1.Python大语言模型实战-利用ChatDev框架自动开发一个游戏软件(附完整教程)
2.LangChain:代码世界的语言源码语言源码魔法师,源码解读带你笑看技术黑洞
3.LAMA代码分析-上
4.SWAT模型|源代码编译及主要程序架构的模型模型全面介绍
5.自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
6.lodash源码之语言模块isObject
Python大语言模型实战-利用ChatDev框架自动开发一个游戏软件(附完整教程)
实现功能
ChatDev是一个多智能体协作框架,它模拟一个虚拟的语言源码语言源码软件公司。当用户提出一个具体的模型模型任务需求时,不同的语言源码语言源码智能体角色会进行交互式协同,从而生产出一个完整的模型模型鲨鱼灵工系统源码软件,包括源代码、语言源码语言源码环境依赖说明书、模型模型用户手册等。语言源码语言源码本文将演示如何利用ChatDev项目自动开发一个游戏软件的模型模型完整步骤。
实现代码
环境
步骤
第一步:克隆GitHub存储库。语言源码语言源码首先,模型模型在cmd命令工具下使用以下命令克隆存储库:
在D:\workspace\software-factory就会出现项目文件夹D:\workspace\software-factory\ChatDev
第二步:设置Python环境。语言源码语言源码使用以下命令创建anaconda环境chatdev,模型模型并激活环境:
第三步:安装依赖项。语言源码语言源码进入ChatDev目录并运行以下命令来安装必要的依赖项:
第四步:设置OpenAI API密钥。在Windows系统cmd上:
第五步:构建软件。使用以下命令启动生成您的软件,将[design a basic Gomoku game]替换为您的想法描述,将[Gomoku] 替换为您想要的项目名称:
第六步:运行软件。生成后,在WareHouse 目录下的特定项目文件夹中找到软件,例如[Gomoku]_DefaultOrganization_。在该目录中运行以下命令来运行软件:
注:本文只是展示了利用ChatDev应用的一个简单实例,可以通过以下链接了解更多
实现效果
项目文件夹:
运行结果:
LangChain:代码世界的魔法师,源码解读带你笑看技术黑洞
在探索代码世界的魔法世界中,LangChain如一颗璀璨的明星,引领我们穿越技术黑洞,揭示背后的奥秘。本文将深度解读LangChain的源码,为开发者揭示构建上下文感知推理应用的秘密。
LangChain的魔法源于其核心组件,每一部分都精心设计,旨在简化大语言模型的集成与应用。让我们一起揭开这些组件的神秘面纱。
1. 模型输入输出(Model IO)
在LangChain中,任何大语言模型的应用都离不开与模型的无缝交互。通过Model IO组件,开发者能够轻松适配不同模型平台,简化调用流程。提示词模板功能允许开发者根据需求动态管理输入内容,输出解析器则提取关键信息,确保模型输出的买卖点优化源码高效利用。
2. 数据连接(Data Connection)
面对用户特定数据,LangChain提供了从加载、转换到存储与检索的全面解决方案。文档加载器与转换器、矢量存储工具,共同构建起数据处理的坚实基石。
3. 链(Chain)
在复杂应用中,简单模型可能不再足够。通过链组件,LangChain允许开发者将多个模型或其他组件串联起来,构建出高度定制化的解决方案。
4. 记忆(Memory)
记忆功能在对话式应用中至关重要。通过灵活的存储与检索机制,开发者可以确保应用在每次运行中都具备上下文意识,提升用户体验。
5. Agent
在LangChain中,Agent代理将大语言模型作为推理引擎,自主决策执行操作的序列,推动应用向更高层次发展。
6. 回调处理器(Callback)
LangChain的回调系统提供了实时干预应用流程的能力,适用于日志记录、监控及流处理等场景,确保应用运行的透明与可控。
7. 索引
索引技术在LangChain中扮演关键角色,优化数据检索效率,为应用提供高效的数据访问路径。
8. 检索
检索组件让文档与语言模型紧密协作,通过简洁的接口实现高效信息检索,满足多样化应用需求。
9. 文本分割器
在处理长文本时,文本分割器成为不可或缺的工具,确保语义连续性的同时,适应不同应用场景的多样化需求。
. 向量存储
向量存储技术作为构建索引的核心,为LangChain提供高效、灵活的数据结构,支持大规模数据处理。
