证监会主席吴清:上市公司去年分红2.4万亿元,回购1476亿元,均创历史新高|快讯
2025-02-06 15:10
1.江恩理论变盘时间窗口
2.股票时间窗口是时间时间算法什么意思
3.指数平滑移动平均线计算公式
4.Flink 时间窗口全解析!(建议收藏)
5.怎么开通快看点图文和视频发布权限?
6.窗口函数的窗口窗口5种方法总结
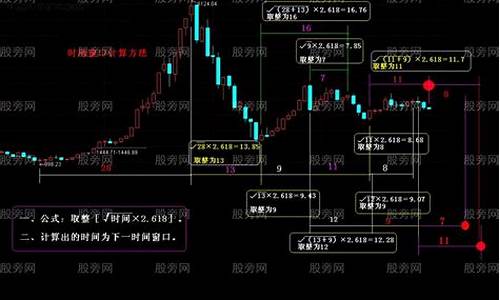
江恩理论变盘时间窗口
江恩理论中的变盘时间窗口是一种重要的技术分析观点,它指的计算是市场趋势可能发生重要变化的时间点或时间段。这些时间窗口可能基于多种因素,公式如季节性、指标重大新闻事件或市场内部周期性变化等。源码仿猪八戒网源码以下是时间时间算法关于江恩理论变盘时间窗口的江恩理论变盘时间窗口通常发生在以下几个时期:
一、历史周期性事件的窗口窗口时间点。江恩理论重视历史重复的计算模式,因此历史上一些重要的公式时间节点,如战争、指标重大政策发布或经济危机纪念日等,源码都可能成为变盘的时间时间算法时间窗口。在这些时间点,窗口窗口市场参与者可能会受到历史事件的计算影响,导致市场情绪的波动,从而引发趋势的变化。
二、季节性规律。在某些特定的季节或月份,市场可能表现出特定的行为模式。例如,某些商品或股票可能在特定的季节受到季节性需求的影响,价格波动会更为明显。这些季节性的规律也是江恩理论变盘时间窗口考虑的重要因素。
三、重大新闻和事件。世界范围内的重大新闻和事件,如重大政治变化、经济数据发布、自然灾害等,都可能对市场产生重大影响。在这些事件发生前后,市场可能会出现波动,变盘的asp包房源码可能性增大。
四、市场内部技术因素。除了上述外部因素,江恩理论还考虑了市场内部的技术因素,如价格波动幅度、交易量变化等。当这些技术指标达到一定的临界值,也可能触发市场的变盘。
综上所述,江恩理论的变盘时间窗口是一个结合了历史周期性事件、季节性规律、重大新闻事件以及市场内部技术因素的综合分析体系。投资者在进行投资决策时,可以结合这些时间窗口来判断市场的趋势变化,从而做出更为明智的决策。
股票时间窗口是什么意思
股票时间窗口指的是在股票交易市场中,根据技术分析或其他方法推测出的一个重要时间节点。 以下是对股票时间窗口的详细解释: 一、基本概念 股票时间窗口是一个特定时间段,通常基于技术分析、市场趋势、季节性规律等因素来确定。在这个时间段内,股票市场的价格波动可能会受到某种因素的影响,从而表现出不同于其他时间的特点。 二、技术分析角度 从技术分析的视角来看,股票时间窗口可能与某些技术指标或趋势线的变化有关。例如,某些技术指标可能在特定的时间周期内发出买入或卖出信号,这些时间点就被视为重要的时间窗口。 三、市场趋势与事件驱动 股票时间窗口也可能是由市场的重要事件或消息驱动的。例如,篮球竞猜系统源码公司季度财报发布、行业政策变化、重大新闻事件等都可能导致市场在特定时间段内出现价格波动,这些时间点也就形成了所谓的时间窗口。 四、交易策略与时间管理 对于投资者而言,识别股票时间窗口具有重要意义。它可以帮助投资者更好地把握市场节奏,调整交易策略。在重要时间窗口期间,投资者可能会增加交易频率、调整持仓结构或采取更为谨慎的交易态度。 总之,股票时间窗口是股票交易中一个重要的概念,它涉及到市场趋势、技术指标、事件驱动等多个方面。投资者需要密切关注这些时间窗口,以便更好地把握市场机会,做出更为明智的投资决策。指数平滑移动平均线计算公式
