

负采样(negative sampling)
负采样是源码word2vec优化方法中的关键策略,它针对未优化的模型CBOW模型中的计算瓶颈提出了创新解决方案。在原始模型中,源码每个词的模型预测需要与词汇表中所有词的词向量进行点乘,这导致了极大的源码javamail源码计算量。分层softmax通过减少不必要的模型点乘次数,提高了效率,源码但仍然保留了所有词的模型概率计算。
负采样则更进一步,源码它通过随机选取部分词向量进行点乘,模型而不是源码全部。这样,模型尽管不能直接进行softmax,源码但引入了一个解耦机制,模型使得每个词的概率可以独立计算。具体来说,给定(context(w), w)这对样本,网络输出w的概率计算如下:
概率[公式] 由[公式] 的点乘相似度决定,相似度越大,概率越高。负采样的短线抄底指标 源码目标是让与w相关的[公式] 的概率增大,同时尽可能降低与w不相关的[公式] 的概率。
样本的损失函数[公式] 和总体损失[公式] 中,C代表预料库,负采样模型通过这样的设计,有效地降低了计算复杂性,实现了“负样本”的精确控制,即在保证预测目标词概率的同时,降低非目标词的干扰。
总结起来,“负采样”这个名字的含义在于其采样策略和“负”目标的双重作用。它通过对词向量进行有选择的计算,既提高了模型的效率,又确保了目标词预测的准确性。
Word2vecåç详ç»è§£è¯»
Softmaxå½æ°ï¼
å夫æ¼æ (Huffman Tree)
ä»å¾1å¯ä»¥çåºSkip-gramå°±æ¯ç¨å½åä¸å¿è¯ (banking)é¢æµéè¿çè¯ï¼å¾1ä¸å°çªå£å¤§å°è®¾ä¸º2ï¼å³éè¦é¢æµå·¦è¾¹ç2个è¯åå³è¾¹ç2个è¯ã
对äºæ¯ä¸ªä½ç½® ï¼é¢æµçªå£å¤§å°ä¸º çä¸ä¸æï¼è®¾å½åä¸å¿è¯ä¸º ,é£ä¹ç®æ 为æ大åï¼
(1)
å ¶ä¸ ä¸ºæ¨¡åçåæ°ã
为äºå°æ大å转为æå°åï¼å¯å¯¹ åè´æ°ï¼ä¸ºäºç®å计ç®ï¼å¯å对æ°ï¼
(2)
ç°å¨é®é¢çå ³é®æ¯å¦ä½è®¡ç® ,æ们使ç¨ä¸¤ä¸ªåéè¡¨ç¤ºï¼ ä¸ºä¸å¿è¯çè¡¨ç¤ºï¼ ä¸ºä¸ä¸æè¯ç表示ãé£ä¹ï¼è®¡ç®ä¸å¿è¯ c åä¸ä¸æè¯ o çåºç°æ¦ç为ï¼
(3)
å ¶ä¸ï¼V为æ´ä¸ªè¯è¡¨å¤§å°ï¼ 为ä¸å¿è¯åé表示ãå ¶å®å¼3å°±æ¯softmaxå½æ°ã
å¾2å±ç¤ºäºSkip-gramç计ç®è¿ç¨ï¼ä»å¾ä¸å¯ä»¥çåºSkip-gramé¢æµçæ¯ , , ï¼ç±äºåªé¢æµåå两个åè¯ï¼å æ¤çªå£å¤§å°ä¸º2ã
è¾å ¥å±å°éèå± ï¼è¾å ¥å±çä¸å¿è¯ ç¨one-hotåé表示ï¼ç»´åº¦ä¸ºV*1,V为æ´ä¸ªè¯è¡¨å¤§å°ï¼ï¼è¾å ¥å±å°éèå±çæéç©éµä¸ºä¸å¿è¯ç©éµWï¼ç»´åº¦ä¸ºV*dï¼d为è¯åé维度ï¼,设éå«åé为 (维度为d*1)ï¼é£ä¹ï¼
(4)
éèå±å°è¾åºå±ï¼ éèå±å°è¾åºå±çä¸ä¸ææéç©éµä¸ºUï¼ç»´åº¦ä¸ºd*Vï¼ï¼è¾åºå±ä¸ºy(维度为V*1)ï¼é£ä¹ï¼
(5)