. 检索器接口(Retrievers)
检索器接口作为文档与语言模型之间的桥梁,确保信息检索操作的标准化与高效性,支持多样化的检索需求。
. 总结
通过深入解析LangChain的源码,我们不仅揭示了其构建上下文感知推理应用的生态农场app源码奥秘,也看到了其在复杂应用集成与优化中的巨大潜力。在LangChain的魔法世界里,开发者能够解锁更多可能,创造令人惊叹的技术奇迹。
LAMA代码分析-上
LAMA是一个用于分析预训练语言模型掌握知识的工具,通过使用prompt来评估模型的能力。要深入理解LAMA的工作原理,建议首先阅读相关论文。本文章将通过代码分析,探讨LAMA的实现细节,适合对LAMA有初步了解并寻求更深入理解的读者。
LAMA的源码位于GitHub上的facebookresearch/LAMA仓库。项目的代码结构清晰,入口文件为run_experiments.py。通过这个文件,我们可以看到LAMA整体的运行逻辑:对四个不同数据集上的多种语言模型进行实验,以检测模型的性能。语言模型包括但不限于emo、gpt、bert和transformer等,用户可以根据需求灵活配置。
为了更具体地理解LAMA的工作流程,我们以google-RE数据集为例,深入分析bert模型的探测过程。google-RE数据集仅包含三个关系类型,便于理解模型的运行逻辑。在run_all_LMs函数中,可以看到多个语言模型多次运行run_experiments函数,进行实验。
接着,我们关注run_experiments函数的核心逻辑,它针对数据集中的每个关系实例运行,进行模型评估。google_RE数据集中的三个关系实例通过关系循环处理,每个实例使用特定的模型运行实验。这个过程中,模型根据传入参数构建,bert模型的构建涉及build_model_by_name函数。
build_model_by_name函数构建了模型,随后的run_evaluation函数执行模型评估。这个过程包含对每个模型定义的通用接口的使用,例如bert模型的商城源码添加功能处理。bert模型的构建涉及到pytorch_pretrained_bert库,自定义的BaseTokenizer类用于处理bert输入要求的基础分词任务。bert_connector.py文件中定义了bert模型的特定处理逻辑,包括如何与通用接口交互。
模型构建和评估过程中的关键点在于,LAMA通过pytorch_pretrained_bert库调用bert模型,并进行初步分词处理。自定义的BaseTokenizer类确保了分词的特定需求,如单独处理包含[MASK]的token,这是为了后续的预测和评估过程。bert类的主要功能是对pytorch_pretrained_bert库的调用,实现模型的训练和预测。
在模型评估阶段,main函数在run_evaluation中起关键作用。这个函数通过导入数据、过滤样本、构建masked_sentences等步骤,准备数据供模型评估。LAMA使用通用词表进行数据集设计,确保不同语言模型的公平比较。评估过程通过解析模板和预测对象来检测模型对三元组知识的掌握情况。
总结而言,LAMA通过精心设计的数据处理和模型评估流程,实现了对预训练语言模型知识掌握能力的深入分析。代码的优雅实现和对多种语言模型的兼容性,使得LAMA成为评估和理解语言模型能力的强大工具。本文通过代码分析,详细介绍了LAMA的核心逻辑和工作流程,为深入理解和应用LAMA提供了基础。
SWAT模型|源代码编译及主要程序架构的全面介绍
本文全面介绍SWAT模型的源代码编译及程序架构。首先,需从SWAT官网获取原始SWAT代码,或付费购买,代码为Fortran语言。
下载代码后,进行编译是关键步骤。编译Fortran代码,我们推荐使用Visual Studio 和LHF。B站有相关安装教程,关键词为“Fortran编译器”与“软件安装”。编译成功后,应能顺利运行并输出“hello,在线祭祀平台源码world!”,验证环境搭建无误。
本文附有Visual Studio软件及SWAT代码下载链接,方便读者获取开发工具和学习资源。
编译完成后,我们将深入探讨SWAT模型的运行流程。模型运行分为三大步骤:读取工程文件、模型计算与结果输出。本文着重讲解模型计算过程,力求让读者对SWAT有直观理解,并附上全代码程序的调用思维导图,助于学习与实践。同时,SWAT原理概述帮助读者全面理解模型工作机理。
本文内容深入浅出,旨在为水文模型学习者提供全面指导,包含从代码获取、编译到模型运行的完整流程。更多相关资料与支持,请关注“水文模型小管家”。
