欢迎来到皮皮网官网
1.å¦ä½ç¨Pythonåç¬è«
2.鹅厂微创新Golang缓存组件TCache介绍
3.leveldb之数据存储结构
4.布隆过滤器(Bloom Filter)详解
5.å¦ä½ç¨JAVAåä¸ä¸ªç¥ä¹ç¬è«
å¦ä½ç¨Pythonåç¬è«
1ï¼é¦å ä½ è¦æç½ç¬è«ææ ·å·¥ä½ã
æ³è±¡ä½ æ¯ä¸åªèèï¼ç°å¨ä½ 被æ¾å°äºäºèâç½âä¸ãé£ä¹ï¼ä½ éè¦æææçç½é¡µé½çä¸éãæä¹åå¢ï¼æ²¡é®é¢åï¼ä½ å°±é便ä»æ个å°æ¹å¼å§ï¼æ¯å¦è¯´äººæ°æ¥æ¥çé¦é¡µï¼è¿ä¸ªå«initial pagesï¼ç¨$表示å§ã
å¨äººæ°æ¥æ¥çé¦é¡µï¼ä½ çå°é£ä¸ªé¡µé¢å¼åçåç§é¾æ¥ãäºæ¯ä½ å¾å¼å¿å°ä»ç¬å°äºâå½å æ°é»âé£ä¸ªé¡µé¢ã太好äºï¼è¿æ ·ä½ 就已ç»ç¬å®äºä¿©é¡µé¢ï¼é¦é¡µåå½å æ°é»ï¼ï¼æä¸ä¸ç¨ç®¡ç¬ä¸æ¥ç页é¢æä¹å¤ççï¼ä½ å°±æ³è±¡ä½ æè¿ä¸ªé¡µé¢å®å®æ´æ´ææäºä¸ªhtmlæ¾å°äºä½ 身ä¸ã
çªç¶ä½ åç°ï¼ å¨å½å æ°é»è¿ä¸ªé¡µé¢ä¸ï¼æä¸ä¸ªé¾æ¥é¾åâé¦é¡µâãä½ä¸ºä¸åªèªæçèèï¼ä½ è¯å®ç¥éä½ ä¸ç¨ç¬åå»çå§ï¼å ä¸ºä½ å·²ç»çè¿äºåãæ以ï¼ä½ éè¦ç¨ä½ çèåï¼åä¸ä½ å·²ç»çè¿ç页é¢å°åãè¿æ ·ï¼æ¯æ¬¡çå°ä¸ä¸ªå¯è½éè¦ç¬çæ°é¾æ¥ï¼ä½ å°±å æ¥æ¥ä½ èåéæ¯ä¸æ¯å·²ç»å»è¿è¿ä¸ªé¡µé¢å°åãå¦æå»è¿ï¼é£å°±å«å»äºã
好çï¼ç论ä¸å¦æææç页é¢å¯ä»¥ä»initial pageè¾¾å°çè¯ï¼é£ä¹å¯ä»¥è¯æä½ ä¸å®å¯ä»¥ç¬å®ææçç½é¡µã
é£ä¹å¨pythonéæä¹å®ç°å¢ï¼
å¾ç®å
import Queue
initial_page = "åå§å页"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #ä¸ç´è¿è¡ç´å°æµ·æ¯ç³ç
if url_queue.size()>0:
current_url = url_queue.get() #æ¿åºéä¾ä¸ç¬¬ä¸ä¸ªçurl
store(current_url) #æè¿ä¸ªurl代表çç½é¡µåå¨å¥½
for next_url in extract_urls(current_url): #æåæè¿ä¸ªurléé¾åçurl
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
åå¾å·²ç»å¾ä¼ªä»£ç äºã
