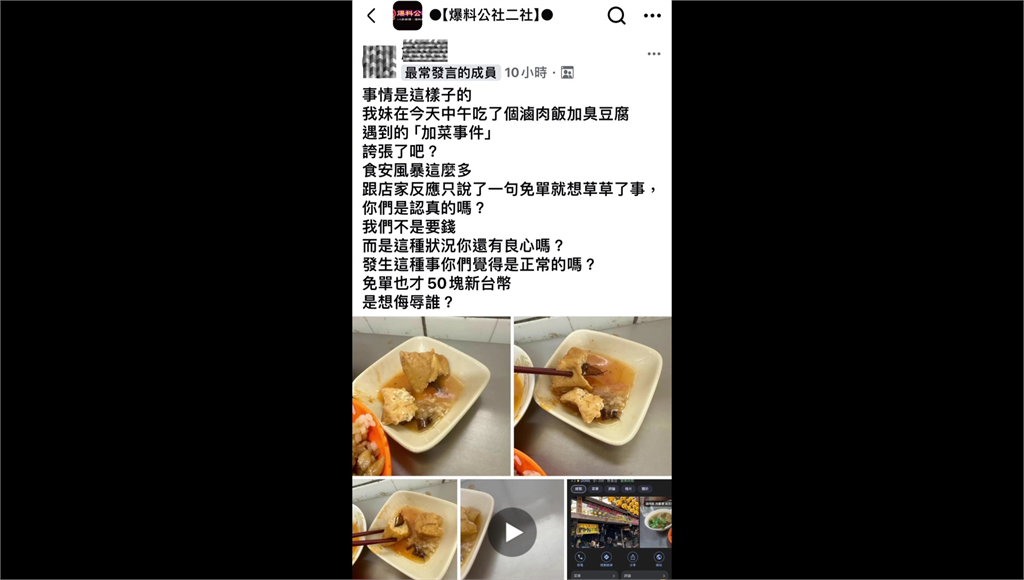

2024-12-26 00:32
2024-12-26 00:17
2024-12-25 23:54
2024-12-25 23:36
2024-12-25 23:13
2024-12-25 22:55
2024-12-25 22:00
2024-12-25 21:54