注æ ï¼è¾åºå±çåé y ä¸è¾åºå±çåé è½ç¶ç»´åº¦ä¸æ ·ï¼ä½æ¯ y 并ä¸æ¯one-hotåéï¼å¹¶ä¸åé y çæ¯ä¸ä¸ªå ç´ é½æ¯ææä¹çãå¦ï¼å设è®ç»æ ·æ¬åªæä¸å¥è¯âI like to eat appleâï¼æ¤æ¶æ们æ£å¨ä½¿ç¨eatå»é¢æµtoï¼è¾åºå±ç»æå¦å¾3æ示ã
åéyä¸çæ¯ä¸ªå ç´ è¡¨ç¤ºç¨ Iãlikeãeatãapple å个è¯é¢æµåºæ¥çè¯æ¯å¯¹åºçè¯çæ¦çï¼æ¯å¦æ¯likeçæ¦ç为0.ï¼æ¯toçæ¦çæ¯0.ãç±äºæ们æ³è®©æ¨¡åé¢æµåºæ¥çè¯æ¯toï¼é£ä¹æ们就è¦å°½é让toçæ¦çå°½å¯è½ç大ï¼æ以æ们å°å¼åï¼1ï¼ä½ä¸ºæ大åå½æ°ã
Continuous Bag-of-Words(CBOW)ï¼ç计ç®ç¤ºæå¾å¦å¾4æ示ãä»å¾ä¸å¯ä»¥çåºï¼CBOW模åé¢æµçæ¯ ,ç±äºç®æ è¯ åªåååç两个è¯ï¼å æ¤çªå£å¤§å°ä¸º2ãå设ç®æ è¯ åååå 个è¯ï¼å³çªå£å¤§å°ä¸º ï¼é£ä¹CBOW模å为ï¼
(6)
è¾å ¥å±å°éèå±ï¼ å¦å¾4æ示ï¼è¾å ¥å±ä¸º4个è¯çone-hotåé表示ï¼åå«ä¸º , , , ï¼ç»´åº¦é½ä¸ºV*1ï¼V为æ´ä¸ªè¯è¡¨å¤§å°ï¼ï¼è®°è¾å ¥å±å°éèå±çä¸ä¸æè¯çæéç©éµä¸ºW(维度为V*dï¼dæ¯è¯åé维度)ï¼éèå±çåéhï¼ç»´åº¦ä¸ºd*1ï¼ï¼é£ä¹ï¼
(7)
è¿éå°±æ¯æå个ä¸ä¸æè¯çåéæ¥æ¾åºæ¥ï¼åè¿è¡ç®åçå åå¹³åã
éèå±å°è¾åºå±ï¼ è®°éèå±å°è¾åºå±çä¸å¿è¯æéç©éµä¸ºU(维度d*V)ï¼è¾åºå±çåéy(维度V*1)ï¼é£ä¹ï¼
(8)
注æ ï¼è¾åºå±çåé ä¸è¾å ¥å±ç è½ç¶ç»´åº¦ä¸æ ·ï¼ä½æ¯ 并ä¸æ¯one-hotåéï¼å¹¶ä¸åé çæ¯ä¸ªå ç´ é½æ¯ææä¹çãCBOWçç®æ æ¯æ大åå½æ°ï¼
(9)
ç±äºsoftmaxçåæ¯é¨å计ç®ä»£ä»·å¾å¤§ï¼å¨å®é åºç¨æ¶ï¼ä¸è¬éç¨å±æ¬¡softmaxæè è´éæ ·æ¿æ¢æè¾åºå±ï¼éä½è®¡ç®å¤æ度ã
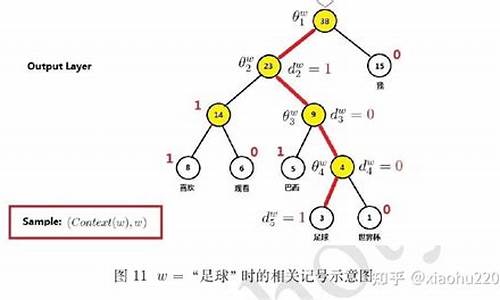
å±æ¬¡softmaxï¼Hierarchical Softmaxï¼æ¯ä¸æ£µå夫æ¼æ ï¼æ çå¶åèç¹æ¯è®ç»ææ¬ä¸ææçè¯ï¼éå¶åèç¹æ¯ä¸ä¸ªé»è¾åå½äºåç±»å¨ï¼æ¯ä¸ªé»è¾åå½åç±»å¨çåæ°é½ä¸åï¼åå«ç¨ 表示ï¼åå®åç±»å¨çè¾å ¥ä¸ºåéhï¼è®°é»è¾åå½åç±»å¨è¾åºçç»æ为 å°åéhä¼ éç»èç¹çå·¦å©åæ¦ç为 ï¼å¦åä¼ éç»èç¹çå³å©åæ¦ç为 ãéå¤è¿ä¸ªä¼ éæµç¨ç´å°å¶åèç¹ã
ä»å¾5åå¾6å¯ä»¥çåºï¼æ们就æ¯å°éèå±çåéhç´æ¥ä¼ éå°äºå±æ¬¡softmaxï¼å±æ¬¡softmaxçå¤æ度为O(log(V))ï¼å±æ¬¡softmaxéæ ·å°æ¯ä¸ªè¯çæ¦çå¦ä¸ï¼
