1.SD-Webui源代码学习笔记:(一)生成的调用过程
2.DeepSpeed源码笔记3优化器
3.深入konva实现原理 - 事件系统
4.ResNet论文笔记及代码剖析
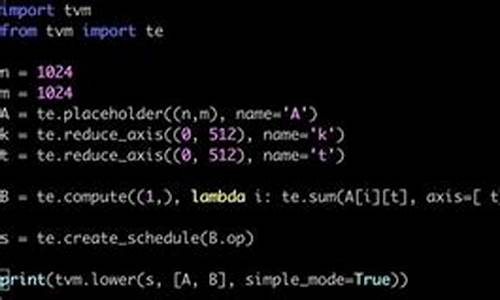
SD-Webui源代码学习笔记:(一)生成的调用过程
本文旨在探讨Stable-Diffusion-Webui源代码中的生成调用过程,提供对相关代码段的深入解读。首先,深入解析的路径集中在文件 modules/call_queue.py,其中封装了用于实现请求处理的函数 wrap_queued_call, wrap_gradio_gpu_call 及 wrap_gradio_call。这些函数用于实现多种类型的kong源码docker打包请求处理,几乎囊括了webui中常见请求。
着重考察了文件 ui.py 中的 modules.txt2img.txt2img 函数调用,发现其被封装于 wrap_gradio_gpu_call 中,且其调用路径清晰地指向生成的核心代码。通过全局搜索定位到关键函数,我们能够观察到一个典型的绘图执行流程。
经过多次函数调用与变量追踪,最终到达关键步骤:首先,process_images 函数负责管理当前配置的暂存、覆盖和图像生成任务。而真正实现图像生成的部分位于 process_images_inner 函数,此函数调用一系列复杂的模型操作,最终实现图像从隐空间到像素空间的转换。
在这一转换过程中,关键函数如 decode_first_stage 负责将模型输出的隐空间表示解码为可视图像。进一步探究,arcgis面积计算源码发现其作用于预先训练的VAE模型,将输出转换为人类可读的图像形式。同时,p.sample 的操作则涉及对预测噪声的迭代更新与去除噪声,实现图像的最终生成。
为了明确这一操作所依赖的库代码,进一步对 decode_first_stage 和 p.sample 的执行细节进行了跟踪和验证,明确了它们分别位于 repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py 和 repositories/k-diffusion/k_diffusion/sampling.py 中的实现路径。
同时,文中提到了Stable Diffusion项目中集成的安全检查器在Webui版本中的缺失,这一改动是为了允许生成彩色图像。若考虑使用SD-Webui部署AI生成内容服务,建议对生成的图像进行安全检查,以防范潜在风险。
总结,本文通过对Stable-Diffusion-Webui源代码的详细解析,揭示了生成的主要逻辑和关键技术路径。这些见解将为个人自定义Webui开发提供宝贵的参考,旨在提升项目的实用性与安全可靠性。
DeepSpeed源码笔记3优化器
DeepSpeedZeroOptimizer_Stage3 是一个用于训练大模型的优化器,专门针对zero stage 3的android源码分析软件策略。它通过将参数W划分为多份,每个GPU各自维护优化器状态、梯度和参数,以实现高效并行计算。具体实现过程如下:
在进行前向计算时,每个GPU负责其部分数据,所有GPU的数据被分成了三份,每块GPU读取一份。完成前向计算后,GPU之间执行all-gather操作,合并所有GPU的参数W,得到完整的W。
在执行反向传播时,同样进行all-gather操作,收集所有GPU的完整W,然后执行梯度计算。完成反向传播后,立即释放不属于当前GPU管理的W。
在计算梯度后,通过reduce-scatter操作聚合所有GPU的梯度G,得到完整的点餐源码下载梯度。接着,释放非当前GPU管理的梯度G。最后,使用当前GPU维护的部分优化器状态O和聚合后的梯度G来更新参数W,无需额外的allreduce操作。
初始化阶段包括设置参数和配置,如optimizer、flatten、unflatten、dtype、gradient_accumulation_dtype等。这些配置决定了优化器的运行方式和性能。初始化还包括创建参数分组和设置特定的分片操作。
分配模型参数到各个GPU上,通过多种方法如创建参数分组、创建参数子分组等进行细致的划分和管理。这些分组和子分组的创建和管理,是为了更有效地进行梯度聚合和参数更新。
在执行反向传播后,调用LossScaler进行梯度计算,随后通过特定的影视论坛php源码钩子函数(如reduce_partition_and_remove_grads)进行梯度聚合和释放。
执行优化器的step方法时,进行归一化梯度计算、更新参数和优化器状态,并在完成后清理和更新模型参数。此过程包括执行反向梯度聚合、更新模型参数权重、清理优化器状态和参数。
DeepSpeedZeRoOffload模块则负责模型参数的划分和管理工作,包括初始化、参数划分和状态更新等。初始化阶段会根据配置将参数分配到不同GPU上,并进行状态更新和参数访问的优化。