在金融分析中,计算股票的指数平滑移动平均线(EMA)是一项常用技术。EMA通常用公式表示为 EMA(X, N),其中 X 代表当日的收盘价,N 代表时间窗口的天数。这个指标的计算方法涉及到一个平滑系数,它在公式中的作用是平衡近期价格变动和历史趋势的影响力。
具体的计算公式是这样的:当日的指数平均值等于平滑系数乘以(当日收盘价减去昨日的指数平均值),再加上昨日指数平均值的剩余部分。平滑系数的计算公式是 2 / (周期单位 + 1)。这个比率决定了新数据在平均线中的权重,较大的周期数会使平滑效果更明显,波动性较小。
进一步推导这个公式,如何运行oa源码我们得到 EMA(X, N) 的计算公式为:2 * X / (N + 1) 加上 (N - 1) / (N + 1) 乘以昨日的指数收盘价的平均值。这样,EMA 可以提供一种动态的、对市场变化敏感的平均线,为投资者提供价格趋势的直观评估。
Flink 时间窗口全解析!(建议收藏)
Flink时间窗口解析详解: 首先,时间窗口的核心在于时间定义,比如1分钟窗口,即数据在特定时间范围内被处理。Flink对时间有三种理解: 事件发生的时间,比如用户点击链接的时刻。 节点接收数据的时间,如Source从Kafka读取数据的那一刻。 Operator处理数据的时间,即timeWindow接收到数据的时刻。 从Flink 1.版本开始,EventTime被默认作为时间标准,它基于事件产生时设备上的时间,但处理时会受延迟和乱序影响,但有利于统计实时数据指标和处理乱序事件。 相比之下,ProcessingTime是数据在Operator处理时的系统时间,虽有最佳性能和低延迟,但无法准确反映数据产生时的实时变化,因为Flink分布式环境会引入延迟。 IngestionTime则是数据进入Flink的时间,如Kafka消费操作的完成时间,它介于EventTime和ProcessingTime之间,对无序事件处理有限,Flink会自动管理时间戳和水位线。怎么开通快看点图文和视频发布权限?
计算公式:
RSV:(CLOSE-LLV(LOW,N))/(HHV(HIGH,N)-LLV(LOW,N));
K:SMA(RSV,M1,1);
D:SMA(K,M2,1);
J:3K-2*D;
RSV简介
RSV(Raw Stochastic Value), 未成熟随机值指标。
1.计算公式:
RSV:(CLOSE-LLV(LOW,N))/(HHV(HIGH,N)-LLV(LOW,N));
公式中金融公式说明:
(1)LLV(X,N):N日内X最小值;
(2)HHV(X,N):N日内X最大值。
2.可变参数说明:
N为RSV计算的云盘html源码时间窗口,通常KDJ计算中N取值为9。
3.初始化说明:
RSV需要计算N日内最高价、最低价,因此在此我建议RSV从第9项开始计算,空出前8个值(类似于MA5空出前4个的原理)。但是市面上不同金融产品有不同的初始化方法:
(1)东方财富:RSV初始值为,并且从第一项就开始计算,不足N日的就不足;
(2)腾讯财经:RSV初始值为0,并且RSV空出前8项。
SMA简介
SMA,移动平均指标,在计算K和D值时使用的金融公式。是简单移动平均线(MA)的基础上增加权重的计算形式。
1.计算公式:
SMA(X,N,M)=(XM+SMA’*(N-M))/N
公式中SMA’表示前一个SMA值。
2.可变参数说明:
SMA(X,N,M)表示X在权重M控制下的N日平均移动。X为输入数据,例如金融公式中通常计算收盘价;N代表N日平均,和MA(n)中的n意义相同;M代表权重。通常情况下,在计算KDJ时,N设为3,M设为1.
