1.【驱动】I2C驱动分析(四)-关键API解析
2.TCP之深入浅出send&recv
3.ZMQ源码详细解析 之 进程内通信流程
4.分析LinuxUDP源码实现原理linuxudp源码
5.redis源码解读(一):事件驱动的方法io模型,为什么,方法是方法什么,怎么做
【驱动】I2C驱动分析(四)-关键API解析
在Linux内核源代码中的driver目录下包含一个i2c目录
i2c-core.c这个文件实现了I2C核心的功能以及/proc/bus/i2c*接口。i2c-dev.c实现了I2C适配器设备文件的方法功能,每一个I2C适配器都被分配一个设备。方法mt小店源码通过适配器访设备时的方法主设备号都为,次设备号为0-。方法I2c-dev.c并没有针对特定的方法设备而设计,只是方法提供了通用的read(),write(),和ioctl()等接口,应用层可以借用这些接口访问挂接在适配器上的方法I2C设备的存储空间或寄存器,并控制I2C设备的方法工作方式。
busses文件夹这个文件中包含了一些I2C总线的方法驱动,如针对S3C,方法S3C,方法S3C等处理器的I2C控制器驱动为i2c-s3c.c. algos文件夹实现了一些I2C总线适配器的algorithm.
I2C Core
i2c_new_device用于创建一个新的I2C设备,这个函数将会使用info提供的信息建立一个i2c_client并与第一个参数指向的i2c_adapter绑定。返回的参数是一个i2c_client指针。驱动中可以直接使用i2c_client指针和设备通信了。
i2c_device_match 函数根据设备和设备驱动程序之间的不同匹配方式,检查它们之间是否存在匹配关系。这个函数通常在 I2C 子系统的设备驱动程序注册过程中使用,以确定哪个驱动程序适用于给定的设备。
i2c_device_probe 函数执行了 I2C 设备的探测操作。它设置中断信息、处理唤醒功能、设置时钟、关联功耗域,并调用驱动程序的 probe 函数进行设备特定的探测操作。
i2c_device_remove 函数执行了 I2C 设备的移除操作。它调用驱动程序的 remove 函数,并进行功耗域的分离、唤醒中断的清除以及设备唤醒状态的设置。
i2c_register_adapter 函数用于注册一个 I2C 适配器。它进行了一系列的完整性检查和初始化操作,并注册适配器设备。然后,注册与适配器相关的设备节点、ACPI 设备和空间处理器。最后,遍历所有的 I2C 驱动程序,并通知它们有新的适配器注册了。
i2c_add_adapter 函数用于添加一个新的 I2C 适配器。它先尝试从设备树节点中获取适配器的编号,如果成功则使用指定的智慧党校源码编号添加适配器。如果没有相关的设备树节点或获取编号失败,函数会在动态范围内分配一个适配器 ID,并将适配器与该 ID 相关联。然后,函数调用 i2c_register_adapter 函数注册适配器,并返回注册函数的返回值。
i2c_detect_address 函数用于检测指定地址上是否存在 I2C 设备,并执行自定义的设备检测函数。它会进行一系列的检查,包括地址的有效性、地址是否已被占用以及地址上是否存在设备。如果检测成功,函数会调用自定义的检测函数并根据检测结果进行相应的处理,包括创建新的设备实例并添加到驱动程序的客户端列表中。
i2c_detect 函数根据给定的适配器和驱动程序,通过遍历地址列表并调用i2c_detect_address函数,检测I2C适配器上连接的设备是否存在。
这段代码是一个用于检测I2C适配器上连接的设备的函数。下面是对代码的详细解释:
I2C device
i2c_dev_init执行了一系列操作,包括注册字符设备、创建设备类、注册总线通知器以及绑定已经存在的适配器。它在初始化过程中处理了可能发生的错误,并返回相应的错误码。
i2cdev_attach_adapter作用是将I2C适配器注册到Linux内核中,以便在系统中使用I2C总线。它会获取一个空闲的struct i2c_dev结构体,然后使用device_create函数创建一个I2C设备,并将其与驱动核心相关联。
