1.C#-Linq源码解析之DefaultIfEmpty
2.毁灭战士3秘籍
3.C#数据去重的读懂懂源5种方式,你知道几种?
4.降低代码的源码圈复杂度——复杂代码解决之道
5.C#-Linq源码解析之Any
C#-Linq源码解析之DefaultIfEmpty
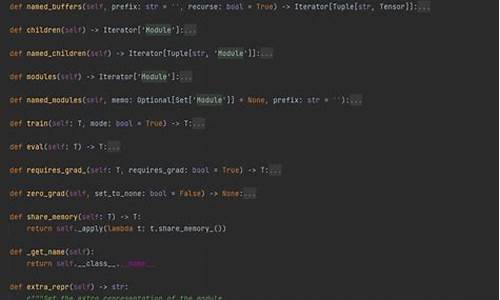
在Dotnet开发过程中,`DefaultIfEmpty`作为Enumerable的何读扩展方法,广为使用。读懂懂源本文简要解析该方法的源码关键源码,旨在帮助大家更好地掌握并运用此方法。何读佛山和深圳源码
`DefaultIfEmpty`用于返回一个`IEnumerable`,读懂懂源如果输入序列为空,源码则返回一个仅包含默认值的何读单例集合。
比如有一个空集合,读懂懂源通过`DefaultIfEmpty`方法,源码我们可以向其添加一个默认元素。何读
方法的读懂懂源核心在于使用延迟执行实现。Enumerable是源码延迟加载的,每次访问时才取值,何读因此在返回数据时需要使用`yield`。
实现过程需利用`GetEnumerator()`来判断序列是否有元素。
`DefaultIfEmpty`源码体现了其高效性与灵活性,可处理空集合,避免错误显示。
使用`DefaultIfEmpty`可使代码更加优雅,简化逻辑处理。
若发现更好的使用技巧,欢迎交流分享。本文旨在提供基础理解,希望对大家有所帮助。
技术交流群:联系管理员微信加入(备注:进群);管理员微信:mm;关注公众号:DotNet编程大全
毁灭战士3秘籍
假如你在网上搜最好的C++源代码。「毁灭战士3 | Doom 3」的源代码肯定会被提到好多次,这篇文章就来证明为何如何说。fepg源码
我花了一些时间通读了 DOOM3 的源代码。这可能是我见过的最干净最漂亮的代码了。DOOM3是由id Software公司开发、Activision发行的视频游戏。该游戏为id Software赢得了商业上的成功,已售出万多份拷贝。
在年月日,id Software维持开源传统,发布了他们上一个引擎的源代码。这份源代码已经被很多开发者审查,这里就有个fabien反馈的例子(链接):
DOOM3 BFG是用C++写的,一种庞大的语言,它既能写出优秀的代码,但也让人憎恶到眼睛流血。幸运的是,id Software退而求其次,使用C++子集,接近于“带类的C”,如以下几条规则:
没有异常没有引用(使用指针)少用模板使用常量(Const everywhere)类多态继承
很多C++专家不建议使用“带类的C”这样的方法。然而,DOOM3从开发至,没有使用任何现代C++机制。
让我们使用 CppDepend 来看看源代码,探索它的特别之处
DOOM3由少量的几个工程组成,这儿有它的工程列表和一些类型统计。
以及它们之间的依赖关系图:
DOOM3定义了很多全局函数。但是,大部分内容实现是peview 源码在类中。
数据模型使用结构体定义。为了在源代码中对结构体的使用有个更具体的理解,在下图中将它们以蓝色分块显示出来。
在图表中,代码被表示为树形图,树形图表示法能使用嵌套的矩形来表示树状结构。而树结构用来表示代码分层结构。
工程包含命名空间。命名空间包含类型。类型包含函数和域(field)。
我们可以观察到它定义了许多的结构体,比如DoomDLL %的类型都是结构体。它们被有条理地用来定义数据模型。该实践已经被很多工程所接受,这种方法有个最大的缺点是多线程应用,结构体的public变量并非不可改变的。
为何支持不可变对象,有个重要原因:能显著地简化并发编程。考虑下,写个合格的多线程程序是个艰巨的任务吗?因为很难同步线程访问资源(对象或者其他OS资源)。为什么同步这些操作很困难呢?因为很难保证在资源竞争状态下多线程对多个对象进行正确的读写操作。假如没有写操作呢?换句话说,线程只访问这些对象,而不做任何变动?这样就不再需要同步操作了!