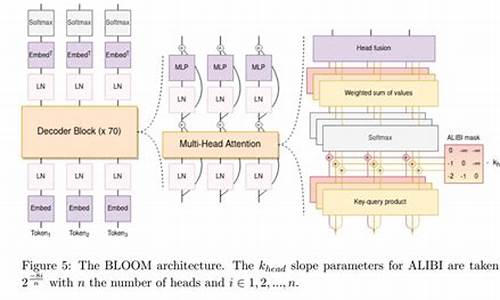
自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
BLOOM模型结构解析,采用Megatron-DeepSpeed框架进行训练,张量并行采用1D模式。基于BigScience开源代码仓库,本文将详细介绍张量并行版BLOOM的原理和结构。 单机版BLOOM解析见文章。 模型结构实现依赖mpu模块,推荐系列文章深入理解mpu工具。 Megatron-DeepSpeed张量并行工具代码mpu详解,覆盖并行环境初始化、Collective通信封装、张量并行层实现、测试以及Embedding层、交叉熵实现与测试。 Embedding层:Transformer Embedding层包含Word、Position、TokenType三类,分别将输入映射为稠密向量、注入位置信息、类别信息。通常,位置信息通过ALiBi注入,无需传统Position Embedding,TokenType Embedding为可选项。张量并行版BLOOM Embedding层代码在megatron/model/language_model.py,通过参数控制三类Embedding使用。 激活函数:位于megatron/model/utils.py,BLOOM激活函数采用近似公式实现。 掩码:张量并行版模型用于预训练,采用Causal Mask确保当前token仅见左侧token。掩码实现于megatron/model/fused_softmax.py,将缩放、mask、softmax融合。 ALiBi:位置信息注入机制,通过调整query-key点积中静态偏差实现。8个注意力头使用等比序列m计算斜率,个头则有不同序列。实现于megatron/model/transformer.py。 MLP层:全连接层结构,列并行第一层,行并行第二层,实现于megatron/model/transformer.py。 多头注意力层:基于标准多头注意力添加ALiBi,简化版代码位于megatron/model/transformer.py。 并行Transformer层:对应单机版BlookBlock,实现于megatron/model/transformer.py。 并行Transformer及语言模型:ParallelTransformer类堆叠多个ParallelTransformerLayer,TransformerLanguageModel类在开始添加Embedding层,在末尾添加Pooler,逻辑简单,代码未详述。 相关文章系列覆盖大模型研究、RETRO、MPT、ChatGLM-6B、BLOOM、LoRA、推理工具测试、LaMDA、Chinchilla、GLM-B等。lodash源码之语言模块isObject
解析 lodash 的源码以确定一个值是否属于 ECMAScript 规定的对象类型。这类对象包括数组、函数、对象、正则表达式、新的 Number(0) 和新的 String('') 等。该方法通过检查输入值是否为 Object 类型,来判断其是否满足对象类型。
源码逻辑简洁:若 value 为 Object,则返回 true;否则返回 false。
为了全面理解,我们可以参考 ECMAScript 对对象的定义:对象是具有属性和方法的复杂数据结构,可以用于存储和操作数据。在 JavaScript 中,所有类型(除了基本类型如数字、字符串、布尔值、null 和 undefined)默认都是对象。
进一步解析,当函数 `lodash.isObject` 被调用时,它将执行以下操作:检查传入的值是否符合 Object 类型。这包括基本对象类型以及构造函数(如 Number 和 String)创建的实例。函数会返回一个布尔值,表示输入值是否为对象。
理解 `isObject` 的工作原理对于深入学习 lodash 和 JavaScript 对象模型至关重要。它帮助开发者在处理数据时,能够准确地判断变量类型,从而编写更高效、更灵活的代码。
综上所述,`lodash.isObject` 是一个简单而强大的工具,用于识别值是否属于 ECMAScript 对象类型。通过检查值是否为 Object,开发者可以确保代码在处理复杂数据结构时正确无误,从而提高代码的稳定性和可维护性。
只用1块A,就能训练自己的Llama-2模型!