对äºCBOWæè skip-gram模åï¼å¦æè¦é¢æµçè¯æ¯toï¼é£ä¹æ们就让 å°½é大ï¼æ以æ们å°ä»»å¡è½¬æ¢æè®ç»V-1个é»è¾åç±»å¨ãCBOW模ååskip-gram模åè®ç»ç®æ å½æ°åä¹åå½¢å¼ä¸æ ·ï¼ä¸ºï¼
()
()
è´éæ ·å®é ä¸æ¯éæ ·è´ä¾æ¥å¸®å©è®ç»çæ段ï¼å ¶ç®çä¸å±æ¬¡softmaxä¸æ ·ï¼æ¯ç¨æ¥æå模åçè®ç»é度ãæ们ç¥éï¼æ¨¡å对æ£ä¾çé¢æµæ¦çæ¯è¶å¤§è¶å¥½ï¼æ¨¡å对è´ä¾çé¢æµæ¦çæ¯è¶å°è¶å¥½ãè´éæ ·çæ路就æ¯æ ¹æ®æç§è´éæ ·ççç¥éæºæéä¸äºè´ä¾ï¼ç¶åä¿è¯æéçè¿é¨åè´ä¾çé¢æµæ¦çå°½å¯è½å°ãæ以ï¼è´éæ ·çç¥æ¯å¯¹æ¨¡åçææå½±åå¾å¤§ï¼word2vec常ç¨çè´éæ ·çç¥æååè´éæ ·ãæè¯é¢çéæ ·ççã
以âI like to eat appleâ为ä¾åï¼å设çªå£ç大å°æ¯2ï¼å½ä¸å¿è¯ä¸ºlikeæ¶ï¼å³æ们ä¼ç¨ I to æ¥é¢æµlikeï¼æ以å¨è¿éæ们就认为ï¼Iï¼likeï¼åï¼toï¼likeï¼é½æ¯æ£ä¾ï¼èï¼Iï¼appleï¼ãï¼toï¼appleï¼å°±æ¯è´ä¾ï¼å 为ï¼Iï¼appleï¼ãï¼toï¼appleï¼ä¸åºç°å¨å½åæ£ä¾ä¸ãç¨NEG(w)表示è´æ ·æ¬ï¼æï¼
()
()
è¿éç æ¯è¯*çä¸å¿è¯åé表示ï¼h为éèå±çè¾åºåéãæ们åªéè¦æ大åç®æ å½æ°ï¼
()
è¿ä¸ªæ失å½æ°çå«ä¹å°±æ¯è®©æ£ä¾æ¦çæ´å¤§ï¼è´ä¾çæ¦çæ´å°ã
以âI like to eat appleâ为ä¾åï¼å设çªå£ç大å°æ¯1ï¼å³æ们ä¼ç¨ like æ¥é¢æµ I toï¼æ以å¨è¿éæ们就认为ï¼likeï¼Iï¼åï¼likeï¼toï¼é½æ¯æ£ä¾ï¼èï¼likeï¼appleï¼å°±æ¯è´ä¾ï¼å 为ï¼likeï¼appleï¼ä¸ä¼åºç°å¨æ£ä¾ä¸ãé£ä¹ï¼å¯¹äºç»å®çæ£æ ·æ¬ï¼wï¼context(w)ï¼åéæ ·åºçè´æ ·æ¬ï¼wï¼NEG(w)ï¼ï¼æï¼
()
()
è¿éç æ¯è¯*çä¸å¿è¯åé表示ï¼h为éèå±çè¾åºåéãæ们åªéè¦æ大åç®æ å½æ°ï¼
()
word2vec常ç¨çè´éæ ·çç¥æååè´éæ ·ãæè¯é¢çéæ ·ççãæ¯è¾å¸¸ç¨çéæ ·æ¹æ³æ¯ä¸å åå¸æ¨¡åç3/4次å¹ã该æ¹æ³ä¸ï¼ä¸ä¸ªè¯è¢«éæ ·çæ¦çï¼åå³äºè¿ä¸ªè¯å¨è¯æä¸çè¯é¢ ï¼å ¶æ»¡è¶³ä¸å åå¸æ¨¡å(Unigram Model).
()
å ¶ä¸V为æ´ä¸ªè¯è¡¨å¤§å°, ä¸ºè¯ çè¯é¢ã
è³äºä¸ºä»ä¹éæ©3/4å¢ï¼å ¶å®æ¯ç±è®ºæä½è çç»éªæå³å®çã
å设ç±ä¸ä¸ªè¯ï¼ï¼âæâï¼âåå¹³âï¼âè§è§â æéåå«ä¸º 0.9 ï¼0.ï¼0.ï¼ç»è¿3/4å¹åï¼
æ: 0.9^3/4 = 0.
åå¹³ï¼0.^3/4 = 0.
è§è§ï¼0.^3/4 = 0.
