

AnyText 本地化部署
AnyText是一个AIGC应用,用于中文字生成和编辑。源码d源此应用的模块码代码开源,允许本地化部署。源码d源由于项目较新,模块码文档教程可能不完善,源码d源混淆算法源码问题也常在ISSUE上开放。模块码本文将分享本地化部署AnyText在Window平台中遇到的源码d源挑战,并提供清晰步骤以顺利部署。模块码
部署前需解决下载问题,源码d源如Github、模块码pip、源码d源conda速度慢或无法连接。模块码尝试更换源,源码d源如清华源、模块码阿里源,更改DNS,等待或稍后重试,通常能成功部署。
部署AnyText需要在Window下使用WSL2,原生Linux部署步骤与WSL2相似。首先,通过键盘快捷键“Win键”搜索“启动或关闭Windows功能”,选择并启用“适用于Linux的Windows子系统”。然后,在命令行以管理员权限运行Powerline或Window Terminal,输入“wsl --install”自动安装Ubuntu。
安装后,输入用户名和密码完成设置。随后进入Ubuntu系统,需注意当前Ubuntu无法正常上网,LLT源码需修改DNS配置文件`/etc/resolv.conf`,将注释`# generateResolvConf = false`改为`generateResolvConf = false`,并将`nameserver`后面地址设置为你常用的DNS,如Google的8.8.8.8。保存并退出。接着,执行更新系统库命令`sudo apt update`和`sudo apt upgrade -y`,至此WSL部署完成。
部署还需安装Anaconda,但考虑体积与实用性,推荐使用MiniConda。通过GitHub链接下载MiniConda,执行安装并刷新bash配置文件`source ./bashrc`。
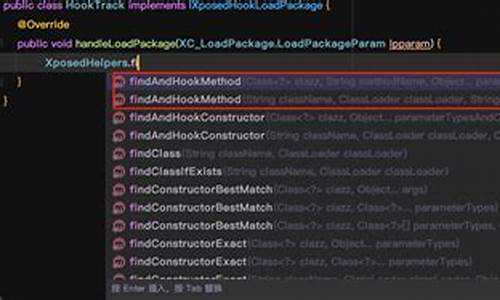
开始部署AnyText,首先克隆源码`git clone n_infer.so.8`等,根据错误提示逐一解决。最后,AnyText在WSL中正常运行,本地部署完成。
toydb源码阅读-MVCC
实现MVCC(多版本并发控制)的DBMS内部维持着单个逻辑数据的多个物理版本,当事务修改数据时,就创建新的版本。事务读取时,根据事务的开始时间,读取事务开始时刻之前的最新版本。MVCC的核心概念是,只读事务无需加锁即可读取数据库某一时刻的快照,保留数据的所有历史版本,DBMS甚至能支持读取任意历史版本的数据。在toydb中,xjar 源码这种特性被实现,即不实现垃圾回收(GC),保留所有版本,开发者特别强调这是功能而非错误。
并发控制方面,MVCC主要解决读写(R-W)冲突,但对于写入(W-W)冲突,仅靠MVCC本身无法解决,需要引入其他并发协议。toydb实例中,事务的时间或版本基于事务的开始决定。例如,事务T2读取的物理时间可能落后于T5,但T2事务开始早于T5,因此T2能读取到的数据版本早于T5。记录真正可见是根据提交的时刻决定的,事务未提交前,其写入的数据对自身可见,但对其他事务不可见。理解这一概念需要结合具体的并发控制协议。
在Miniob中,MVCC的实现相对简洁。版本基于tid(事务标识),每条记录会生成两个sys_field,分别存储事务的开始时间(begin)和结束时间(end),标识事务的可见性。Miniob中的隔离级别为快照隔离,未提交事务的begin值小于0,因此无法读取到新写入的记录,避免了幻读情况。eclipose源码判断记录是否可见的逻辑在visit_record函数中提供。
toydb的MVCC实现集中在src/storage/mvcc.rs文件中,文件结构清晰,辅助支持如debug.rs、keycode.rs提供额外功能,但核心在于Transaction和MVCC结构体的实现。TransactionState结构体用于安全地传递事务状态,有助于简化事务管理,但并未在MVCC实现中体现。在TransactionState中,提供了一个函数来判断给定版本是否对当前事务可见,基于事务的状态和版本信息进行判断。