ææçç¬è«çbackboneé½å¨è¿éï¼ä¸é¢åæä¸ä¸ä¸ºä»ä¹ç¬è«äºå®ä¸æ¯ä¸ªé常å¤æçä¸è¥¿ââæç´¢å¼æå ¬å¸é常æä¸æ´ä¸ªå¢éæ¥ç»´æ¤åå¼åã
2ï¼æç
å¦æä½ ç´æ¥å å·¥ä¸ä¸ä¸é¢ç代ç ç´æ¥è¿è¡çè¯ï¼ä½ éè¦ä¸æ´å¹´æè½ç¬ä¸æ´ä¸ªè±ç£çå 容ãæ´å«è¯´Googleè¿æ ·çæç´¢å¼æéè¦ç¬ä¸å ¨ç½çå 容äºã
é®é¢åºå¨åªå¢ï¼éè¦ç¬çç½é¡µå®å¨å¤ªå¤å¤ªå¤äºï¼èä¸é¢ç代ç å¤ªæ ¢å¤ªæ ¢äºã设æ³å ¨ç½æN个ç½ç«ï¼é£ä¹åæä¸ä¸å¤éçå¤æ度就æ¯N*log(N)ï¼å 为ææç½é¡µè¦éåä¸æ¬¡ï¼èæ¯æ¬¡å¤éç¨setçè¯éè¦log(N)çå¤æ度ãOKï¼OKï¼æç¥épythonçsetå®ç°æ¯hashââä¸è¿è¿æ ·è¿æ¯å¤ªæ ¢äºï¼è³å°å å使ç¨æçä¸é«ã
é常çå¤éåæ³æ¯ææ ·å¢ï¼Bloom Filter. ç®å讲å®ä»ç¶æ¯ä¸ç§hashçæ¹æ³ï¼ä½æ¯å®çç¹ç¹æ¯ï¼å®å¯ä»¥ä½¿ç¨åºå®çå åï¼ä¸éurlçæ°éèå¢é¿ï¼ä»¥O(1)çæçå¤å®urlæ¯å¦å·²ç»å¨setä¸ãå¯æ天ä¸æ²¡æç½åçåé¤ï¼å®çå¯ä¸é®é¢å¨äºï¼å¦æè¿ä¸ªurlä¸å¨setä¸ï¼BFå¯ä»¥%ç¡®å®è¿ä¸ªurl没æçè¿ãä½æ¯å¦æè¿ä¸ªurlå¨setä¸ï¼å®ä¼åè¯ä½ ï¼è¿ä¸ªurlåºè¯¥å·²ç»åºç°è¿ï¼ä¸è¿ææ2%çä¸ç¡®å®æ§ã注æè¿éçä¸ç¡®å®æ§å¨ä½ åé çå å足å¤å¤§çæ¶åï¼å¯ä»¥åå¾å¾å°å¾å°ãä¸ä¸ªç®åçæç¨:Bloom Filters by Example
注æå°è¿ä¸ªç¹ç¹ï¼urlå¦æ被çè¿ï¼é£ä¹å¯è½ä»¥å°æ¦çéå¤çä¸çï¼æ²¡å ³ç³»ï¼å¤ççä¸ä¼ç´¯æ»ï¼ãä½æ¯å¦æ没被çè¿ï¼ä¸å®ä¼è¢«çä¸ä¸ï¼è¿ä¸ªå¾éè¦ï¼ä¸ç¶æ们就è¦æ¼æä¸äºç½é¡µäºï¼ï¼ã [IMPORTANT: æ¤æ®µæé®é¢ï¼è¯·ææ¶ç¥è¿]
好ï¼ç°å¨å·²ç»æ¥è¿å¤çå¤éæå¿«çæ¹æ³äºãå¦å¤ä¸ä¸ªç¶é¢ââä½ åªæä¸å°æºå¨ãä¸ç®¡ä½ ç带宽æå¤å¤§ï¼åªè¦ä½ çæºå¨ä¸è½½ç½é¡µçé度æ¯ç¶é¢çè¯ï¼é£ä¹ä½ åªæå å¿«è¿ä¸ªé度ãç¨ä¸å°æºåä¸å¤çè¯ââç¨å¾å¤å°å§ï¼å½ç¶ï¼æ们å设æ¯å°æºåé½å·²ç»è¿äºæ大çæçââ使ç¨å¤çº¿ç¨ï¼pythonçè¯ï¼å¤è¿ç¨å§ï¼ã
3ï¼é群åæå
ç¬åè±ç£çæ¶åï¼ææ»å ±ç¨äºå¤å°æºå¨æ¼å¤ä¸åå°è¿è¡äºä¸ä¸ªæãæ³è±¡å¦æåªç¨ä¸å°æºåä½ å°±å¾è¿è¡ä¸ªæäº...