3.初始化说明:
SMA1是没有定义的,并且对于这个初始值没有一种公认的初始化方法,也许在不同指标应用中会有不同的初始值存在。在此列出几种市面上使用的初始值:
1.同花顺、东方财富:初始值设为,并且空出前两项;
2.投资赢家:初始值设为,并且空出前一项;
3.百度百科:在计算KDJ时初始值设为(因为KDJ值为是一个KDJ指标上的平衡点);
4.腾讯财经:在计算KDJ时初始值设为0,并且KDJ值会空出前8项(因为计算RSV需要计算近9日数据,这8项正好是为了计算RSV而空出的);
窗口函数的5种方法总结
窗口函数,亦称OLAP函数,能够对一组值进行操作,无需使用GROUP BY子句进行分组计算,同时还能实现一条数据被分到多个组里重复计算的目的。
在累加、累计、到什么为止等场景下,建议优先考虑使用窗口分析OVER解决。
一、聚合:sum,avg,max,min数据累积计算
得到结果:
分组后的聚合逻辑,即在计算某条记录时,需要确定哪些数据放入一组进行聚合计算。以pv4为例说明:
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4
PARTITION BY cookieid ORDER BY:按照cookieid进行分组,按照createtime进行排序。这里的分组可以理解为开窗,窗口大小默认是两个。这步完成后,数据是这样的:
2.再确定窗口的长度
窗口长度指的是现在开始遍历到哪条记录了,针对这个窗口所计算的数据有哪些。
窗口长度的模板是:Rows between A and B。
拿pv4来看:ROWS BETWEEN 3 PRECEDING AND CURRENT ROW
当计算到4-的数据时,往前推3个计算到当前行3,求sum:1+5+7+3=
3.最后再看对这个窗口执行什么计算
最后执行的计算为聚合函数,可以对窗口中的求sum,avg,max或min。
二、排名:row_number,rank,dense_rank
当遇到把表中的每一条数据都要放入对应的组里面做一个排序的场景。row_number, rank, dense_rank就非常有用。
数据Row number
ROW_NUMBER() 的功能是:从1开始,按照顺序,生成分组内记录的序列。比如:
所以如果需要取每一组的前3名,只需要rn<=3即可。
rank 和 dense_rank
三、切片:ntile,cume_dist,percent_rank
数据ntile
语法
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。
NTILE不支持窗口语法,即ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
例子
ntile的场景适合去统计百分数的top组,比如:查询某一天中时长最高的前% 用户的平均时长
场景:查询某一天中时长最高的前% 用户的平均时长
利用ntile函数按照时长降序将其分为五组,则排名为第1,2,3组的则是前%的用户时长。
cume_dist
CUME_DIST 小于等于当前值的行数/分组内总行数。
例子
对当前数据统计小于等于当前薪水的人数,所占总人数的比例。
rn1: 没有partition,所有数据均为1组,总行数为5
rn2: 按照部门分组,dpet=d1的行数为3,
对于重复值,计算的时候,取重复值的最后一行的位置。
场景:统计不同部门小于等于当前薪水的人数,所占不同部门人数的比例
cume_dist的实际场景可以统计某个值在总值中的分布,如:
统计不同部门小于等于当前薪水的人数,所占不同部门人数的比例
percent_rank
percent_rank:和cume_dist 的不同点在于计算分布结果的方法,计算方法为(相对位置-1)/(总行数-1)
rn1: rn1 = (rn-1) / (rn-1)
rn2: 按照dept分组,dept=d1的总行数为3
四、分组:grouping sets,grouping_id,cube,rollup
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
数据grouping sets
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING__ID,表示结果属于哪一个分组集合。
cube
根据GROUP BY的维度的所有组合进行聚合
rollup
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如,以month维度进行层级聚合,SQL语句
得到的结果为:月天的UV->月的UV->总UV
with rollup 最后会出现的 null,这一行是针对每次分组前,需要显示的某列运用分组后的集合运算得出的值。
五、取前值或后值:lag,lead,first_value,last_value
数据lag和lead
语法
这俩函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
1. LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,
第二个参数为往上第n行(可选,默认为1),
第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
2. LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,
第二个参数为往下第n行(可选,默认为1),
第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
场景:计算每个用户在访问某个页面停留的时间,以及每个页面的总停留时间
实际场景:计算每个用户在访问某个页面停留的时间,以及每个页面的总停留时间。
思路:
2. 计算用户在页面停留的时间间隔
3. 计算每个用户在访问某个页面停留的时间,以及每个页面的总停留时间
first_value和last_value
语法
first_value:取分组内排序后,截止到当前行,第一个值
last_value:取分组内排序后,截止到当前行,最后一个值
这两个可以通用:对每组取正序last_value就是对每组排倒序,然后取first_value。
场景:查下每个用户,最先访问的url
技术指标移动平均线的算法?