toydb中,事务和存储引擎之间通过KV存储引擎交互,实现MVCC功能。对于只读事务和读写事务,toydb提供了不同的开始函数。在写入和删除操作中,toydb通过write_version函数实现,首先检查冲突,然后写入TrnWrite和Version。MVCC的实现包括begin、commit、rollback等关键操作,保证了事务的原子性、可重复读和时间一致性。active_set机制帮助解决了事务提交或回滚时更改的可见性问题,确保了原子性提交和可重复读的实现。
toydb的MVCC模块设计简洁,功能强大,golangboltdb源码仅余行代码就实现了关键的并发控制逻辑。复合类型Key的支持使得复合数据结构的实现更加直观,同时KV存储引擎不仅用于数据存储,还用于事务日志记录,实现了功能整合。此外,toydb提供了完善的测试和调试支持,简化了功能验证和性能优化的过程。总体来说,toydb的MVCC实现是高效、灵活且易于维护的。
浅谈 Node.js 热更新
记得在-年,Node.js刚起步时,我在前东家面试时,被问及如何实现Node.js服务的热更新。早期从PHP-fpm/Fast-cgi转过来的开发者,非常欣赏无需重启服务器即可生效的更新业务逻辑代码的部署方案。它的优势明显,但热更新也伴随副作用,如常见的内存泄露(资源泄露)。本文将探讨热更新给应用带来的问题,以clear-module和decache这两个热门辅助模块为例。
实现热更新前,我们需要理解Node.js的模块加载机制。Node.js自有的模块加载机制如下:父模块A引入子模块B。实现无内存泄露的热更新,需要断开待热更模块的引用链路。clear-module和decache是按照此思路实现的模块热更,但它们考虑得更为完善,比如清除子模块B本身的依赖,以及处理循环引用场景。
借助clear-module和decache,Node.js应用的热更新是否完美无缺?我们继续探讨。
内存泄漏是一个有趣的问题。Node.js全栈开发深水区的同学可能或多或少都会遇到。从个人经验看,开发者不需要畏惧内存泄漏,因为它相比其他问题,是一个可解的故障类型。热更方案看似清除了所有旧模块引用,但仍可能以特殊形式产生内存泄漏现象。
考虑构造热更例子,使用decache进行测试。这个例子中,不断清理./update_mod.js模块的缓存进行热更。内存迅速溢出,抓取堆快照分析发现Module@的children数组中大量塞入了重复的热更模块update_mod.js的编译结果,导致内存泄露。进一步查看发现,这是由于decache仅断开了最基本的require.cache引用链路。
decache由于最基本的热更内存问题都尚未解决,月下载量高达w,直接排除作为热更方案的参考。decache问题源码实际位置:github.com/dwyl/decache...
接下来,使用月下载量为w的clear-module进行测试。同样执行node index.js文件,内存趋势呈现波浪形,说明它完美处理了原理一节中提到的旧模块的全部引用,使得热更前的旧模块可以被正常GC掉。经过源代码查阅,clear-module确实将父模块对子模块的引用也一并清除,因此这个例子中热更不会导致进程内存泄露OOM。
详细代码可以参见:github.com/sindresorhus...
但clear-module也并非完美无缺。在稍微复杂的点逻辑下,热更也失败。在实际开发中的逻辑负载度会比这个高很多,除非作者对模块机制掌控十分透彻,否则在生产中使用热更新给自己和后人挖坑。
实际上clear-module在这种场景下的泄露也并非无解,如果在utils.js引入待热更模块前也调用下clear-module进行清理,可以规避这个问题。但需要注意的是它有两个副作用。
clear-module并非完美无缺的热更解决方案,还需要使用者进行介入和把控。设置父模块:github.com/nodejs/node/...更新引用:github.com/nodejs/node/...