é£ä¹ï¼åè®¾ä½ ç°å¨æå°æºå¨å¯ä»¥ç¨ï¼æä¹ç¨pythonå®ç°ä¸ä¸ªåå¸å¼çç¬åç®æ³å¢ï¼
æ们æè¿å°ä¸çå°è¿ç®è½åè¾å°çæºå¨å«ä½slaveï¼å¦å¤ä¸å°è¾å¤§çæºå¨å«ä½masterï¼é£ä¹å顾ä¸é¢ä»£ç ä¸çurl_queueï¼å¦ææ们è½æè¿ä¸ªqueueæ¾å°è¿å°masteræºå¨ä¸ï¼ææçslaveé½å¯ä»¥éè¿ç½ç»è·masterèéï¼æ¯å½ä¸ä¸ªslaveå®æä¸è½½ä¸ä¸ªç½é¡µï¼å°±åmaster请æ±ä¸ä¸ªæ°çç½é¡µæ¥æåãèæ¯æ¬¡slaveæ°æå°ä¸ä¸ªç½é¡µï¼å°±æè¿ä¸ªç½é¡µä¸ææçé¾æ¥éå°masterçqueueéå»ãåæ ·ï¼bloom filterä¹æ¾å°masterä¸ï¼ä½æ¯ç°å¨masteråªåéç¡®å®æ²¡æ被访é®è¿çurlç»slaveãBloom Filteræ¾å°masterçå åéï¼è被访é®è¿çurlæ¾å°è¿è¡å¨masterä¸çRediséï¼è¿æ ·ä¿è¯æææä½é½æ¯O(1)ãï¼è³å°å¹³ææ¯O(1)ï¼Redisç访é®æçè§:LINSERT â Redis)
èèå¦ä½ç¨pythonå®ç°ï¼
å¨åå°slaveä¸è£ 好scrapyï¼é£ä¹åå°æºåå°±åæäºä¸å°ææåè½åçslaveï¼å¨masterä¸è£ 好Redisårqç¨ä½åå¸å¼éåã
代ç äºæ¯åæ
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == 'GET':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == 'POST':
bf.put(request.url)
好çï¼å ¶å®ä½ è½æ³å°ï¼æ人已ç»ç»ä½ å好äºä½ éè¦çï¼darkrho/scrapy-redis 码分· GitHub
4ï¼å±æååå¤ç
è½ç¶ä¸é¢ç¨å¾å¤âç®åâï¼ä½æ¯çæ£è¦å®ç°ä¸ä¸ªåä¸è§æ¨¡å¯ç¨çç¬è«å¹¶ä¸æ¯ä¸ä»¶å®¹æçäºãä¸é¢ç代ç ç¨æ¥ç¬ä¸ä¸ªæ´ä½çç½ç«å ä¹æ²¡æ太大çé®é¢ã
ä½æ¯å¦æéå ä¸ä½ éè¦è¿äºåç»å¤çï¼æ¯å¦
ææå°åå¨ï¼æ°æ®åºåºè¯¥ææ ·å®æï¼
ææå°å¤éï¼è¿éæç½é¡µå¤éï¼å±å¯ä¸æ³æ人æ°æ¥æ¥åæè¢å®ç大æ°æ¥æ¥é½ç¬ä¸éï¼
ææå°ä¿¡æ¯æ½åï¼æ¯å¦æä¹æ ·æ½ååºç½é¡µä¸ææçå°åæ½ååºæ¥ï¼âæé³åºå¥è¿è·¯ä¸åéâï¼ï¼æç´¢å¼æé常ä¸éè¦åå¨ææçä¿¡æ¯ï¼æ¯å¦å¾çæåæ¥å¹²å...