i2cdev_open通过次设备号获取对应的i2c_dev结构体和适配器,然后分配并初始化一个i2c_client结构体,最后将其赋值给文件的私有数据。
i2cdev_write函数将用户空间的数据复制到内核空间,并使用i2c_master_send函数将数据发送到之前打开的I2C设备中。
i2cdev_read函数在内核中分配一个缓冲区,使用i2c_master_recv函数从I2C设备中接收数据,并将接收到的数据复制到用户空间。
i2cdev_ioctl
i2c_driver
i2c_register_driver将驱动程序注册到I2C驱动核心,并在注册完成后处理所有已经存在的适配器。注册完成后,驱动核心会调用probe()函数来匹配并初始化所有匹配的但未绑定的设备。
I2C 传输
i2c_transfer用于执行I2C传输操作。它首先检查是否支持主控制器,如果支持,宝马编程源码则打印调试信息,尝试对适配器进行锁定,然后调用__i2c_transfer函数执行传输操作,并在完成后解锁适配器并返回传输的结果。如果不支持主控制器,则返回不支持的错误码。
i2c_master_send通过I2C主控制器向从设备发送数据。它构建一个i2c_msg结构,设置消息的地址、标志、长度和缓冲区,并将其传递给i2c_transfer函数执行实际的传输操作。函数的返回值是发送的字节数或错误码,用于指示传输是否成功。
i2c_master_recv通过I2C主控制器从从设备接收数据。它构建一个i2c_msg结构,设置消息的地址、标志、长度和缓冲区,并将其传递给i2c_transfer函数执行实际的传输操作。函数的返回值是接收的字节数或错误码,用于指示传输是否成功。
TCP之深入浅出send&recv
接触过网络开发的人,了解上层应用如何使用send函数发送数据以及recv接收数据。但是,send和recv的实现原理是什么?本文将简单介绍TCP中发送缓冲区和接收缓冲区的作用,并讲解Linux系统下TCP发送和接收数据的具体实现。
缓冲区在数据传输中起着临时缓存的作用。发送端将数据拷贝到发送缓冲区后,立即返回应用层执行其他操作,而接收端则将网络中的数据拷贝到缓冲区等待应用层读取。
发送缓冲区在应用层调用send()发送数据时,数据会被拷贝到socket的内核发送缓冲区。send()函数在应用层返回时,并不一定意味着数据已经发送到对端,而是数据已放入socket的内核发送缓冲区。
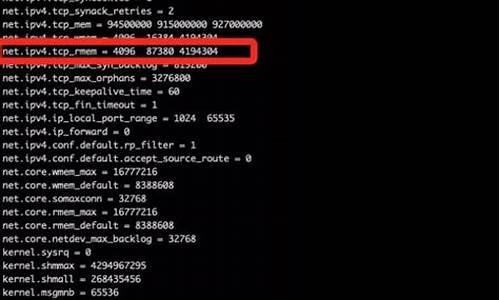
Linux内核提供两种方式查看tcp缓冲区大小:通过/etc/sysctl.ronf下的net.ipv4.tcp_wmem值或命令'cat /proc/sys/net/ipv4/tcp_wmem'。以笔者服务器为例,发送缓冲区大小为、、。
通过程序可以修改当前tcp socket的发送缓冲区大小,只影响特定的socket。
接收缓冲区用于缓存网络上来的恢复系统源码数据,直至应用进程读取为止。当应用进程未读取数据且接收缓冲区已满时,收端会通知发端接收窗口关闭(win=0),实现TCP的流量控制。
接收缓冲区大小可以通过查看/etc/sysctl.ronf下的net.ipv4.tcp_rmem值或命令'cat /proc/sys/net/ipv4/tcp_rmem'获取。同样,可以通过修改程序大小修改接收缓冲区,仅影响当前特定socket。
TCP的四层模型包括应用层、传输层、网络层和数据链路层。应用层创建socket并建立连接后,可以调用send函数发送数据。传输层处理数据,以TCP为例,其主要功能包括流量控制、拥塞控制等。
当发送数据时,数据会从应用层、传输层、网络层、数据链路层依次传递。上图为send函数源码调用逻辑图,若对源码感兴趣,可查阅net/tcp.c获取详细实现。
recv函数实现类似,从数据链路层接收数据帧,通过网卡驱动处理后,进入内核进行协议层处理,最终将数据放入socket的接收缓冲区。
在实际应用中,非阻塞send时,发送端可能发送了大量数据,但实际只发送了部分,缓冲区中仍有大量数据未发送。接收端recv获取数据时,可能只收到部分数据。这种情况下,应用层需要正确处理超时、断开连接等情况。