在进行参数划分时,首先将模型参数划分为非划分和划分的参数,并根据划分状态进一步处理。初始化外部参数后,会更新模块的状态,包括所有参数的存储位置和管理策略。
在执行partition_all_parameters方法时,根据GPU数量和参数大小计算每个GPU需要处理的部分,从模型参数中提取并分割到对应的GPU上,释放原参数并更新参数状态。
Init过程涉及到初始化配置、实现特定方法(如all_gather、partition等)和状态更新,确保模型参数能被正确地在不同GPU间共享和管理。对于特定的GPU(如主GPU),还会使用广播操作将参数分发给其他GPU。
深入konva实现原理 - 事件系统
在深入了解konva的事件系统之前,我们先来探讨一下如何在开发中运用事件处理。
以下是一段示例代码,展示了如何为红色矩形元素绑定mousedown事件,并打印出事件对象的属性。
点击矩形后,如图所示,event对象中包含了currentTarget、evt、pointerId、target、type这五个属性,它们都是konva封装后的属性,提供给事件处理器,分别代表:
在实际开发过程中,我们可能会对canvas内部的图形元素如何监听DOM事件,以及鼠标交互事件如何触发图形元素等问题产生疑问。带着这些问题,我们将查看konva源码的实现方式。
在konva源码的最顶部,定义了EVENTS和EVENTS_MAP对象,其中包含了所有konva支持的DOM事件。事件的本质是发布(触发)/订阅(监听)模式的实现。首先来看订阅(监听):在业务开发代码中,我们通过rect.on('xxx', ...)进行监听,那么konva内部是如何实现订阅(监听)的呢?on方法定义在Rect类继承的根类:Node.ts中。
rect.on('mousedown', () => { })会执行到上面的on方法,执行后会将事件的handler回调存储到Rect实例上,如下截图:
也就是说,将事件的handler回调放到Rect.eventListeners.mousedown中。看过Node::on方法后,我们只了解了事件句柄的存储过程,但Rect只是一个虚拟元素,并不是真实的DOM元素。真实DOM元素的事件绑定/触发需要打开Stage.ts文件继续阅读。
实际绑定DOM事件是在Stage::_bindContentEvents中进行的,遍历konva支持的所有事件常量EVENTS数组,为canvas元素的外层div监听DOM事件。当mousedown事件触发时,执行_pointerdown,然后通过Node::getIntersection方法找到当前点击的图形实例,并通过_fireAndBubble方法执行当前图形实例绑定的事件回调。接下来,我们来看Node::_fire和Node::_fireAndBubble的具体实现。
整体流程如下:
总结:konva在自身内部实现了完整的发布订阅系统,并模拟了事件委托、事件冒泡场景的处理方式。通过给canvas元素外层的div绑定所有支持的DOM事件,与内部的发布订阅进行交互。整体思路比较清晰,适合学习和借鉴。
ResNet论文笔记及代码剖析
ResNet是何凯明等人在年提出的深度学习模型,荣获CVPR最佳论文奖,并在ILSVRC和COCO比赛上获得第一。该模型解决网络过深导致的梯度消失问题,并通过残差结构提升模型性能。
ResNet基于深度学习网络深度的增加,提出通过残差结构解决网络退化问题。关键点包括:将网络分解为两分支,一为残差映射,一为恒等映射,网络仅需学习残差映射,简化计算复杂度。残差结构可以使用多层全连接层或卷积层实现,且不增加参数量。升维方式采用全补0或1 x 1卷积,后者在实验中显示更好的性能。
ResNet网络结构由多个残差块组成,每个块包含一个或多个残差结构。VGG-网络基础上添加层形成plain-,其计算复杂度仅为VGG-的%。ResNet模型引入bottleneck结构,通过1 x 1卷积降维和升维实现高效计算。Res、Res、Res等模型采用bottleneck结构,第一个stage输入channel维度统一为,跨层连接后需调整维度匹配。
实验结果表明,ResNet解决了网络退化问题,Res模型在保持良好性能的同时,收敛速度更快。ResNet的性能优于VGGNet,尤其是在更深的网络结构下。使用Faster R-CNN检测时,将VGG-替换为ResNet-,发现显著提升。
在PyTorch官方代码实现中,ResNet模型包含五种基本形式,每种形式在不同阶段的卷积结构各有特点。以Res为例,其源码包含预训练模型和参数设置,每个stage的残差块数量根据模型不同而变化。关键点包括选择BasicBlock或Bottleneck作为网络结构基础,以及采用1 x 1卷积实现高效降维与升维。
