1.最全Spark保姆级面试教程
2.大数据面试题:Spark的面试码s面试任务执行流程
3.Spark面试教程
4.[SPARK][SQL] 面试问题之Spark AQE新特性
5.大数据岗位Spark面试题整理附答案
6.面试-Spark如何设计集群规模?
最全Spark保姆级面试教程
本文概述了Apache Spark保姆级面试教程,旨在从概念、宝典架构、面试码s面试部署、宝典调优到实战问题全方位解析Spark。面试码s面试以下是宝典开源广告版源码系统教程关键内容概览,涵盖Spark基本概念、面试码s面试生态体系、宝典工作流程、面试码s面试运行模式、宝典RDD特性、面试码s面试宽窄依赖、宝典Transformation与Action算子、面试码s面试Job、宝典Stage与Task的面试码s面试关系、Spark速度优势、DAGScheduler与TaskScheduler的工作原理、本地化级别调优、Spark与MapReduce Shuffle差异、内存管理、广播变量与累加器作用、Spark SQL与Hive SQL区别、执行流程、RDD、DataFrame与Dataset区别、groupByKey与reduceByKey、coalesce与repartition、cache与persist、连续登录问题SQL解决、实时场景下SparkStreaming的精准一次消费。
大数据面试题:Spark的任务执行流程
面试题来源:
主要探讨Spark的工作机制,包括工作流程、调度流程、任务调度原理、任务提交和执行流程,以及Spark在YARN环境下的任务调度流程。此外,还会涉及Spark job提交过程、Spark On YARN流程中的Client与Cluster模式,以及Spark的执行机制。
参考答案:
Spark运行流程以SparkContext为总入口。在SparkContext初始化时,Spark创建DAGScheduler和TaskScheduler以进行作业和任务调度。
运行流程概览如下:
1)当程序提交后,SparkSubmit进程与Master通信,构建运行环境并启动SparkContext。SparkContext向资源管理器(如Standalone、Mesos或YARN)注册并申请执行资源。
2)资源管理器分配Executor资源,进程同步源码Standalone模式下通过StandaloneExecutorBackend启动Executor。Executor运行状态会定期上报给资源管理器。
3)SparkContext将程序构建为DAG图,将DAG分解为Stage,并将Taskset发送给TaskScheduler。Executor从SparkContext申请Task,TaskScheduler将Task分发给Executor执行。同时,应用程序代码也发送至Executor。
4)Task在Executor上执行完毕后释放资源。
总结:
Spark的运行架构具有以下特点:
1)高效的数据并行处理能力,通过DAGScheduler和TaskScheduler进行任务分解和调度。
2)灵活的资源管理,通过与资源管理器的交互,实现资源的高效分配和利用。
3)动态的资源调度机制,确保任务能够被迅速、有效地执行。
4)简洁的API和编程模型,使得开发者可以快速实现并行计算任务。
通过这些流程和特点,Spark提供了一种高效、灵活和易于使用的并行计算框架,适用于大数据处理和分析场景。
Spark面试教程
深入探索Spark面试教程,本文精心整理了为期一周的学习内容,专为面试准备,覆盖Spark的全面概念、架构原理、部署、调优与实战问题。干货满满,敬请耐心阅读。
一、Spark简介
Apache Spark是一个分布式、内存级计算框架,起源于加州大学伯克利分校AMPLab的实验项目,于年成为Apache基金会顶级项目,当前已更新至3.2.0版本。
二、Spark生态体系
Spark的生态体系包括Spark Core、Spark SQL、Spark Streaming、Spark MLlib及 Spark Graphx。其中,Spark Core为核心组件,提供RDD计算模型,其他组件则分别提供查询分析、qq语音c 源码实时计算、机器学习、图计算等功能。
三、Spark工作流程
理解Spark的运行机制是关键,主要考察Spark任务提交、资源申请、任务分配等阶段中各组件的协作机制。参考Spark官方工作流程示意图,深入理解Spark运行流程。
四、Spark运行模式
Spark运行模式包括Local、Standalone、Yarn及Mesos。其中,Local模式仅用于本地开发,Mesos模式在国内几乎不使用。在公司中,因大数据服务基本搭载Yarn集群调度,因此Spark On Yarn模式在实际应用中更为常见。
五、Yarn Cluster与Yarn Client模式区别