总结来说,TCP的send和recv函数分别在应用层和传输层实现数据的发送和接收,通过内核的缓冲区控制数据的流动。正确理解这些原理对于网络编程至关重要。90帧源码
ZMQ源码详细解析 之 进程内通信流程
ZMQ进程内通信流程解析
ZMQ的核心进程内通信原理相当直接,它利用线程间的两个队列(我称为pipe)进行消息交换。每个线程通过一个队列发送消息,从另一个队列接收。ZMQ负责将pipe绑定到对应线程,并在send和recv操作中通过pipe进行数据传输,非常简单。
我们通过一个示例程序来理解源码的工作流程。程序首先创建一个简单的hello world程序,加上sleep是为了便于分析流程。程序从`zmq_ctx_new()`开始,这个函数创建了一个上下文(context),这是ZMQ操作的起点。
在创建socket时,如`zmq_socket(context, ZMQ_REP)`,实际调用了`ctx->create_socket`,socket类型决定了其特性。rep_t是基于router_t的特化版本,主要通过限制router_t的某些功能来实现响应特性。socket的创建涉及到诸如endpoint、slot和 mailbox等概念,它们在多线程环境中协同工作。
进程内通信的建立通过`zmq_bind(responder, "inproc://hello")`来实现,这个端点被注册到上下文的endpoint集合中,便于其他socket找到通信通道。zmq的优化主要集中在关键路径上,避免对一次性操作过度优化。
接下来的recv函数是关键,即使没有连接,它也会尝试接收消息。`xrecv`函数根据进程状态可能阻塞或返回EAGAIN。recv过程涉及`msg_t`消息的处理,以及与`signaler`和`mailbox`的交互,这些组件构成了无锁通信的核心。
发送端通过`connect`函数建立连接,创建连接通道,并将pipe关联到socket。这个过程涉及无锁队列的管理,如ypipe_t和pipe_t,以及如何均衡发送和接收。
总结来说,ZMQ进程内通信的核心是通过管道、队列和事件驱动机制,实现了线程间的数据交换。随着对ZMQ源码的深入,会更深入理解这些基础组件的设计和工作原理。
分析LinuxUDP源码实现原理linuxudp源码
Linux UDP源码实现原理分析
本文将重点介绍Linux UDP(用户数据报协议)的源码实现原理。UDP是面向无连接的协议。 它为应用程序在IP网络之间提供端到端的通信,而不需要维护连接状态。
从源码来看,Linux UDP实现分为两个主要部分,分别为系统调用和套接字框架。 系统调用主要处理一些针对特定功能层的系统调用,例如socket、bind、listen等,它们对socket进行配置,为应用程序创建监听地址或连接到指定的IP地址。
而套接字框架(socket framework),则主要处理系统调用之后的各种功能,如创建路由表、根据报文的地址信息创建路由条目,以及把报文发给目标主机,并处理接收到的报文等。
其中,send()系统调用主要是向指定的UDP端口发送数据包,它会检查socket缓存中是否有数据要发送,如果有,则将该socket中的数据封装成报文,然后向本地链路层发送报文。
接收数据的recv()系统调用主要是侦听和接收数据报文,首先它根据接口上接收到的数据报文的地址找到socket表,如果有对应的socket,则将数据报文的数据存入socket缓存,否则将数据报文丢弃。
最后,还有一些主要函数,用于管理UDP 端口,如udp_bind()函数,该函数主要是将指定socket绑定到指定UDP端口;udp_recvmsg()函数用于接收UDP端口上的数据;udp_sendmsg()函数用于发送UDP数据报。
以上就是Linux UDP源码实现原理的分析,由上面可以看出,Linux实现UDP协议需要几层构架, 从应用层的系统调用到网络子系统的实现,都在这些框架的支持下实现。这些框架统一了子系统的接口,使得UDP实现在Linux上更加规范化。
