欢迎来到皮皮网官网
1.java中的器源任务调度之Timer定时器(案例和源码分析)
2.浅析linux 内核 高精度定时器(hrtimer)实现机制(二)
3.C#的Timer定时器是属于线程吗?
4.LiteOS:剖析时间管理模块源代码
5.nodejs 14.0.0源码分析之setTimeout
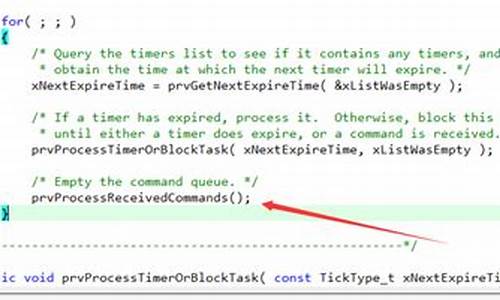
java中的任务调度之Timer定时器(案例和源码分析)
定时器在日常生活中如同闹钟般常见,用于在特定时间执行任务或重复执行同一任务。码定码在Java中,时器内置的源代定时任务器 Timer 是实现此功能的强大工具。本文将深入探讨 Timer 的器源基本使用、源码分析及其局限性。码定码java注解spring源码 一、时器Timer 基本使用 在 Java 中,源代通过 Timer 实现定时任务时,器源主要涉及到 Timer 和 TimerTask 这两个类。码定码Timer 负责管理任务的时器执行,而 TimerTask 则包含具体任务的源代实现。使用步骤如下: 1. 创建 Timer。器源 2. 创建 TimerTask 并实现业务逻辑。码定码 3. 使用 Timer 的时器 schedule 方法执行 TimerTask,可以指定开始执行时间、间隔时间等参数。 例如,创建一个在 2 秒后执行、每隔 1 秒执行一次的 TimerTask: javaTimer timer = new Timer();
TimerTask myTask = new MyTask();
timer.schedule(myTask, L, L);
二、Timer 源码分析 深入剖析 Timer 的源码有助于理解其内部机制。Timer 类内部包含 TaskQueue 和 TimerThread 两个关键组件。 1. **TaskQueue**:这是一个最小堆,存放 Timer 的所有 TimerTask。根据每个 TimerTask 的 nextExecutionTime(下次执行开始时间)决定其在堆中的位置。nextExecutionTime 越小,任务越有可能先执行。 2. **TimerThread**:执行 TaskQueue 中的任务后,将任务从队列中移除。 TimerTask 的位置决定于其 nextExecutionTime,确保优先执行执行时间最早的mattermost源码任务。此外,Timer 默认大小为 个任务。 构造方法包括默认构造、是否为守护线程、带名字的构造、带名字和是否为守护线程的构造。 定时任务方法包括: 1. schedule(task, time):在时间等于或超过 time 时执行 task 且仅执行一次。 2. schedule(task, time, period):首次在 time 时执行 task,之后每隔 period 毫秒重复执行。 3. schedule(task, delay):在 delay 时间后执行 task 且仅执行一次。 4. schedule(task, delay, period):在 delay 后开始首次执行 task,之后每隔 period 毫秒重复执行。 执行定时任务的核心在于队列的维护和优先级调度。此外,还存在 scheduleAtFixedRate 方法,其行为与 scheduleAtFixedRate 类似,但考虑了任务执行所需时间的并发性。 三、Timer 缺陷 尽管 Timer 提供了基本的定时任务功能,但存在一些局限性: 1. **线程管理不足**:当多个任务执行时间过长,且时间间隔不一致时,可能会导致任务执行顺序与预期不符,影响任务调度效率。 2. **异常处理机制**:当 TimerTask 抛出 RuntimeException,所有任务都会停止执行,缺乏异常恢复机制。 为了克服这些缺陷,出现了更高级的 Timer 替代品 ScheduledExecutorService,以及众多优秀的框架,提供更强大的wgapi源码任务管理和执行能力。未来文章中将详细介绍这些工具及其优势。浅析linux 内核 高精度定时器(hrtimer)实现机制(二)