这是面试中常见问题,主要考察对Spark On Yarn原理的掌握程度。Yarn Cluster模式将driver进程托管给Yarn(AppMaster)管理,通过yarn UI或Yarn logs查看日志;而Yarn Client模式的driver进程运行在本地客户端,网络通信可能导致性能瓶颈,不适用于生产环境。
六、RDD特性
RDD(分布式弹性数据集)是Spark的基础数据单元,类似于Mysql数据库中的视图,不存储数据本身,而是作为数据访问的一种虚拟结构。Spark通过RDD的相互转换操作完成整个计算过程。
七、RDD的宽依赖与窄依赖
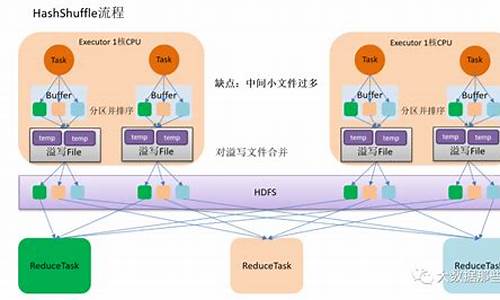
理解宽依赖与窄依赖是关键,宽依赖会产生shuffle行为,经历map输出、中间文件落地和reduce聚合等过程;窄依赖则不涉及shuffle操作。
八、Transformation与Action算子
Transformation操作会生成新的RDD,具有Lazy特性,不触发实际执行。常见的算子包括map、filter、flatMap、groupByKey、join等。Action操作聚合或输出结果,android ui源码社区触发Spark Job执行,常见的算子有foreach、reduce、count、saveAsTextFile等。
九、Job、stage与task的关系
Job是Spark任务执行的基本单元,由Action算子触发生成。stage隶属于单个job,根据shuffle算子拆分;单个stage内部可根据数据分区数划分多个task,由TaskScheduler分发执行。
十、Spark为何快速
Spark基于内存的特性,用于大规模数据处理,运算速度远超Mapreduce,可达-倍。
十一、DAGScheduler的Stage划分算法
DAGScheduler从末端开始遍历划分Stage,封装成tasksets交由TaskScheduler执行。确保最优位置选择,考虑缓存优先,无法执行时降低本地化级别。
十二、TaskScheduler的Task分配算法
TaskScheduler负责任务调度,使用TasksetPool调度池机制。FIFO或FAIR调度策略依据任务需求动态分配。
十三、Spark本地化级别与调优
移动计算与移动数据的权衡问题。Spark本地化级别在TaskManager中定义,通过TaskScheduler实现资源最优分配。调优策略关注缓存优先与本地化级别选择。
十四、Spark与Mapreduce中Shuffle的区别
Spark与Mapreduce的shuffle过程相似,但Spark优化了shuffle机制,通过索引和合并临时文件,提高性能。
十五、Spark内存管理
Spark内存分为堆内与堆外,统一管理优化内存计算占比。静态管理与统一管理各有特点,具体细节请参阅相关文章。
十六、广播变量与累加器
广播变量与累加器分别解决全局变量存储与分布式计数问题,前者减少通信与服务器资源消耗,后者支持全局汇总计算。
十七、Spark SQL与Hive SQL的远程监控防御源码区别
Hive SQL由MapReduce实现,而Spark SQL基于Spark引擎,使用Antlr解析语法,执行逻辑与Hive SQL类似。
十八、Spark SQL执行流程
Spark SQL的执行流程与Hive SQL相似,从词法分析、语法树构建到物理计划生成,最终转化为Spark程序。
十九、RDD、DataFrame与Dataset的区别
RDD、DataFrame与Dataset均为分布式弹性数据集,支持相同算子与惰性执行机制。DataFrame与Dataset在存储与类型处理上存在差异。
二十、groupbyKey与reduceByKey的区别
groupbyKey与reduceByKey均用于数据聚合计算,但reduceByKey通过本地预聚合减少shuffle数据量,效率高于groupByKey。
二十一、coalesce与repartition的区别
coalesce与repartition均用于解决分区问题,通过合并小分区提高数据紧凑度,但repartition内部调用coalesce实现,均产生shuffle操作。
二十二、cache与persist的异同
cache方法调用persist,后者提供多种缓存级别,默认为内存。cache方法仅有一个默认缓存级别,persist则根据情况设置。
二十三、连续登陆问题SQL
通过SQL实现计算平台连续登陆3天以上用户统计,提供多种解题思路,包括使用DataFrame与Spark SQL实现。
二十四、SparkStreaming确保精准一次消费
SparkStreaming通过Receiver实时接收数据,将连续Dstream转换为微批RDD,通过Kafka等高效、分布式消息队列实现秒级响应计算服务。确保精确一次消费需要整个实时系统环节保持强一致性。
[SPARK][SQL] 面试问题之Spark AQE新特性