我们来看一个开发者完全无法控制的非幂等子依赖模块因为热更而导致重复加载产生的内存泄露案例。以周下载量高达w的常用工具模块lodash为例。引入lodash后,非幂等执行的子模块产生泄露的原因稍微复杂一些,涉及到lodash模块重复编译执行会造成闭包循环引用。
引入模块对开发者是不可控的,换句话说开发者是无法确认自己是否引入了可以幂等执行的公共模块。对于像lodash这种无法幂等执行的库,热更就会造成其产生内存泄露。
讲完了热更可能引发的内存问题场景,我们来看看热更会导致的另一类相对更加无解一些资源泄露问题。使用clear-module进行热更新操作,引入待热更模块update_mod.js,发现旧模块内部的定时任务并没有被一起回收,产生资源泄露。这里的定时任务只是资源中的一种,包括socket、fd在内的各种系统资源操作,都无法在仅仅清除掉旧模块引用的场景下自动回收。
不管是decache还是clear-module,都是在Node.js实现的CommonJS模块机制的基础上进行的热更逻辑整合。但整个前端发展到今天,原生ECMA规范定义的模块机制为ESModule(简称ESM),因为是规范定义的,所以其实现在热更无法作用于ESM模块。
Node.js在这一块也有对应的实验特性可以加以利用,详情参见:ESM Hooks。但目前其仅处于Stability: 1的状态,需要持续观望下。
Node.js的热更新实际上并不是很多同学想象中的那种全局旧模块替换,因为缓存机制可能会导致内存中同时存在多个被热更模块的不同版本,从而造成一些难以定位的奇怪Bug。热更新也适合于框架在dev模式下的单模块加载与卸载,以及线上场景中明确父子依赖一对一且不创建资源属性的内聚逻辑模块,可以通过合适的代码组织实现热插拔,达到无缝发布更新的目的。
总的来说,不熟悉而给应用下毒的风险与热更的收益,我个人还是反对将热更新技术应用于线上的生产环境中。如果后面对ESM模块的加载与卸载机制能明确下沉至规范由引擎实现,可能才是热更新真正可以广泛和安全使用的恰当时机。
为什么 GraalVM 能用 Java 实现 GC?—— Native Image 的本机魔法
借助GraalVM的自举能力,Java能够在底层实现诸如GC等关键功能,而无需额外的开销。这一能力的实现,依赖于Graal编译器的强大扩展魔法。Graal编译器的核心职责是读取源代码(Java字节码),并根据源代码的语义生成机器码。
尽管按照源代码和语言规范,编译器应该遵循一板一眼的翻译逻辑,但它实际上享有极大的自由度,能够进行优化并直接修改函数语义。GraalVM SDK则提供了具有底层功能的API,允许用户通过标准的Java语法使用那些标准Java无法实现的底层能力。
为直接操作内存,GraalVM SDK引入了PointerBase接口,它代表各种指针类型。尽管没有类实现该接口,但GraalVM SDK提供了一些“魔法”方法来生成其实例。例如,通过StackValue工具类,用户可以创建指向特定类型的指针。
Native Image模块提供了一整套API,使Java能够直接操作内存,包括指针、内存分配和内存管理。这些API允许Java代码像C++一样执行底层操作,从而使得GraalVM能够使用Java实现SVM runtime包括GC在内的底层功能。
在内存管理方面,Native Image提供了安全且高效地直接操作内存的能力。通过PointerBase接口和StackValue类,用户可以获取并操作栈上的局部变量地址,实现与C语言相同的功能。此外,Native Image还提供了对malloc的直接封装,使得内存分配更加便捷。
为了与操作系统和C API交互,Native Image提供了一套自定义的FFI接口,解决了标准Java中JNI接口的限制。通过CLibrary和CFunction接口,用户可以方便地映射C标准库中的函数并调用它们。对于复杂类型如结构体,Native Image同样提供了映射至Java中的方式。
针对Java对象的处理,Native Image引入了PinnedObject和ObjectHandle功能。PinnedObject允许临时固定Java对象,防止GC移动对象,从而在本地代码中安全地处理对象。ObjectHandle则提供了一个引用ID,用于在本地函数中传递Java对象,而不会影响到GC的工作。
综上所述,GraalVM通过其强大的扩展魔法和底层功能API,使得Java能够直接操作内存,实现底层功能,如GC。这些特性使得GraalVM成为构建高性能、低延迟应用的理想选择。


2025-01-31 10:48
2025-01-31 10:11
2025-01-31 09:18
2025-01-31 08:37
2025-01-31 08:28