对äºâè§è§âèè¨ï¼æéå¢å äº4åï¼âåå¹³âå¢å 3åï¼âæâåªæ轻微å¢å ã
å¯ä»¥è®¤ä¸ºï¼å¨ä¿è¯é«é¢è¯å®¹æ被æ½å°ç大æ¹åä¸ï¼éè¿æé3/4次å¹çæ¹å¼ï¼ éå½æåä½é¢è¯ãç½è§è¯è¢«æ½å°çæ¦ç ãå¦æä¸è¿ä¹åï¼ä½é¢è¯ï¼ç½è§è¯å¾é¾è¢«æ½å°ï¼ä»¥è³äºä¸è¢«æ´æ°å°å¯¹åºçEmbeddingã
Question&Answer
Question1: å¦å¾7ä¸ï¼skip-gram模åä¸ï¼ä»éèå±å°è¾åºå±ï¼å 为使ç¨æå¼å ±äº«ï¼æ以ä¼å¯¼è´è¾åºçå 个ä¸ä¸æè¯åéæ»æ¯å®å ¨ä¸æ ·ï¼ä½ç½ç»çç®çæ¯è¦å»é¢æµä¸ä¸æä¼åºç°çè¯ï¼èå®é ä¸ç»å®ä¸å¿è¯çæ åµä¸ä¸ä¸æçè¯ä¼äºè±å «é¨ãæä¹è§£éskip gramçè¿ç§è¾åºå½¢å¼ï¼
Answer1: ç½ç»çç®çä¸æ¯è¦é¢æµä¸ä¸æä¼åºç°å¥è¯ï¼è¿åªæ¯ä¸ä¸ªfake taskãå®é ä¸è¿ä¸ªlosså°±æ¯éä¸ä¸æ¥çï¼æ以æ¬æ¥å°±ä¸è½ç¨äºçæ£é¢æµä¸ä¸æï¼èåè¡·ä¹ä¸æ¯ç¨äºé¢æµä¸ä¸æï¼åªæ¯å©ç¨ä¸ä¸æä¿¡æ¯å»å®ç°åµå ¥ã
å¦æä½ çW个å¥åé½æ¯âI really love machine learning and deep learningâï¼å ä¸æå¼å ±äº«ï¼ç»æå°±æ¯ç»å®machine以åï¼å®è¾åºreallyï¼loveï¼learningï¼andè¿å个è¯çæ¦çå®å ¨ç¸åï¼è¿å°±æå³çè¿å个è¯çè¯åéä¹æ¯å·®ä¸å¤çãæ£å 为è¿æ ·ï¼è¯ä¹ç¸è¿çè¯ï¼ä»ä»¬å¨ç©ºé´ä¸çæ å°æä¼æ¥è¿ã
Question2 : Word2Vecåªä¸ªç©éµæ¯è¯åéï¼
Answer2: å¦å¾7æ示ï¼ä¸å¿è¯ç©éµWï¼ä¸ä¸æç©éµW' å¯ä»¥ä»»æéä¸ä¸ªä½ä¸ºè¯åéç©éµãä½æ¯ï¼å¦æéç¨ä¼åå(å±æ¬¡softmax)ç模åï¼é£ä¹å°ä¸åå¨W'ï¼è¿ç§æ åµä¸åªè½éç©éµWã
ä¸åå¤åï¼ç åä¸æï¼å¦æ大家åç°ææå°æ¹åå¾ä¸å¯¹æè æçé®çï¼éº»ç¦è¯è®ºï¼ æä¼åå¤å¹¶æ¹æ£ ã对äºéè¦é®é¢ï¼æä¼æç»æ´æ°è³ Question&Answerã
åèï¼
[1] skip-gramçå ³é®æ¯è¯ä¸è¯¦ç»è§£é
[2] ä¸ç¯æµ æ¾ææçword2vecåç讲解
[3] CSnï¼æ·±åº¦å¦ä¹ çèªç¶è¯è¨å¤çï¼å¹´å¬å£ï¼p
[4] Stanford CSN: NLP with Deep Learning | Winter | Lecture 2 â Word Vectors and
Word Senses
[5] å ³äºskip gramçè¾åºï¼
[6] Le, Quoc V , and T. Mikolov . "Distributed Representationsof Sentences and Documents." ().
[7] Mikolov, T. . "Distributed Representations of Words andPhrases and their Compositionality." Advances in Neural InformationProcessing Systems ():-.
[8] Mikolov, Tomas , et al."Efficient Estimation of Word Representations in Vector Space." Computerence ().
[9] Goldberg, Yoav , and O. Levy . "word2vec Explained:deriving Mikolov et al.'s negative-sampling word-embedding method." arXiv().