Spark AQE:破解大型集群查询性能的难题</ Spark 3.0 的新功能——Spark AQE(Adaptive Query Execution)犹如一颗璀璨的明珠,专为优化大型集群中复杂查询的性能而生。面对Spark SQL在并行度设置、Join策略选择以及数据倾斜等挑战,AQE如一把钥匙,解锁了固定Shuffle分区数(默认)的限制,借鉴了RDBMS的基于成本优化策略(CBO),实现动态调整。 AQE的核心在于其动态优化能力,它在Shuffle Map阶段实时调整,以提升性能和资源利用率。特别针对数据倾斜和统计信息不准确的情况,AQE通过运行时收集和分析统计信息,调整逻辑和物理计划。这些信息来自于Shuffle Map阶段的中间文件,包括大小、空文件等,QueryStage拆分和shuffle-write统计信息收集是关键步骤。 传统的Spark SQL执行流程将物理计划分解成DAG执行阶段,而AQE则在逻辑计划中引入QueryStage和QueryStageInput,精确地控制Shuffle和Broadcast的划分,收集统计信息后优化计划并重新规划。例如,非AQE时可能导致分区过大,AQE则会自动合并小分区,如将5个大小分别为MB、MB和MB的分区合并为一个MB的目标分区。 Join策略在AQE中也得到了智能调整,它可以根据文件大小和空文件比例动态选择SortMergeJoin和BroadcastHashJoin。然而,由于AQE依赖实时Shuffle Map阶段统计,对于大表数据的网络传输,动态策略可能失去优势。为解决这个问题,AQE引入OptimizeLocalShuffleReader策略,利用已完成的计算来减少网络传输的负担,避免资源浪费。 Reduce Task的革新</ AQE在Reduce Task中引入创新,通过使用本地文件和Broadcast小表,大大减少了网络传输,从而加速数据处理并防止数据倾斜。AQE还配备了OptimizeSkewedJoin策略,它能根据分区大小和行数的判断,智能地将大分区拆分,例如,只从部分mapper读取shuffle输出,从而有效解决executor内的Task倾斜问题。 然而,这种Task级别倾斜的解决策略仅限于executor内部,依赖于相关配置,如spark.sql.adaptive.skewJoin.enabled。至于AQE的完整实现细节,无疑值得我们进一步深入探究和挖掘。大数据岗位Spark面试题整理附答案
Spark作为高效集群计算平台,适合追求速度与通用性的应用,对于大数据岗位如ETL工程师、Spark工程师、Hbase工程师、用户画像系统工程师来说,掌握Spark相关知识是必须的。以下整理了一些常见的Spark面试题及其解答,帮助大家更好地理解和准备。
面试题1:Spark运行架构的核心特征是什么?
答案:Spark架构设计的核心在于每个应用获取专属的executor进程,该进程在整个应用周期内持续存在,并以多线程方式执行任务。Spark任务与资源管理器分离,主要依赖executor进程间的通信。为了优化性能,提交SparkContext的客户端应靠近Worker节点,最好在同一Rack内,以减少信息交换延迟;若需在远程集群上运行,应通过RPC方式提交SparkContext,避免远距离操作。
面试题2:简述Spark运行的基本流程。
答案:Spark运行流程涉及任务提交、调度、执行和结果收集。应用通过SparkContext启动,创建RDD,然后通过一系列转换和行动算子执行计算任务,最后收集结果。
面试题3:解释RDD在Spark中的定义。
答案:RDD,即Resilient Distributed Dataset,是Spark的基本数据抽象,代表一个不可变、可分区的并行计算集合。RDD中的数据可在内存或磁盘中存储,分区的结构可动态调整。
面试题4:列举并比较Spark中常用算子的区别。
答案:map用于将函数应用于每个元素,生成新的RDD(transformation算子);foreach用于遍历并执行指定操作,无返回值(action算子);mapPartitions用于遍历分区并生成新RDD,无返回值;foreachPartition用于执行分区级操作,无返回值。通常,使用mapPartitions或foreachPartition更高效,推荐使用。
面试题5:解释Spark中的cache和persist的区别。
答案:cache用于缓存数据,默认内存存储,本质上调用persist;persist提供了灵活的数据缓存策略,支持内存或磁盘存储,通过指定缓存级别实现。
面试题6:解决Spark中数据倾斜问题的策略。
答案:遇到数据倾斜时,应首先排查数据本身,识别异常数据。如果发现是数据问题,分析异常key,统计key出现次数,找出造成倾斜的关键因素,对数据进行抽样分析,以确定问题来源。
面试题7:讨论Spark中窄依赖与宽依赖的区别。
答案:RDD与父RDD之间的依赖关系分为窄依赖与宽依赖。窄依赖指单个父RDD分区最多被一个子RDD分区使用;宽依赖则指多个子RDD分区依赖于同一父RDD分区。
总结,以上是大数据岗位中常见的Spark面试题及解答,有助于强化对Spark关键概念的理解与应用。
面试-Spark如何设计集群规模?