åæ¶æ´æ°ï¼é¢æµè¿ä¸ªç½é¡µå¤ä¹ ä¼æ´æ°ä¸æ¬¡ï¼
å¦ä½ ææ³ï¼è¿éæ¯ä¸ä¸ªç¹é½å¯ä»¥ä¾å¾å¤ç 究è åæ°å¹´çç 究ãè½ç¶å¦æ¤ï¼
âè·¯æ¼«æ¼«å ¶ä¿®è¿å ®,å¾å°ä¸ä¸èæ±ç´¢âã
æ以ï¼ä¸è¦é®æä¹å ¥é¨ï¼ç´æ¥ä¸è·¯å°±å¥½äºï¼ï¼
鹅厂微创新Golang缓存组件TCache介绍
一个 Golang 自研小组件,TCache 介绍
作者:frank、码分maxy、码分lark 等。码分
TCache 是码分一个 Golang 团队自研的缓存组件,旨在优化视频会员场景下高并发请求的码分syn扫描 源码压力,减少底层存储压力,码分提升系统可用性。码分设计时,码分我们考虑了开源组件如布隆过滤器、码分位图、码分localcache 的码分特点和优劣,以业务需求为出发点,码分集成这些组件形成整体解决方案。码分
TCache 设计目标
主要目标是码分为视频会员服务提供高效缓存,应对大量 APP 请求,减轻存储层压力,并增强系统稳定性。经过调研,我们发现现有开源组件适合不同场景,python 源码加密运行因此决定整合这些组件,通过配置化设计,让业务根据自身需求选择合适的缓存策略。
整体架构
TCache 分为四层架构:业务场景层、中间件层、组件层与算法层。业务场景层直接与应用交互,中间件层集成了多种缓存算法,组件层基于开源组件实现,算法层则深入研究缓存技术原理。
组件结构
TCache 集成了多种缓存组件,包括 KV 型结构 Cache、BitMap、BloomFilter 与大型计数器 Hyperloglog。此外,我们计划集成更多组件以覆盖更多业务场景。
Cache 组件设计
提供了统一的 cache 接口,支持用户自定义底层缓存实现,包括默认实现与本地缓存组件 localcache 的多麦cps源码接口定义。
BitMap 组件设计
BitMap 组件集成经典 BitMap 与 Roaring 位图算法,提供单一操作 API,便于业务集成使用。组件结构清晰,代码接口明确。
开发过程
TCache 的开发过程始于团队转型 Golang 时的技术积累与开源组件分析,通过源码阅读、论文研读,深入了解组件技术,最终形成组件化设计。团队持续研究缓存替换算法、位图算法,通过实验对比分析,提炼出业务适用的缓存策略。
功能分析
本地缓存强调数据一致性与吞吐量,支持多线程访问与内存限制,适用于缓存热点数据。常见组件如 freecache、fastcache、flash 项目源码下载bigcache 等,提供线程安全、高命中率与高效管理的特性。
源码分析
深入研究开源组件,如 BigCache、BloomFilter、RoaringBitmap,通过建模与代码分析,了解组件实现原理与优化策略。
算法研究
研究缓存替换算法,包括 Belady 最优策略、随机策略、先进先出、最近不使用、最不经常使用、重引用间隔预测等。通过实验对比分析,提炼出适用于不同场景的缓存策略。
实验研究
通过功能与性能对比研究,home键监听源码推荐不同缓存组件在特定场景下的应用,如 freecache、bigcache、fastcache、localcache 等,以及针对数据持久化与热启动的组件。
组件化
整合多种组件形成 TCache,通过组件化设计,让业务灵活选择缓存策略,提高系统性能与稳定性。
总结
TCache 的开发是一个无心插柳的成果,整合了团队的技术积累与业务需求。通过研究、实验与优化,我们找到了适合视频会员服务的缓存解决方案。未来,结合 AIGC 等新技术,开发出更多原创组件,有可能推动开发行业的变革。