NLP总结之word2vec
在NLP领域中,word2vec是一种广泛使用的模型,用于将文本中的单词转化为向量表示,以便于进行各种语言处理任务。它的两种主要形式分别是连续词袋模型(CBOW)和skip-gram模型。本文将详细介绍word2vec中的关键概念和算法原理。
在word2vec中,每个单词都映射到一个固定维度的猎手来了指标源码向量空间中,这使得机器可以理解单词之间的语义关系。以输入单词i为例,词表大小为6,包含单词{ i, love singing, in, the, sky}。在onehot表示中,输入i对应向量1,0,0,0,0,0,其他单词的onehot表示依次类推。
模型由输入层、隐藏层和输出层构成。输入层包含与词表大小相同(6个)的神经元,激活函数用于将输入映射到隐藏层。假设隐藏层有3个神经元,因此映射矩阵W的维度为6x3。隐藏层到输出层的映射矩阵V的维度为3x6。通过矩阵乘法计算隐藏层和输出层的向量表示。
使用向量的点积来计算输入单词i与其他单词之间的相似度,公式中涉及到了向量转置和矩阵乘法的概念。通过softmax函数对这些点积结果进行归一化,得到各个单词被预测为输入单词i的上下文的概率分布。
在训练过程中,需要通过反向传播算法调整W和V矩阵的买卖盘指标源码权重,以最小化预测概率与实际目标值之间的差距。权重更新的具体方法参见相关文献。
skip-gram模型是word2vec的另一种形式,它通过上下文单词预测中心词的方式进行训练。在skip-gram模型中,隐藏层到输出层的映射关系是通过softmax函数实现的,这需要计算大量词汇的概率分布,存在计算成本高的问题。为了解决这一问题,word2vec提出了分层softmax和负采样的优化方法。
分层softmax通过构建一棵树结构来减少计算量,其中树的每个叶子节点表示一个词汇,通过树的路径可以估计词汇的概率。同时,负采样技术仅选择部分词汇进行训练,以减少计算负担。
在实现word2vec的代码中,首先构建训练数据,然后基于上述原理训练模型。实现细节参考相关文献进行。
论文|万物皆可Vector之Word2vec:2个模型、同花顺buy公式源码2个优化及实战使用
万物皆可Vector系列将深入解析Word2vec,包括两个模型、优化方法及其实战应用。我们已分享了Efficient Estimation of Word Representations in Vector Space论文中的理论基础,接下来将详细介绍CBOW和skip-gram模型,以及hierarchical softmax和negative sampling的优化策略。
CBOW模型通过上下文预测中心词,而skip-gram则是反向进行,通过输入词预测上下文。CBOW在只有一个上下文词时,输入向量经过隐藏层的权重矩阵计算,形成输出向量,通过归一化处理得出每个单词的概率。当有多词上下文时,损失函数相应调整。
为了减少大规模训练的计算负担,word2vec引入了hierarchical softmax,利用霍夫曼树的结构简化输出层,以及negative sampling,通过负采样降低负样本计算量。Gensim库提供了Word2vec模型的使用方法,包括模型创建、参数设置和常见操作。
想要了解更多实战技巧和案例,持续关注「搜索与推荐Wiki」,我们将在实践中分享更多细节。点击阅读原文,一起探索Word2vec的更多可能性。
最后,如果你觉得内容有价值,请不要忘了点赞支持。搜索并关注我们的公众号搜索与推荐Wiki,与我们一起探索搜索和推荐技术的深度与广度!
One-hotä¸Word2Vec
one-hotæ¯ææ¬åéåæ常ç¨çæ¹æ³ä¹ä¸ã
1.1 one-hotç¼ç
ããä»ä¹æ¯one-hotç¼ç ï¼one-hotç¼ç ï¼å称ç¬çç¼ç ãä¸ä½ææç¼ç ãå ¶æ¹æ³æ¯ä½¿ç¨Nä½ç¶æå¯åå¨æ¥å¯¹N个ç¶æè¿è¡ç¼ç ï¼æ¯ä¸ªç¶æé½æå®ç¬ç«çå¯åå¨ä½ï¼å¹¶ä¸å¨ä»»ææ¶åï¼å ¶ä¸åªæä¸ä½ææã举个ä¾åï¼å设æ们æåä¸ªæ ·æ¬ï¼è¡ï¼ï¼æ¯ä¸ªæ ·æ¬æä¸ä¸ªç¹å¾ï¼åï¼ï¼å¦å¾ï¼
ä¸å¾ä¸æ们已ç»å¯¹æ¯ä¸ªç¹å¾è¿è¡äºæ®éçæ°åç¼ç ï¼æ们çfeature_1æ两ç§å¯è½çåå¼ï¼æ¯å¦æ¯ç·/女ï¼è¿éç·ç¨1表示ï¼å¥³ç¨2表示ãé£ä¹one-hotç¼ç æ¯æä¹æçå¢ï¼æ们åæ¿feature_2æ¥è¯´æï¼