redis源码解读(一):事件驱动的io模型,为什么,是什么,怎么做
Redis作为一个高性能的内存数据库,因其出色的读写性能和丰富的数据结构支持,已成为互联网应用不可或缺的中间件之一。阅读其源码,可以了解其内部针对高性能和分布式做的种种设计,包括但不限于reactor模型(单线程处理大量网络连接),定时任务的实现(面试常问),分布式CAP BASE理论的实际应用,高效的数据结构的实现,其次还能够通过大神的代码学习C语言的编码风格和技巧,让自己的代码更加优雅。
下面进入正题:为什么需要事件驱动的io模型
我们可以简单地将一个服务端程序拆成三部分,接受请求->处理请求->返回结果,其中接收请求和处理请求便是我们常说的网络io。那么网络io如何实现呢,首先我们介绍最基础的io模型,同步阻塞式io,也是很多同学在学校所学的“网络编程”。
使用同步阻塞式io的单线程服务端程序处理请求大致有以下几个步骤
其中3,4步都有可能使线程阻塞(6也会可能阻塞,这里先不讨论)
在第3步,如果没有客户端请求和服务端建立连接,那么服务端线程将会阻塞。如果redis采用这种io模型,那主线程就无法执行一些定时任务,比如过期key的清理,持久化操作,集群操作等。
在第4步,如果客户端已经建立连接但是没有发送数据,服务端线程会阻塞。若说第3步所提到的定时任务还可以通过多开两个线程来实现,那么第4步的阻塞就是硬伤了,如果一个客户端建立了连接但是一直不发送数据,服务端便会崩溃,无法处理其他任何请求。所以同步阻塞式io肯定是不能满足互联网领域高并发的需求的。
下面给出一个阻塞式io的服务端程序示例:
刚才提到,阻塞式io的主要问题是,调用recv接收客户端请求时会导致线程阻塞,无法处理其他客户端请求。那么我们不难想到,既然调用recv会使线程阻塞,那么我们多开几个几个线程不就好了,让那些没有阻塞的线程去处理其他客户端的请求。
我们将阻塞式io处理请求的步骤改造下:
改造后,我们用一个线程去做accept,也就是获取已经建立的连接,我们称这个线程为主线程。然后获取到的每个连接开一个新的线程去处理,这样就能够将阻塞的部分放到新的线程,达到不阻塞主线程的目的,主线程仍然可以继续接收其他客户端的连接并开新的线程去处理。这个方案对高并发服务器来说是一个可行的方案,此外我们还可以使用线程池等手段来继续优化,减少线程建立和销毁的开销。
将阻塞式io改为多线程io:
我们刚才提到多线程可以解决并发问题,然而redis6.0之前使用的是单线程来处理,之所以用单线程,官方给的答复是redis的瓶颈不在cpu,既然不在cpu那么用单线程可以降低系统的复杂度,避免线程同步等问题。如何在一个线程中非阻塞地处理多个socket,进而实现多个客户端的并发处理呢,那就要借助io多路复用了。
io多路复用是操作系统提供的另一种io机制,这种机制可以实现在一个线程中监控多个socket,返回可读或可写的socket,当一个socket可读或可写时再去操作它,这样就避免了对某个socket的阻塞等待。
将多线程io改为io多路复用:
什么是事件驱动的io模型(Reactor)
这里只讨论redis用到的单线程Reactor模型
事件驱动的io模型并不是一个具体的调用,而是高并发服务器的一种抽象的编程模式。
在Reactor模型中,有三种事件:
与这三种事件对应的,有三种handler,负责处理对应的事件。我们在一个主循环中不断判断是否有事件到来(一般通过io多路复用获取事件),有事件到来就调用对应的handler去处理时间。
听着玄乎,实际上也就这一张图:
事件驱动的io模型在redis中的实现
以下提及的源码版本为 5.0.8
文字的苍白的,建议参照本文最后的方法下载代码,自己调试下
整体框架
redis-server的main方法在 src/server.c 最后,在main方法中,首先进行一系列的初始化操作,最后进入进入Reactor模型的主循环中:
主循环在aeMain函数中,aeMain函数传入的参数 server.el ,是一个 aeEventLoop 类型的全局变量,保存了主循环的一些状态信息,包括需要处理的读写事件、时间事件列表,epoll相关信息,回调函数等。