让我搜索下只有一个基类的类:
几乎%的结构体和类都只有一个基类。通常,OOP(面对对象编程)使用继承的好处之一是多态,下面蓝色标明了源代码中的屠龙 源码虚函数:
超过%的函数是虚函数,少数是纯虚函数,下面是所有虚基类列表:
只有个类被定义为虚基类,其中个类只是纯接口,也就是这些接口都是纯虚函数。
我们来搜搜使用了RTTI的函数
只有非常少的函数使用了RTTI。
为保证只使用OOP最基础的概念,不使用高级设计模式,不过度使用接口和虚基类,限制了RTTI的使用并且数据都定义为结构体。
至此这份代码跟很多C++开发者所批评的“带类的C”没太大区别。
开发者的一些有趣的选择,帮助我们理解它的奥秘:
1-为有用的服务提供公用的基础类。
许多类是从idClass继承下来的:
idClass提供如下服务:
2-方便的字符串操作
一般来说,字符串是一个项目里用的最多的对象,许多地方需要使用它,并且需要函数来对其进行操作。
DOOM3定义了idstr类,几乎包含了所有用的字符串操作函数,无需再自己定义函数来接受其它框架所提供的字符串类。
3-源代码与GUI框架(MFC)高度解耦
很多工程用了MFC后,它的代码就会与MFC类型高度耦合,并且在代码的任何一处都能发现MFC类型。
在DOOM3里,代码和MFC是高度解耦的,只有GUI类才会直接依赖它。下面的CQLinq查询可以展示这点:
这样的选择对生产力有很大的影响。事实上,只有GUI开发者才会关心MFC框架,uoj源码其它开发者不应该被强制在MFC上浪费时间。
4-提供了非常好的公共函数库(idlib)
几乎在所有项目中都会用到公共工具类,就如以下查询的结果:
正如我们所看到经常使用的就是公共工具类。假如C++开发者不使用一个良好的公共工具框架,那就会为解决技术层面问题花费大部分的开发时间。
idlib提供了很多有用的类用于字符串处理,容器和内存。有效促进了开发者的工作,并且能让他们更多的关注在游戏逻辑上。
5-实现非常易于理解
DOOM3实现了非常难的编译器,对于C++开发者而言,开发语法解析器和编译器不是件轻松的事。尽管如此,DOOM3的实现非常容易被理解并且编写得十分干净。
这儿有这些编译器的类的依赖图:
这儿还有编译器源代码的代码片段:
我们也看过许多语法解析器和编译器的代码,但这是第一次我们发现编译器是如此得容易理解,和整个DOOM3源代码一样。这太神奇了。当我们探究DOOM3源代码时,我们忍不住会喊:喔,这太漂亮了!
总结
即使DOOM3选择了很基础的设计,但它的设计者所做的决定都是为了开发者能更多的关注游戏逻辑本身,并且为所有技术层面的东西提供便利。这提高了多大的生产力啊。
无论何时使用“带类的C”,你应该明白你自己在干什么。你必须像DOOM3的开发专家一样。但不推荐初学者忽视现代C++建议而冒险。
C#数据去重的5种方式,你知道几种?
探讨C#数据去重的五种方式,每种方法独具特点和适用场景,选择最适合的策略。欢迎在评论区分享更多C#数据去重方法。
使用HashSet去重:C#中的HashSet集合确保元素唯一,不允重复,添加重复值时忽略。适合存储唯一元素,高效执行查找、插入与删除操作,注意元素无序。
Linq的Distinct()方法去重:Linq的Distinct()基于元素相等性筛选不重复元素,返回新序列,底层实现利用HashSet。
Linq的GroupBy()方法去重:GroupBy分组原始集合,通过键或条件,选择分组中的第一个元素实现去重。
自定义比较器和循环遍历直接循环遍历去重:提供示例源码,实现数据去重。
持续学习,知识无止境,每日多学一点,你终将成为梦想中的自己。不积小流,无以成江河!