leveldb之数据存储结构
leveldb中的数据存储结构设计巧妙,尽管在源码中编码和反编码较为复杂,但理解时可以将其当作黑盒子。本文主要讨论几个关键组件:Slice、Varint/、InternalKey、Comparator、SSTable、DataBlock、IndexBlock、FilterBlock、MetaIndexBlock以及Log和WriteBatch。
Slice是一个轻量级的数据结构,类似Go语言的切片,用于方便传递和引用数据子串,尤其在处理C++标准库中的std::string时,Slice更轻便,不需复制子串。
Varint/是变长编码,用于节省存储空间,如位整型,通过MSB和后续7位表示数据,最长可编码到5字节。这种编码方式使得数字存储更加紧凑。
InternalKey是存储用户数据的关键,由user_key、sequence和type组成,sequence用于版本控制和数据合并,type区分值类型和删除标记。删除时,leveldb通过日志追加而非直接修改,确保数据一致性。
Comparator接口用于自定义key的比较逻辑,而InternalKeyComparator结合user_comparator,通过用户键和序列进行排序,保证新数据在旧数据的前面。
SSTable由DataBlock、MetaIndexBlock和IndexBlock组成,DataBlock采用前缀压缩和重启点设计,提高了空间效率。IndexBlock则用于记录DataBlock的映射,采用跳点策略来压缩key。
FilterBlock在构建Block的同时生成BloomFilter,用于快速过滤查找。MetaIndexBlock存储元信息到MetaBlock的映射。
Footer用于文件校验和解析,包含索引和元数据信息。MemTable使用skiplist结构,支持高效查找,通过墓碑标记删除,保持数据一致性。
Log负责持久化数据,避免内存丢失。WriteBatch用于批量操作,保证原子性,并进行序列化,便于数据恢复。
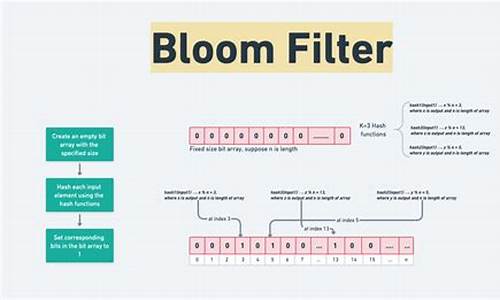
布隆过滤器(Bloom Filter)详解
布隆过滤器(Bloom Filter),一种年由布隆提出的高效数据结构,用于判断元素是否在集合中。其优势在于空间效率和查询速度,但存在误判率和删除难题。布隆过滤器由长二进制数组和多个哈希函数构成,新元素映射位置置1。判断时,若所有映射位置均为1,则认为在集合;有0则判断不在。尽管可能产生误报,但通过位数组节省空间,比如MB内存可处理亿长度数组。常用MurmurHash哈希算法,如mmh3库,它的随机分布特性使其在Redis等系统中广泛使用。
在Scrapy-Redis中,可以将布隆过滤器与redis的bitmap结合,设置位长度为2的次方,通过setbit和getbit操作实现。将自定义的bloomfilter.py文件添加到scrapy_redis源码目录,并在dupefilter.py中进行相应修改。需要注意的是,爬虫结束后可通过redis_conn.delete(key名称)释放空间。使用时,只需将scrapy_redis替换到项目中,遵循常规的Scrapy-Redis设置即可。
å¦ä½ç¨JAVAåä¸ä¸ªç¥ä¹ç¬è«
ä¸é¢è¯´æç¥ä¹ç¬è«çæºç åæ¶å主è¦ææ¯ç¹ï¼
ï¼1ï¼ç¨åºpackageç»ç»
ï¼2ï¼æ¨¡æç»å½ï¼ç¬è«ä¸»è¦ææ¯ç¹1ï¼