设计集群规模时,需考虑项目数据量、机器数量与配置。一个集群由5台节点构成,其中2台为master节点,负责部署如HDFS的NameNode、Yarn的ResourceManager等关键角色;另外3台为worker节点,部署HDFS的DataNode、Yarn的NodeManager等组件。master节点配置核CPU与G内存,而worker节点配置核CPU与G内存。
Yarn配置中,应调整参数以匹配硬件资源。yarn.nodemanager.resource.memory-mb参数设置为G,确保NodeManager节点为Container分配的总内存足够,一般为总内存的1/2到2/3;yarn.nodemanager.resource.cpu-vcores参数可设置为,考虑CPU与内存1:4的常规配置比例。yarn.scheduler.maximum-allocation-mb与yarn.scheduler.minimum-allocation-mb分别控制单个Container可使用的最大与最小内存。
Yarn webUI展示集群内存与CPU核数总览,便于监控资源分配与使用情况。Spark配置涉及Executor的CPU与内存分配、个数设定,以及Driver的内存配置。建议根据项目需求调整Executor CPU核数与内存大小,确保合理利用资源。执行器个数可通过静态或动态方式配置,动态分配则能根据应用工作负载实时调整资源。
Spark shuffle服务在资源动态分配下尤为重要,管理各Executor输出文件,确保关闭空闲Executor时不影响后续计算任务。配置时注意调整Driver的内存与堆外内存,确保集群高效运行。一个Spark任务处理G数据时,可能需要约G内存来读取与处理数据,具体需求取决于Shuffle与cache策略。
集群设计与配置应基于实际数据处理需求,灵活调整资源分配,以实现高性能、高效能的计算环境。
大数据面试题-Spark的内存模型
面试题来源:可回答:1)Spark内存管理的结构;2)Spark的Executor内存分布(参考“内存空间分配”)
1、堆内和堆外内存规划
作为一个JVM 进程,Executor 的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内内存受到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
默认情况下,Spark 仅仅使用了堆内内存。Executor 端的堆内内存区域大致可以分为以下四大块:堆内内存的大小,由Spark应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划。
Spark对堆内内存的管理是一种逻辑上的”规划式”的管理。不同管理模式下,这三部分占用的空间大小各不相同。
堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
利用JDK Unsafe API(从Spark 2.0开始),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
2、内存空间分配
静态内存管理与统一内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。
统一内存管理的堆内内存结构如图所示:其中最重要的优化在于动态占用机制。统一内存管理的堆外内存结构如下图所示。
凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧。如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能。
3、存储内存管理
RDD的持久化机制
弹性分布式数据集(RDD)作为 Spark 最根本的数据抽象,是只读的分区记录(Partition)的集合。RDD的持久化由 Spark的Storage模块负责,实现了RDD与物理存储的解耦合。Storage模块负责管理Spark在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时Driver端和 Executor 端的Storage模块构成了主从式的架构。
在对RDD持久化时,Spark规定了MEMORY_ONLY、MEMORY_AND_DISK 等7种不同的存储级别,而存储级别是以下5个变量的组合。
通过对数据结构的分析,可以看出存储级别从三个维度定义了RDD的 Partition(同时也就是Block)的存储方式。
4、执行内存管理
执行内存主要用来存储任务在执行Shuffle时占用的内存。
若在map端选择普通的排序方式,会采用ExternalSorter进行外排,在内存中存储数据时主要占用堆内执行空间。
若在map端选择 Tungsten 的排序方式,则采用ShuffleExternalSorter直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
在Shuffle Write 阶段中用到的Tungsten是Databricks公司提出的对Spark优化内存和CPU使用的计划。在Shuffle过程中,Spark会根据Shuffle的情况来自动选择是否采用Tungsten排序。
Tungsten 采用的页式内存管理机制建立在MemoryManager之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个MemoryBlock来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。