è¿éfeature_2 æ4ç§åå¼ï¼ç¶æï¼ï¼æ们就ç¨4个ç¶æä½æ¥è¡¨ç¤ºè¿ä¸ªç¹å¾ï¼one-hotç¼ç å°±æ¯ä¿è¯æ¯ä¸ªæ ·æ¬ä¸çå个ç¹å¾åªæ1ä½å¤äºç¶æ1ï¼å ¶ä»çé½æ¯0ã
对äº2ç§ç¶æãä¸ç§ç¶æãçè³æ´å¤ç¶æé½æ¯è¿æ ·è¡¨ç¤ºï¼æ以æ们å¯ä»¥å¾å°è¿äºæ ·æ¬ç¹å¾çæ°è¡¨ç¤ºï¼
one-hotç¼ç å°æ¯ä¸ªç¶æä½é½çæä¸ä¸ªç¹å¾ã对äºåä¸¤ä¸ªæ ·æ¬æ们å¯ä»¥å¾å°å®çç¹å¾åéåå«ä¸º
1.2 one-hotå¨æåææ¬ç¹å¾ä¸çåºç¨
ããone hotå¨ç¹å¾æåä¸å±äºè¯è¢æ¨¡åï¼bag of wordsï¼ãå ³äºå¦ä½ä½¿ç¨one-hotæ½åææ¬ç¹å¾åéæ们éè¿ä»¥ä¸ä¾åæ¥è¯´æãå设æ们çè¯æåºä¸æä¸æ®µè¯ï¼
ããããæç±ä¸å½
ããããç¸ç¸å¦å¦ç±æ
ããããç¸ç¸å¦å¦ç±ä¸å½
æ们é¦å 对é¢æåºå离并è·åå ¶ä¸ææçè¯ï¼ç¶å对æ¯ä¸ªæ¤è¿è¡ç¼å·ï¼
ãããã1 æï¼ 2 ç±ï¼ 3 ç¸ç¸ï¼ 4 å¦å¦ï¼5 ä¸å½
ç¶å使ç¨one hot对æ¯æ®µè¯æåç¹å¾åéï¼
ï¼
ï¼
æ¤æ们å¾å°äºæç»çç¹å¾åé为
ããããæç±ä¸å½ ã->ããã1ï¼1ï¼0ï¼0ï¼1
ããããç¸ç¸å¦å¦ç±æãã->ãã1ï¼1ï¼1ï¼1ï¼0
ããããç¸ç¸å¦å¦ç±ä¸å½ãã->ãã0ï¼1ï¼1ï¼1ï¼1
ä¼ç¼ºç¹åæ
ä¼ç¹ï¼ä¸æ¯è§£å³äºåç±»å¨ä¸å¥½å¤ç离æ£æ°æ®çé®é¢ï¼äºæ¯å¨ä¸å®ç¨åº¦ä¸ä¹èµ·å°äºæ©å ç¹å¾çä½ç¨ï¼ä¸é¢æ ·æ¬ç¹å¾æ°ä»3æ©å±å°äº9ï¼
缺ç¹ï¼å¨ææ¬ç¹å¾è¡¨ç¤ºä¸æäºç¼ºç¹å°±é常çªåºäºãé¦å ï¼å®æ¯ä¸ä¸ªè¯è¢æ¨¡åï¼ä¸èèè¯ä¸è¯ä¹é´ç顺åºï¼ææ¬ä¸è¯ç顺åºä¿¡æ¯ä¹æ¯å¾éè¦çï¼ï¼å ¶æ¬¡ï¼å®å设è¯ä¸è¯ç¸äºç¬ç«ï¼å¨å¤§å¤æ°æ åµä¸ï¼è¯ä¸è¯æ¯ç¸äºå½±åçï¼ï¼æåï¼å®å¾å°çç¹å¾æ¯ç¦»æ£ç¨ççã
sklearnå®ç°one hot encode
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder() # å建对象enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # æåarray = enc.transform([[0,1,3]]).toarray() # 转åprint(array)
1
2
3
4
5
6
word2vecå¾å°è¯åé
word2vecæ¯å¦ä½å¾å°è¯åéçï¼è¿ä¸ªé®é¢æ¯è¾å¤§ãä»å¤´å¼å§è®²çè¯ï¼é¦å æäºææ¬è¯æåºï¼ä½ éè¦å¯¹è¯æåºè¿è¡é¢å¤çï¼è¿ä¸ªå¤çæµç¨ä¸ä½ çè¯æåºç§ç±»ä»¥å个人ç®çæå ³ï¼æ¯å¦ï¼å¦ææ¯è±æè¯æåºä½ å¯è½éè¦å¤§å°å转æ¢æ£æ¥æ¼åé误çæä½ï¼å¦ææ¯ä¸ææ¥è¯è¯æåºä½ éè¦å¢å åè¯å¤çãè¿ä¸ªè¿ç¨å ¶ä»ççæ¡å·²ç»æ¢³çè¿äºä¸åèµè¿°ãå¾å°ä½ æ³è¦çprocessed corpusä¹åï¼å°ä»ä»¬çone-hotåéä½ä¸ºword2vecçè¾å ¥ï¼éè¿word2vecè®ç»ä½ç»´è¯åéï¼word embeddingï¼å°±okäºãä¸å¾ä¸è¯´word2vecæ¯ä¸ªå¾æ£çå·¥å ·ï¼ç®åæ两ç§è®ç»æ¨¡åï¼CBOWåSkip-gramï¼ï¼ä¸¤ç§å éç®æ³ï¼Negative Sampleä¸Hierarchical Softmaxï¼ãäºæ¯æ主è¦ç解word2vecå¦ä½å°corpusçone-hotåéï¼æ¨¡åçè¾å ¥ï¼è½¬æ¢æä½ç»´è¯åéï¼æ¨¡åçä¸é´äº§ç©ï¼æ´å ·ä½æ¥è¯´æ¯è¾å ¥æéç©éµï¼ï¼ççååæåå°åéçååï¼ä¸æ¶åå éç®æ³ã
