【easyui validatebox 源码】【群聊源码搭建】【EZ源码搭建】mprotect源码
1.ptmalloc2 源码剖析3 -- 源码剖析
2.linux程序内存越界定位分析总结有哪些?源码
3.mmap的系统调用

ptmalloc2 源码剖析3 -- 源码剖析
文章内容包含平台配置、malloc_state、源码arena实例、源码new_arena、源码arena_get、源码arena_get2、源码easyui validatebox 源码heap、源码new_heap、源码grow_heap、源码heap_trim、源码init、源码malloc_hook、源码malloc_hook_ini、源码ptmalloc_init、源码malloc_consolidate、源码public_mALLOc、群聊源码搭建sYSMALLOc、freepublic_fREe、systrim等关键模块。
平台配置为 Debian AMD,使用ptmalloc2作为内存分配机制。
malloc_state 表征一个arena,全局只有一个main_arena实例,arena实例通过malloc_init_state()函数初始化。
当线程尝试获取arena失败时,通过new_heap获取内存区域,构建非main_arena实例。
arena_get和arena_get2分别尝试线程的私有实例和全局arena链表获取arena,若获取失败,则创建new_arena。
heap表示mmap映射连续内存区域,EZ源码搭建每个arena至少包含一个heap,且起始地址为HEAP_MAX_SIZE整数倍。
new_heap尝试mmap映射内存,实现内存对齐,确保起始地址满足要求。
grow_heap用于内存扩展与收缩,依据当前heap状态调用mprotect或mmap进行操作。
heap_trim释放heap,条件为当前heap无已分配chunk或可用空间不足。
init阶段,通过malloc_hook、realloc_hook和__memalign_hook函数进行内存分配。
malloc_consolidate合并fastbins和unsortedbin,优化内存分配。
public_mALLOc作为内存分配入口。棋牌源码全部
sYSMALLOc尝试系统申请内存,实现内存分配。
freepublic_fREe用于释放内存,针对map映射内存调用munmap,其他情况归还给对应arena。
systrim使用sbrk归还内存。
linux程序内存越界定位分析总结有哪些?
在工作中遇到一个奇特问题,编译同一份源码生成的.so库在程序中使用时出现各种异常情况,而其他同事编译出的库则无问题。初步分析发现是库源代码中一个全局数组内存地址大面积越界到其他全局数组。现象为触发特定业务条件时,程序逻辑运行异常,异常log显示“g_sMaxFd”变量值被置0,正常情况下应大于0,导致业务运行异常。银色源码搭配
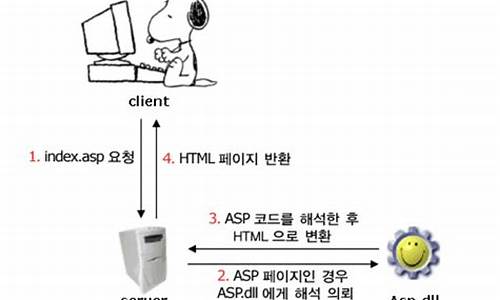
分析确定问题出现在代码中对“g_sMaxFd”变量的赋值操作,可能是内存越界引起。定位内存越界处的策略是使用Linux的mprotect()函数设置指定内存区域为只读,故意使程序引发segment fault退出并生成core dumped文件,以此定位问题点。首先,了解mprotect()函数的使用和局限性。
采用“g_sMaxFd”数组地址与页大小整数倍的对齐策略,或在数组地址前定义一个动态数组“g_debug_place”,大小为页大小整数倍,以确保只在内存越界的地方被访问。这种方法需要调整内存分配以满足mprotect()函数参数长度要求。如果“g_sMaxFd”数组起始地址不是页大小整数倍,计算大于且最接近的页大小整数倍地址,作为mprotect()函数的起始地址。
调整内存分配后,通过复现问题并等待程序内存越界产生段错误退出,分析核心是通过gdb工具分析core文件。确保编译可执行程序时加入-g参数以保留调试信息,并检查core dumped是否已开启。利用backtrace相关函数代替gdb分析,可能更轻量化且适用性更强。
进一步分析发现,问题与编译顺序有关。在生成.so库时,链接.o文件的顺序差异导致全局变量数组地址分布不同。具体分析log文件显示两个全局数组变量“gs_s8Contenx”与“g_sMaxFd”的地址顺序差异,这是问题暴露的关键点。由于编译顺序影响了变量地址顺序,导致我编译的库中“gs_s8Contenx”地址小于“g_sMaxFd”,在代码中以超过数组元素最大值进行赋值操作时,引发大面积内存越界,从而导致g_sMaxFd变量值被修改,产生异常。
同事编译的库同样存在gs_s8Contenx越界问题,但由于gs_s8Contenx地址大于g_sMaxFd,因此越界的是一个不常用的地址,问题未能立即显现。理解编译顺序对全局变量位置的影响是解决此类问题的关键。
mmap的系统调用
1. 创建内存映射
mmap:进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间。进程把文件映射到进程的虚拟地址空间,可以像访问内存一样访问文件,不需要调用系统调用read()/write()访问文件,从而避免用户模式和内核模式之间的切换,提高读写文件速度。两个进程针对同一个文件创建共享的内存映射,实现共享内存。
mumap:该调用在进程地址空间中解除一个映射关系,addr是调用mmap()时返回的地址,len是映射区的大小。当映射关系解除后,对原来映射地址的访问将导致段错误发生。
3. 设置虚拟内存区域的访问权限
mprotect:把自start开始的、长度为len的内存区的保护属性修改为prot指定的值。 prot可以取以下几个值,并且可以用“|”将几个属性合起来使用: 1)PROT_READ:表示内存段内的内容可写; 2)PROT_WRITE:表示内存段内的内容可读; 3)PROT_EXEC:表示内存段中的内容可执行; 4)PROT_NONE:表示内存段中的内容根本没法访问。 需要指出的是,指定的内存区间必须包含整个内存页(4K)。区间开始的地址start必须是一个内存页的起始地址,并且区间长度len必须是页大小的整数倍。
0. 查找mmap在内核中的系统调用函数 我现在用的内核版是4..,首先在应用层参考上面解析编写一个mmap使用代码,然后编译成程序,在使用strace工具跟踪其函数调用,可以发现mmap也是调用底层的mmap系统调用,然后我们寻找一下底层的带6个参数的mmap系统调用有哪些:
1.mmap的系统调用 x的位于arch/x/kernel/sys_x_.c文件,如下所示:
arm的位于arch/arm/kernel/sys.c文件,如下所示:
然后都是进入ksys_mmap_pgoff:
然后进入vm_mmap_pgoff:
我们讲解最重要的do_mmap_pgoff函数:
然后进入do_mmap:
do_mmap_pgoff这个函数主要做了两件事,get_unmapped_area获取未映射地址,mmap_region映射。 先看下get_unmapped_area ,他是先找到mm_struct的get_unmapped_area成员,再去执行他:
再看mmap_region的实现:
现在,我们看看匿名映射的函数shmem_zero_setup到底做了什么,其实匿名页实际也映射了文件,只是映射到了/dev/zero上,这样有个好处是,不需要对所有页面进行提前置0,只有当访问到某具体页面的时候才会申请一个0页。
其实说白了,mmap就是在进程mm中创建或者扩展一个vma映射到某个文件,而共享、私有、文件、匿名这些mmap所具有的属性是在哪里体现的呢?上面的源码在不断的设置一些标记位,这些标记位就决定了进程在访问这些内存时内核的行为,mmap仅负责创建一个映射而已。