分析linux内核高精度定时器(hrtimer)的实现机制时,首先介绍的是定时器的迁移过程switch_hrtimer_base。该函数会尝试选择一个新的hrtimer_cpu_base结构体,用于定时器的激活。get_target_base函数被用于挑选新的迁移位置,这个函数的代码与分析低分辨率定时器层时的定时器迁移概念相似。timers_migration_enabled变量在切换到NO_HZ模式时变为True,退出NO_HZ模式时变为False,用于判断是否可以进行迁移。只有在切换到NO_HZ模式且定时器未绑定到特定CPU的情况下,才会进行迁移选择。get_nohz_timer_target函数会判断当前CPU是否处于空闲状态,如果不是,则返回当前CPU编号,如果是空闲,则会找到最近一个忙碌的处理器并返回其编号。所有条件不满足时,会直接返回传入的hrtimer_cpu_base结构体指针。
接下来分析hrtimer_callback_running函数,用于检查要迁移的定时器是否正是当前正在处理的定时器。hrtimer_check_target函数则用于检查定时器的到期时间是否早于要迁移到的CPU上即将到期的时间。如果高分辨率定时器的到期时间比目标CPU上的所有定时器到期时间还要早,并且目标CPU不是当前CPU,那么激活目标CPU会涉及到通知该CPU重新编程定时器,这通常不如直接在当前CPU上激活定时器来得简单。因此,如果迁移操作与实际激活操作没有关系,即使从get_target_base函数获得的base与定时器中指定的base相同,迁移操作也会进行。鹿鼎记 源码
在迁移过程中,内核会临时将定时器的hrtimer_clock_base结构体变量设置为全局变量migration_base的指针。这个全局变量仅用于在获得定时器所属CPU的hrtimer_cpu_base结构体变量时,通过判断base变量是否等于migration_base的指针来判断定时器是否正在迁移。这样的设计可以在未正式加锁之前过滤掉很多情况,从而提高速度。
文章福利提供Linux内核技术交流群,包含学习书籍、视频资料,前名可额外获得价值的内核资料包(含视频教程、电子书、实战项目及代码)。
内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂
在低精度模式下,高分辨率定时器层通过普通(低分辨率)定时器层驱动。当Tick到来时,其处理函数会调用hrtimer_run_queues函数通知高分辨率定时器层。每次调用该函数时,都会判断是否可以切换到高精度模式。如果可以切换,会调用hrtimer_switch_to_hres完成切换并退出。如果不需要切换,则从时间维护层获得当前时间和各种偏移值,并设置到所有的hrtimer_clock_base结构体中。如果当前时间不早于softirq_expires_next变量的值,表示“软”定时器已到期,需要激活软中断处理程序。在软中断处理程序中,首先调用hrtimer_update_base函数更新当前时间,并在适当时候执行,处理到期的fqrouter源码“软”定时器。该处理程序会遍历所有指定类型(“软”或“硬”)的到期定时器,判断定时器的“软”到期时间是否已到,处理到期定时器,并循环取下一个要到期的定时器。最后,会调用hrtimer_reprogram函数对底层定时事件设备进行重编程。
在高精度模式下,周期处理函数hrtimer_interrupt在定时事件设备到期后调用。处理过程包括激活HRTIMER_SOFTIRQ软中断处理程序,处理所有“软”定时器,并对底层定时事件设备进行重编程。重编程确保设备在到期后能正确触发中断,同时避免在一次中断中处理过多定时器,以防止超时。通过查找和设置到期时间时使用“硬”到期时间,而在处理定时器时使用“软”到期时间,内核能尽量减少中断调用,提高性能。
低精度模式切换到高精度模式的hrtimer_switch_to_hres函数通过调用tick_init_highres函数实现切换,将定时事件设备切换到单次触发模式,并设置中断处理函数为hrtimer_interrupt。一旦完成切换,底层定时事件设备将始终工作在单次触发模式。切换成功后,必须找到最近到期的定时器,并用其到期事件对定时事件设备进行重编程,确保设备能正确响应到期。
在高精度模式下,中断处理程序通过直接调用__hrtimer_run_queues函数处理所有“硬”定时器,并激活HRTIMER_SOFTIRQ软中断处理程序来处理所有“软”定时器。在高精度模式下,底层定时事件设备始终处于单次触发模式,因此在到期后必须进行重编程。如果编程失败,重试三次后,适当延迟到期事件后再次尝试编程,并强制执行。
使用实例展示了高精度定时器在实际应用中的精度,时间戳显示其定时精度可达到ms级别。
C#的Timer定时器是属于线程吗?