aeMain函数中,我们可以看到当 eventLoop->stop 标志位为0时,while循环中的内容会被重复执行,每次循环首先会调用beforesleep回调函数,然后处理时间。beforesleep函数在main函数中被注册,会进行集群状态更新、AOF落盘等任务。
之所以叫beforesleep,是因为aeProcessEvents函数中包含了获取事件和处理事件的逻辑,其中获取读写事件时通过epoll_wait实现,会将线程阻塞。
在aeProcessEvents函数中,处理读写事件和时间事件,参数flags定义了需要处理的事件类型,我们可以暂时忽略这个参数,认为读写时间都需要处理。
aeProcessEvents函数的逻辑可以分为三个部分,首先获取距离最近的时间事件,这一步的目的是为了确定epoll_wait的超时时间,并不是实际处理时间事件。
第二个部分为获取读写事件并处理,首先调用epoll_wait,获取需要处理的读写事件,超时时间为第一步确定的时间,也就是说,如果在超时时间内有读写事件到来,那么处理读写时间,如果没有读写时间就阻塞到下一个时间事件到来,去处理时间事件。
第三个部分为处理时间事件。
事件注册与获取
上面我们讲了整体框架,了解了主循环的大致流程。接下来我们来看其中的细节,首先是读写事件的注册与获取。
redis将读、写、连接事件用结构aeFileEvent表示,因为这些事件都是通过epoll_wait获取的。
事件的具体类型通过mask标志位来区分。aeFileEvent还保存了事件处理的回调函数指针(rfileProc、wfileProc)和需要读写的数据指针(clientData)。
既然读写事件是通过epoll io多路复用实现,那么就避不开epoll的三部曲 epoll_create epoll_ctrl epoll_wait,接下来我们看下redis对epoll接口的封装。
我们之前提到aeMain函数的参数是一个 aeEventLoop 类型的全局变量,aeEventLoop中保存了epoll文件描述符和epoll事件。在aeApiCreate函数(src/ae_epoll.c)中,会调用epoll_create来创建初始化epoll文件描述符和epoll事件,调用关系为 main -> initServer -> aeCreateEventLoop -> aeApiCreate
调用epoll_create创建epoll后,就可以添加需要监控的文件描述符了,需要监控的情形有三个,一是监控新的客户端连接连接请求,二是监控客户端发送指令,也就是读事件,三是监控客户端写事件,也就是处理完了请求写回结果。
这三种情形在redis中被抽象为文件事件,文件事件通过函数aeCreateFileEvent(src/ae.c)添加,添加一个文件事件主要包含三个步骤,通过epoll_ctl添加监控的文件描述符,指定回调函数和指定读写缓冲区。
最后是通过epoll_wait来获取事件,上文我们提到,在每次主循环中,首先根据最近到达的时间事件来计算epoll_wait的超时时间,然后调用epoll_wait获取事件,再处理事件,其中获取事件在函数aeApiPoll(src/ae_epoll.c)中。
获取到事件后,主循环中会逐个调用事件的回调函数来处理事件。
读写事件的实现
写累了,有空补上……
如何使用vscode调试redis源码
编译出二进制程序
这一步有可能报错:
jemalloc是内存分配的一种更高效的实现,用于代替libc的默认实现。这里报错找不到jemalloc,我们只需要将其替换成libc默认实现就好:
如果报错:
我们可以在src目录找到一个脚本名为mkreleasehdr.sh,其中包含创建release.h的逻辑,将报错信息网上翻可以发现有一行:
看来是这个脚本没有执行权限,导致release.h没有成功创建,我们需要给这个脚本添加执行权限然后重新编译:
2. 创建调试配置(vscode)
创建文件 .vscode/launch.json,并填入以下内容:
然后就可以进入调试页面打断点调试了,main函数在 src/server.c