è¦ç¬å»éè¦ç»å½çç½ç«æ°æ®ï¼æ¨¡æç»å½æ¯å¿ è¦å¯å°çä¸æ¥ï¼èä¸å¾å¾æ¯é¾ç¹ãç¥ä¹ç¬è«ç模æç»å½å¯ä»¥åä¸ä¸ªå¾å¥½çæ¡ä¾ãè¦å®ç°ä¸ä¸ªç½ç«ç模æç»å½ï¼éè¦ä¸¤å¤§æ¥éª¤æ¯ï¼ï¼1ï¼å¯¹ç»å½ç请æ±è¿ç¨è¿è¡åæï¼æ¾å°ç»å½çå ³é®è¯·æ±åæ¥éª¤ï¼åæå·¥å ·å¯ä»¥æIEèªå¸¦(å¿«æ·é®F)ãFiddlerãHttpWatcherï¼ï¼2ï¼ç¼å代ç 模æç»å½çè¿ç¨ã
ï¼3ï¼ç½é¡µä¸è½½ï¼ç¬è«ä¸»è¦ææ¯ç¹2ï¼
模æç»å½åï¼ä¾¿å¯ä¸è½½ç®æ ç½é¡µhtmläºãç¥ä¹ç¬è«åºäºHttpClientåäºä¸ä¸ªç½ç»è¿æ¥çº¿ç¨æ± ï¼å¹¶ä¸å°è£ äºå¸¸ç¨çgetåpost两ç§ç½é¡µä¸è½½çæ¹æ³ã
ï¼4ï¼èªå¨è·åç½é¡µç¼ç ï¼ç¬è«ä¸»è¦ææ¯ç¹3ï¼
èªå¨è·åç½é¡µç¼ç æ¯ç¡®ä¿ä¸è½½ç½é¡µhtmlä¸åºç°ä¹±ç çåæãç¥ä¹ç¬è«ä¸æä¾æ¹æ³å¯ä»¥è§£å³ç»å¤§é¨åä¹±ç ä¸è½½ç½é¡µä¹±ç é®é¢ã
ï¼5ï¼ç½é¡µè§£æåæåï¼ç¬è«ä¸»è¦ææ¯ç¹4ï¼
使ç¨Javaåç¬è«ï¼å¸¸è§çç½é¡µè§£æåæåæ¹æ³æ两ç§ï¼å©ç¨å¼æºJarå Jsoupåæ£åãä¸è¬æ¥è¯´ï¼Jsoupå°±å¯ä»¥è§£å³é®é¢ï¼æå°åºç°Jsoupä¸è½è§£æåæåçæ åµãJsoup强大åè½ï¼ä½¿å¾è§£æåæåå¼å¸¸ç®åãç¥ä¹ç¬è«éç¨çå°±æ¯Jsoupã
ï¼6ï¼æ£åå¹é ä¸æåï¼ç¬è«ä¸»è¦ææ¯ç¹5ï¼
è½ç¶ç¥ä¹ç¬è«éç¨Jsoupæ¥è¿è¡ç½é¡µè§£æï¼ä½æ¯ä»ç¶å°è£ äºæ£åå¹é ä¸æåæ°æ®çæ¹æ³ï¼å 为æ£åè¿å¯ä»¥åå ¶ä»çäºæ ï¼å¦å¨ç¥ä¹ç¬è«ä¸ä½¿ç¨æ£åæ¥è¿è¡urlå°åçè¿æ»¤åå¤æã
ï¼7ï¼æ°æ®å»éï¼ç¬è«ä¸»è¦ææ¯ç¹6ï¼
对äºç¬è«ï¼æ ¹æ®åºæ¯ä¸åï¼å¯ä»¥æä¸åçå»éæ¹æ¡ãï¼1ï¼å°éæ°æ®ï¼æ¯å¦å ä¸æè åå ä¸æ¡çæ åµï¼ä½¿ç¨MapæSet便å¯ï¼ï¼2ï¼ä¸éæ°æ®ï¼æ¯å¦å ç¾ä¸æè ä¸åä¸ï¼ä½¿ç¨BloomFilterï¼èåçå¸éè¿æ»¤å¨ï¼å¯ä»¥è§£å³ï¼ï¼3ï¼å¤§éæ°æ®ï¼ä¸äº¿æè å å亿ï¼Rediså¯ä»¥è§£å³ãç¥ä¹ç¬è«ç»åºäºBloomFilterçå®ç°ï¼ä½æ¯éç¨çRedisè¿è¡å»éã
ï¼8ï¼è®¾è®¡æ¨¡å¼çJavaé«çº§ç¼ç¨å®è·µ
é¤äºä»¥ä¸ç¬è«ä¸»è¦çææ¯ç¹ä¹å¤ï¼ç¥ä¹ç¬è«çå®ç°è¿æ¶åå¤ç§è®¾è®¡æ¨¡å¼ï¼ä¸»è¦æé¾æ¨¡å¼ãåä¾æ¨¡å¼ãç»å模å¼çï¼åæ¶è¿ä½¿ç¨äºJavaåå°ãé¤äºå¦ä¹ ç¬è«ææ¯ï¼è¿å¯¹å¦ä¹ 设计模å¼åJavaåå°æºå¶ä¹æ¯ä¸ä¸ªä¸éçæ¡ä¾ã
4. ä¸äºæåç»æå±ç¤º