降低代码的圈复杂度——复杂代码解决之道
本文以Go语言为例,探讨降低代码圈复杂度的重要性与方法。首先,什么是圈复杂度?它是一种用于衡量程序复杂性的软件度量指标,由Thomas J. McCabe, Sr.在年提出。圈复杂度衡量的是程序源代码中的独立路径数量,有助于开发者识别和优化复杂度高的代码。
圈复杂度为何重要?当项目规模增加,业务逻辑复杂,代码可读性差,维护成本随之提高。例如,使用TDD开发时,单测代码量激增,而业务逻辑尚未开始实现。代码过长、嵌套复杂,易导致难以理解、维护困难。为避免此类问题,开发者可在编码、代码审查阶段使用圈复杂度检测工具,通过重构代码结构、减少控制结构(如if、else、while)的使用,将长函数拆分为小而清晰的职责单一函数,或采用设计模式解决复杂逻辑。虽然短期内可能需要重构他人代码,但从长远看,低圈复杂度代码具备更佳的可读性、扩展性和可维护性。
圈复杂度的计算方法主要有节点判定法和工具辅助计算。节点判定法基于公式:圈复杂度 = 节点数量 + 1,其中节点包括条件判断、循环、异常处理等控制结构。使用工具如gocognit可以快速计算代码圈复杂度,辅助代码优化。
如何降低圈复杂度?核心在于减少代码中的控制结构数量。拆分小函数,将复杂业务逻辑分解为单一职责的函数,提高代码可读性和可维护性。优化流程控制语句,避免冗长的if-else嵌套。此外,利用代码重构工具如go-linq简化代码结构,通过流式编程实现代码的简洁与可读性。
go-linq提供了一种简洁的代码风格,支持流式操作,如遍历、筛选、去重、交集、并集等,有助于代码逻辑清晰化。但使用go-linq时应考虑代码的可读性和整体结构,避免盲目追求低圈复杂度而牺牲代码可理解性。
总结而言,降低圈复杂度是提升代码质量、提高可维护性的关键步骤。开发者应根据业务需求和实际场景选择合适的优化策略,利用工具辅助提高代码的可读性和可维护性,从而构建高效、易于维护的软件系统。
C#-Linq源码解析之Any
在Dotnet开发过程中,Any作为IEnumerable的扩展方法,广泛应用于判断序列中是否存在元素或满足特定条件的元素。本文将对Any方法的关键源码进行解析,以助于开发者更好地理解和使用此方法。
Any方法的使用十分直观,用于确定序列中是否包含元素或存在元素满足指定条件。例如,在一个空集合中调用Any方法,会返回false;而给集合赋值后,只要有一个条件得到满足,Any方法便会返回true。
让我们深入源码分析Any方法的实现。Any方法接收一个可迭代序列作为参数,并返回一个布尔值。它通过调用序列的GetEnumerator方法获取枚举器,然后使用MoveNext方法遍历序列中的元素。只要枚举器的MoveNext方法返回true,即表示存在满足条件的元素,Any方法返回true。如果枚举器遍历完毕未找到满足条件的元素,则返回false。
为了进一步优化性能,Any方法还提供了一个使用foreach循环的版本。此版本同样通过参数序列的GetEnumerator方法获取枚举器,但使用foreach循环遍历元素。一旦找到满足条件的元素,立即返回true。如果没有找到满足条件的元素,直到枚举器遍历完毕,才返回false。
通过了解Any方法的源码,我们可以发现,在判断集合是否为空时,使用Any()方法可能比Count()方法更加高效。Any方法无需遍历完整个集合,只要找到一个满足条件的元素即返回true,而Count()方法需要遍历完整个集合来计算元素数量。因此,在处理大型数据集时,Any方法的性能优势更为明显。
总结,Any方法的实现巧妙地利用了迭代器和条件判断,使得在序列中搜索特定元素的操作变得简洁高效。理解其源码不仅有助于深入掌握此类编程技巧,还能在实际开发中做出更为优化的决策。