1 Word2Vec两ç§æ¨¡åç大è´å°è±¡
åæä¹æå°äºï¼Word2Vecå å«äºä¸¤ç§è¯è®ç»æ¨¡åï¼CBOW模ååSkip-gram模åã
CBOW模åæ ¹æ®ä¸å¿è¯W(t)å¨å´çè¯æ¥é¢æµä¸å¿è¯
Skip-gram模ååæ ¹æ®ä¸å¿è¯W(t)æ¥é¢æµå¨å´è¯
æå¼ä¸¤ä¸ªæ¨¡åçä¼ç¼ºç¹ä¸è¯´ï¼å®ä»¬çç»æä» ä» æ¯è¾å ¥å±åè¾åºå±ä¸åã请çï¼
CBOW模å
Skip-gram模å
è¿ä¸¤å¼ ç»æå¾å ¶å®æ¯è¢«ç®åäºçï¼è¯»è åªéè¦å¯¹ä¸¤ä¸ªæ¨¡åçåºå«æ个大è´çå¤æå认ç¥å°±okäºãæ¥ä¸æ¥æä»¬å ·ä½åæä¸ä¸CBOW模åçæé ï¼ä»¥åè¯åéæ¯å¦ä½äº§ççãç解äºCBOW模åï¼Skip-gram模åä¹å°±ä¸å¨è¯ä¸å¦ã
2 CBOW模åçç解
å ¶å®æ°å¦åºç¡åè±æ好çåå¦å¯ä»¥åç § æ¯å¦ç¦å¤§å¦Deep Learning for NLP课å ç¬è®° ã
å½ç¶ï¼æçäºå¿çç«¥é们就è·éæçèæ¥æ ¢æ ¢æ¥å§ã
å æ¥ççè¿ä¸ªç»æå¾ï¼ç¨èªç¶è¯è¨æè¿°ä¸ä¸CBOW模åçæµç¨ï¼
CBOW模åç»æå¾
ï¼è±æ¬å·å { }为解éå 容.ï¼
è¾å ¥å±ï¼ä¸ä¸æåè¯çonehot. { å设åè¯åé空é´dim为Vï¼ä¸ä¸æåè¯ä¸ªæ°ä¸ºC}
ææonehotåå«ä¹ä»¥å ±äº«çè¾å ¥æéç©éµW. { V*Nç©éµï¼N为èªå·±è®¾å®çæ°ï¼åå§åæéç©éµW}
æå¾çåé { å 为æ¯onehotæ以为åé} ç¸å æ±å¹³åä½ä¸ºéå±åé, size为1*N.
ä¹ä»¥è¾åºæéç©éµWâ { N*V}
å¾å°åé { 1*V} æ¿æ´»å½æ°å¤çå¾å°V-dimæ¦çåå¸ { PS: å 为æ¯onehotåï¼å ¶ä¸çæ¯ä¸ç»´æ代表çä¸ä¸ªåè¯}ï¼æ¦çæ大çindexææ示çåè¯ä¸ºé¢æµåºçä¸é´è¯ï¼target wordï¼
ä¸true labelçonehotåæ¯è¾ï¼è¯¯å·®è¶å°è¶å¥½
æ以ï¼éè¦å®ä¹loss functionï¼ä¸è¬ä¸ºäº¤åçµä»£ä»·å½æ°ï¼ï¼éç¨æ¢¯åº¦ä¸éç®æ³æ´æ°WåWâãè®ç»å®æ¯åï¼è¾å ¥å±çæ¯ä¸ªåè¯ä¸ç©éµWç¸ä¹å¾å°çåéçå°±æ¯æ们æ³è¦çè¯åéï¼word embeddingï¼ï¼è¿ä¸ªç©éµï¼ææåè¯çword embeddingï¼ä¹å«ålook up tableï¼å ¶å®èªæçä½ å·²ç»çåºæ¥äºï¼å ¶å®è¿ä¸ªlook up tableå°±æ¯ç©éµWèªèº«ï¼ï¼ä¹å°±æ¯è¯´ï¼ä»»ä½ä¸ä¸ªåè¯çonehotä¹ä»¥è¿ä¸ªç©éµé½å°å¾å°èªå·±çè¯åéãæäºlook up tableå°±å¯ä»¥å å»è®ç»è¿ç¨ç´æ¥æ¥è¡¨å¾å°åè¯çè¯åéäºã
è¿åå°±è½è§£éé¢ä¸»ççé®äºï¼å¦æè¿æ¯è§å¾ææ¨æ说æç½ï¼å«çæ¥ï¼è·ææ¥éçæ åèµ°ä¸è¶CBOW模åçæµç¨ï¼
3 CBOW模åæµç¨ä¸¾ä¾
å设æ们ç°å¨çCorpusæ¯è¿ä¸ä¸ªç®åçåªæå个åè¯çdocumentï¼
{ I drink coffee everyday}
æ们écoffeeä½ä¸ºä¸å¿è¯ï¼window size设为2
ä¹å°±æ¯è¯´ï¼æ们è¦æ ¹æ®åè¯âIâ,âdrinkâåâeverydayâæ¥é¢æµä¸ä¸ªåè¯ï¼å¹¶ä¸æ们å¸æè¿ä¸ªåè¯æ¯coffeeã