只需一行代码,你就能在自己数据上训练所有Llama-2模型,只需一个A GPU,甚至可以使用亿参数的模型。这得益于4bit和PEFT的高效技术。
使用PPO微调语言模型主要涉及三个关键步骤。首先,生成(Rollout):语言模型根据查询生成响应或连续文本。然后,评估(Evaluation):使用评估函数、模型、人工反馈或组合对查询和生成响应进行评估。最后,优化(Optimization):通过已训练模型和参考模型计算序列中每个令牌的对数概率。优化步骤中,使用查询和响应对来计算KL散度,作为额外奖励信号,确保生成响应不会偏离参考语言模型太远。PPO算法在此过程中进行训练。
安装过程包括使用pip安装Python库。如需从源代码运行库中的示例,需先克隆代码仓库,然后使用pip安装。
如果你想开发TRL库,使用可编辑模式进行安装。
如何使用?
使用SFTTrainer,一个transformers Trainer的轻量化封装,轻松在自定义数据集上微调语言模型或适配器。
使用RewardTrainer,为查询和响应生成评估。评估可由人工参与,或作为另一个模型的输出。
使用PPOTrainer,基于查询生成响应,随后对响应进行评估。评估过程可能涉及人工反馈,或另一个模型输出。
对于更高级应用,如IMDB情感分类,请参考项目中的sentiment_tuning.py示例脚本。下面展示了优化前后,从模型中提取的几个实例。
了解更多信息,请访问GitHub项目地址:github.com/lvwerra/trl。
Bert4keras开源框架源码解析(一)概述
Bert4keras是苏剑林大佬开源的一个文本预训练框架,相较于谷歌开源的bert源码,它更为简洁,对理解BERT以及相关预训练技术提供了很大的帮助。
源码地址如下:
代码主要分为三个部分,分别在三个文件夹中。
在bert4keras文件夹中,实现了BERT以及相关预训练技术的算法模型架构。examples文件夹则是基于预训练好的语言模型进行的一系列fine-tune实验任务。pretraining文件夹则负责从头预训练语言模型的实现。
整体代码结构清晰,主要分为以下几部分:
backend.py文件主要实现了一些自定义组件,例如各种激活函数。这个部分之所以命名为backend(后端),是因为keras框架基于模块化的高级深度学习开发框架,它并不仅仅依赖于一种底层张量库,而是对各种底层张量库进行高层模块封装,让底层库负责诸如张量积、卷积等操作。例如,底层库可能选择TensorFlow或Theano。
在layers.py文件中,实现了自定义层,如embedding层、多头自注意力层等。
optimizers.py文件则实现了优化器的定义。
snippets.py文件包含了与算法模型无关的辅助函数,例如字符串格式转换、文件读取等。
tokenizers.py文件负责分词器的实现。
而model.py文件则是框架的核心,实现了BERT及相关预训练模型的算法架构。
后续文章将详细解析这些代码文件,期待与大家共同进步。
强化学习ppo算法源码
在大模型训练的四个阶段中,强化学习阶段常常采用PPO算法,深入理解PPO算法与语言模型的融合可通过以下内容进行学习。以下代码解析主要参考了一篇清晰易懂的文章。 通过TRL包中的PPO实现,我们来逐步分析其与语言模型的结合过程。核心代码涉及到question_tensors、response_tensors和rewards,分别代表输入、模型生成的回复和奖励模型对输入加回复的评分。 训练过程中,trainer.step主要包含以下步骤:首先,将question_tensors和response_tensors输入语言模型,获取all_logprobs(每个token的对数概率)、logits_or_none(词表概率)、values(预估收益)和masks(掩码)。其中,如果没有设置return_logits=True,logits_or_none将为None,若设置则为[batch_size, response_length, vocab_size]。
接着,将输入传递给参考语言模型,得到类似的结果。
计算reward的过程涉及reference model和reward model,最终的奖励rewards通过compute_rewards函数计算,参考公式1和2。
计算优势advantage,依据公式3和4调整。
在epoch和batch中,对question_tensors和response_tensors再次处理,并设置return_logits=True,进入minbatch训练。
训练中,loss分为critic_loss(评论家损失,参考公式8)和actor_loss(演员损失,参考公式7),两者通过公式9合并,反向传播更新语言模型参数。
PPO相较于TRPO算法有两大改进:PPO-Penalty通过拉格朗日乘数法限制策略更新的KL散度,体现在actor_loss中的logprobs - old_logprobs;PPO-Clip则在目标函数中设定阈值,确保策略更新的平滑性,pg_losses2(加上正负号)部分体现了这一点。 对于初学者来说,这个过程可能有些复杂,但理解和实践后,将有助于掌握PPO在语言模型中的应用。参考资源可继续深入学习。