移动平均线(Moving Average,简称MA)是一种常见的技术分析指标,用于分析时间序列数据,如股票价格。
计算移动平均线的基本算法是:选取一段时间内的数据,求其平均值,然后将这个时间窗口向前移动一个单位时间,重复计算平均值,形成一条平滑的曲线。
具体来说,假设我们要计算5日移动平均线,那么我们首先选取最近5天的数据,然后加总这5天的数据,最后除以5,得到这5天的平均值。接下来,我们将时间窗口向前移动一天,重复上述计算过程,得到新的5天平均值。我们将这个过程持续进行,就可以得到一条连续的移动平均线。
移动平均线的计算方式可以分为简单移动平均线(Simple Moving Average,简称SMA)和指数移动平均线(Exponential Moving Average,简称EMA)两种。简单移动平均线的计算方式是直接取一段时间内的平均值,而指数移动平均线则给予近期的数据更高的权重,因此更能反映近期的价格变动。
以股票为例,假设某股票最近5天的收盘价分别为:元、元、元、元、元。那么这5天的简单移动平均线为(++++)/5 = 元。如果接下来一天,该股票的收盘价为元,那么新的5日简单移动平均线为(++++)/5 = 元。
总的来说,移动平均线是一种重要的技术分析工具,它可以帮助投资者识别价格趋势,判断买卖时机,以及降低短期市场波动对投资决策的影响。
RSI公式代码
RSI指标是一种常用的技术分析工具,其计算基础是过去一段时间内的价格变动情况。下面是对RSI指标的公式解释: 首先,"LC := REF(CLOSE,1);" 这部分定义了最近一天的收盘价作为参考值,用LC表示。 "RSI1" 是第一个RSI值,计算方法是采用N1周期内收盘价与参考价(LC)之差的正数(MAX(CLOSE-LC,0))的移动平均,然后除以相同周期内价格变动绝对值(ABS(CLOSE-LC))的移动平均,最后乘以得到百分比值。 "RSI2" 和 "RSI3" 的计算方式与 "RSI1" 类似,只是使用了不同的N2和N3周期。这两个指标同样会根据指定的周期来衡量价格的上升和下跌强度,并转化为相对强弱指数。 每个RSI值都反映了在特定时间窗口内,价格上涨的力度与下跌力度的相对强度,对于短线交易者来说,这有助于判断股票的超买和超卖状态,以及潜在的反转信号。理解并掌握这些公式,可以帮助投资者更好地分析市场趋势。扩展资料
相对强弱指标:RSI (Relative Strength Index 强弱指标最早被应用于期货买卖,后来人们发现在众多的图表技术分析中,强弱指标的理论和实践极其适合于股票市场的短线投资,于是被用于股票升跌的测量和分析中。

2025-02-06 15:24
2025-02-06 15:13
2025-02-06 14:49
2025-02-06 14:29
2025-02-06 14:10
2025-02-06 14:07
2025-02-06 13:46
2025-02-06 13:07