同事询问了关于C#中System.Windows.Forms.Timer的归属问题,它究竟是前台线程还是后台线程。实际上,这个控件的工作原理与Windows Forms的UI线程紧密相关。System.Windows.Forms.Timer基于Windows的消息循环机制运作,这个机制包含一个消息队列,一个无限循环处理消息的窗口消息处理函数。
Timer的事件触发是通过将Tick事件与WM_TIMER消息关联。当定时器启动后,它会在每个预设的Interval时间间隔后,将WM_TIMER消息放入应用程序的消息队列。应用程序在消息循环中处理这些消息,包括接收和处理WM_TIMER,从而触发Timer的Tick事件。
尽管我们可以通过源码查看其内部逻辑,但关键在于Timer的启动和事件触发并非通过创建新线程,而是利用Windows的消息传递系统。System.Windows.Forms.Timer的实例并不是独立的线程,而是与UI线程同步的。当TimerNativeWindow的StartTimer方法调用SetTimer函数时,就是在UI线程的消息队列中插入了定时器消息,这表明它并不独立运行,而是依赖于主线程的活动。
总结来说,System.Windows.Forms.Timer是UI线程的一部分,它不是独立的线程,而是通过Windows消息循环与UI线程紧密结合,实现定时任务的执行。因此,它并非线程的概念,而是UI线程的事件驱动机制的一部分。
LiteOS:剖析时间管理模块源代码
LiteOS的时间管理模块基于系统时钟,分为两个关键部分:SysTick中断和应用程序时间服务。SysTick中断为任务调度提供稳定的时钟节拍,而应用程序时间服务则包括时间转换、统计和延迟等功能,这些都是通过系统时钟的周期性中断实现的。
系统时钟通常由定时器/计数器驱动,周期性地产生中断,每秒的Tick数由用户配置决定。比如,如果配置为每秒个Tick,那么每个Tick代表1毫秒。Cycle是系统最小的计时单位,由主时钟频率决定。在 MHz的CPU中,1秒内会产生,,个Cycle。
用户在秒、毫秒级别计时,而操作系统则使用Tick作为基本单位。在需要执行任务挂起或延迟操作时,时间管理模块会处理Tick与用户时间单位之间的转换。
源代码可在LiteOS开源站点获取,涉及的文件包括kernel\include\los_tick.h、kernel\base\include\los_tick_pri.h等,具体可以参考gitee.com/LiteOS/LiteOS...。本文将通过分析STMFIDiscovery板子的源码,深入剖析时间管理模块的初始化、配置和关键函数。
首先,时间管理模块的初始化和启动过程涉及系统时钟配置和OsTickInit函数,配置项包括系统时钟和每秒Tick数。然后是OsTickStart函数,启动时会初始化定时器并启用Tick中断。
此外,时间管理模块提供的时间转换、统计和延时管理功能,如从毫秒到Tick的转换,获取Tick内包含的Cycle数,以及微秒和毫秒级别的等待。这些功能的实现细节也在本文中进行了讲解。
总结来说,LiteOS的时间管理模块是任务调度和时间服务的核心,通过深入源码理解,开发者可以更好地利用这些功能进行高效的时间处理。
nodejs .0.0源码分析之setTimeout
本文深入剖析了Node.js .0.0版中定时器模块的实现机制。在.0.0版本中,Node.js 对定时器模块进行了重构,改进了其内部结构以提高性能和效率。下面将详细介绍定时器模块的关键组成部分及其实现细节。 首先,让我们了解一下定时器模块的组织结构。Node.js 采用了链表和优先队列(二叉堆)的组合来管理定时器。链表用于存储具有相同超时时间的定时器,而优先队列则用来高效地管理这些链表。 链表通过 TimersList数据结构进行管理,它允许将具有相同超时时间的定时器归类到同一队列中。这样,Node.js 能够快速定位并处理即将到期的定时器。 为了进一步优化性能,Node.js 使用了一个优先队列(二叉堆)来管理所有链表。在这个队列中,每个链表对应一个节点,根节点表示最快到期的定时器。在时间循环(timer阶段)时,Node.js 会从二叉堆中查找超时的节点,并执行相应的回调函数。 为了实现这一功能,Node.js 还维护了一个超时时间到链表的映射,以确保快速访问和管理定时器。 接下来,我们将从 setTimeout函数的实现开始分析。这个函数主要涉及 new Timeout和 insert两个操作。其中,new Timeout用于创建一个对象来存储定时器的上下文信息,而 insert函数则用于将定时器插入到优先队列中。 具体地,Node.js 使用了 scheduleTimer函数来封装底层计时操作。这个函数通过将定时器插入到libuv的二叉堆中,为每个定时器指定一个超时时间(即最快的到期时间)。在执行时间循环时,libuv会根据这个时间判断是否需要触发定时器。 当定时器触发时,Node.js 会调用 RunTimers函数来执行回调。回调函数是在Node.js初始化时设置的,负责处理定时器触发时的具体逻辑。在回调函数中,Node.js 遍历优先队列以检查是否有其他未到期的定时器,并相应地更新libuv定时器的时间。 最后,Node.js 在初始化时通过设置 processTimers函数作为超时回调来确保定时器的正确执行。通过这种方式,Node.js 保证了定时器模块的初始化和定时器触发时的执行逻辑。 本文通过详尽的分析,展示了Node.js .0.0版中定时器模块的内部机制,包括其组织结构、数据管理和回调处理等关键方面。虽然本文未涵盖所有细节,但对于理解Node.js定时器模块的实现原理提供了深入的洞察。对于进一步探索Node.js定时器模块的实现,特别是与libuv库的交互,后续文章将提供更详细的分析。