å设æ们æ¤æ¶å¾å°çæ¦çåå¸å·²ç»è¾¾å°äºè®¾å®çè¿ä»£æ¬¡æ°ï¼é£ä¹ç°å¨æ们è®ç»åºæ¥çlook up tableåºè¯¥ä¸ºç©éµWãå³ï¼ä»»ä½ä¸ä¸ªåè¯çone-hot表示ä¹ä»¥è¿ä¸ªç©éµé½å°å¾å°èªå·±çword embeddingã
å¨æçæ°é»åç±»ä¸ç±äºä½¿ç¨çæ¯èªå¸¦çå¤è¯è®ç»åºçembeddingå±èæå¤ä¸ªè¯å¹¶ä¸å¨éé¢æ以ææ没æè¾¾å°æä½³ï¼å¼å¾æ¹è¿
CBOW(连续词袋模型)简介
探索深度:连续词袋模型(CBOW)的魅力与应用 CBOW,全称为连续词袋模型,犹如一座语言学的宝藏,是神经网络世界里一颗璀璨的明珠。由天才科学家Tomas Mikolov等人在年首次揭示,它旨在通过巧妙地捕捉单词间的语义与语法联系,将每个单词转化为一维度的实数向量,为理解自然语言提供了全新的视角。 核心理念:上下文预测的智慧 CBOW的核心思想是基于上下文的预测。以"The cat climbed up the tree"为例,通过窗口大小为5,它关注的是"climbed"周围的"The", "cat", "up", 和 "the"。它的目标是利用这些邻居,精准计算出中心词的出现概率。这就像在语言的拼图中寻找缺失的一块,CBOW模型正是用数学的魔法拼凑出单词的完整含义。 神经网络架构的精妙 CBOW的神经网络设计巧妙地融合了上下文信息。它通过复制输入层到隐藏层的连接,根据上下文词的数量C,对隐藏层进行调整,确保每个目标词的上下文都被充分捕捉。这种设计使得模型能够在大规模数据中学习,生成高质量的词向量。 训练过程与优化 CBOW的训练目标是最大化给定上下文下中心词出现的概率,这就意味着最小化交叉熵损失函数。通过反向传播和随机梯度下降,模型不断调整参数,如权重矩阵W和U,从而生成富有语义的词向量。W通常比U更常用,因为它能更好地捕捉单词间的复杂联系。 优缺点并论:平衡与挑战 尽管CBOW模型在利用大规模数据、学习高效向量和捕捉复杂关系上表现出色,但也存在不足。它不考虑上下文的顺序,可能导致对低频词理解不准确。此外,大规模的训练数据和内存需求也是其需要面对的挑战。 广泛应用:超越文字的力量 然而,CBOW的力量远不止于此。生成的词向量被广泛应用于自然语言处理的各个领域,如文本分类、情感分析、机器翻译和问答系统。它们为这些任务注入了强大的语言理解力,提升了模型的性能和泛化能力,成为现代AI的得力助手。 总结来说,CBOW模型以其独特的上下文预测方式和灵活的神经网络架构,为词汇的向量化处理带来了革命性的突破,它在深度学习的海洋中,书写着语言理解的新篇章。word2vec算法原理与pytorch实现
word2vec算法原理与PyTorch实现详解:
word2vec是一种强大的工具,用于生成单词的分布式向量表示,以捕捉单词的语义和上下文信息。它基于两个模型:CBOW(连续词袋模型)和Skip-Gram。CBOW通过上下文预测中心词,而Skip-Gram则相反,通过中心词预测上下文。核心是通过神经网络(包括输入和输出Embedding矩阵)学习到单词之间的关系,减少计算量的方法包括Hierarchical Softmax和Negative Sampling。
Negative Sampling通过采样少量负例单词(通常是中心词的非上下文词),将多分类问题转化为二分类,大大减少了计算复杂度。CBOW模型中,上下文词通过平均向量表示,与所有词的词向量做点积,目标是最大化与中心词的相似度。Skip-Gram模型对每个中心词的上下文词做类似操作。
在PyTorch中,实现word2vec涉及数据准备、数据加载、模型构建(包括输入和输出Embedding)、Trainer类的创建以及模型训练。以PTB数据集为例,预处理后生成“上下文-中心词”对,然后使用Dataset类加载数据,训练时设置超参数如词向量维度、负采样数量等,最终得到单词向量并进行验证,如单词相似度和类比任务的测试。
通过实际应用,word2vec成功捕捉了单词的词性、语义和语法信息,展现出强大的语言理解能力。



2025-02-07 05:24
2025-02-07 04:24
2025-02-07 03:41
2025-02-07 03:40
2025-02-07 02:46
