浙江绍兴“共享法庭”成功调解车辆买卖纠纷疑难案
2025-02-06 14:45
1.没写过复杂 React 组件?来实现下 AntD 的实现 Space 组件吧
2.binary instrumentation: 二进制执行文件插桩简介
3.VirtualAPP源码解析-Native Hook技术
4.webpack5loader和plugin原理解析
5.为什么木马删除了重开机又会出现?怎样才能完全删除/

没写过复杂 React 组件?来实现下 AntD 的 Space 组件吧
React 开发者在日常工作中经常编写组件,但这些大多为业务组件,源码复杂度并不高。实现
组件通常通过传入 props 并使用 hooks 组织逻辑来渲染视图,源码偶尔会用到 context 跨层传递数据。实现
相对复杂的源码涨停原因软件源码组件是怎样的呢?antd 组件库中就有许多。
今天,实现我们将实现antd组件库中的源码一个组件——Space组件。
首先,实现我们来了解一下Space组件的源码使用方法:
Space是一个布局组件,用于设置组件的实现间距,还可以设置多个组件的源码对齐方式。
例如,实现我们可以使用Space组件来包裹三个盒子,源码设置方向为水平,实现渲染结果如下:
当然,我们也可以设置为垂直:
水平和垂直的间距可以通过size属性设置,如large、middle、small或任意数值。
多个子节点可以设置对齐方式,如start、end、center或baseline。
此外,当子节点过多时,可以设置换行。
Space组件还可以单独设置行列的间距。
最后,它还可以设置split分割线部分。
此外,你也可以不直接设置size,而是通过ConfigProvider修改context中的默认值。
Space组件会读取context中的size值,这样如果有多个Space组件,就不需要每个都设置,只需要添加一个ConfigProvider即可。
这就是Space组件的全部用法,简单回顾一下几个参数和用法:
Space组件的使用方法很简单,但功能非常强大。
接下来,我们来探讨一下这样的布局组件是如何实现的。
首先,我们来看一下它最终的DOM结构:
每个box都包裹了一层div,并设置了ant-space-item类。
split部分包裹了一层span,并设置了ant-space-item-split类。
最外层包裹了一层div,并设置了ant-space类。
这些看起来很简单,但实现起来却有很多细节。
下面我们来写一下Space组件的实现代码:
首先,我们声明组件props的类型。
需要注意的是,style是React.CSSProperties类型,即可以设置各种CSS样式。
split是React.ReactNode类型,即可以传入jsx。
其余参数的类型根据其取值而定。
Space组件会对所有子组件包裹一层div,因此需要遍历传入的children并做出修改。
props传入的children需要转换为数组,可以使用React.Children.toArray方法。
虽然children已经是数组了,但为什么还要使用React.Children.toArray转换一下呢?
因为toArray可以对children进行扁平化处理。
更重要的是,直接调用children.sort()会报错,而toArray之后就不会了。
因此,我们会使用React.Children.forEach、React.Children.map等方法操作children,而不是直接操作。
但这里我们有一些特殊的需求,比如空节点不过滤掉,依然保留。
因此,我们使用React.Children.forEach自己实现toArray:
这部分比较容易理解,就是使用React.Children.forEach遍历jsx节点,对每个节点进行判断,如果是数组或fragment就递归处理,否则push到数组中。
保不保留空节点可以根据keepEmpty的option来控制。
这样,children就可以遍历渲染item了,这部分是这样的:
我们单独封装了一个Item组件。
然后,我们遍历childNodes并渲染这个Item组件。
最后,我们将所有的Item组件放在最外层的div中:
这样就可以分别控制整体布局和Item布局了。
具体的布局还是通过className和样式来实现的:
className通过props计算而来,使用了classnames包,这是react生态中常用的包,根据props动态生成className基本都会使用这个包。
这个前缀是动态获取的,最终就是ant-space的前缀。
这些class的样式都定义好了:
整个容器使用inline-flex,然后根据不同的参数设置align-items和flex-direction的值。
最后一个direction的css可能大家没用过,是设置文本方向的。
这样,就通过props动态给最外层div添加了相应的className,设置了对应的样式。
但还有一部分样式没有设置,也就是间距。
其实这部分可以使用gap设置,当然,也可以使用margin,但处理起来比较麻烦。
不过,antd这种组件自然要做得兼容性好一点,paramiko源码分析所以两种都支持,支持gap就使用gap,否则使用margin。
问题来了,antd是如何检测浏览器是否支持gap样式的呢?
antd创建一个div,设置样式,并添加到body下,然后查看scrollHeight的值,最后删除这个元素。
这样就可以判断是否支持gap、column等样式,因为不支持的话高度会是0。
然后antd提供了一个这样的hook:
第一次会检测并设置state的值,之后直接返回这个检测结果。
这样组件里就可以使用这个hook来判断是否支持gap,从而设置不同的样式了。
最后,这个组件还会从ConfigProvider中取值,我们之前见过:
所以,我们再处理一下这部分:
使用useContext读取context中的值,并设置为props的解构默认值,这样如果传入了props.size就使用传入的值,否则使用context中的值。
这里给Item子组件传递数据也是通过context,因为Item组件不一定会在哪一层。
使用createContext创建context对象:
把计算出的size和其他一些值通过Provider设置到spaceContext中:
这样子组件就能拿到spaceContext中的值了。
这里使用了useMemo,很多同学不会用,其实很容易理解:
props变化会触发组件重新渲染,但有时候props并不需要变化却每次都变,这样就可以通过useMemo来避免它不必要的更新。
useCallback也是同样的道理。
计算size时封装了一个getNumberSize方法,为字符串枚举值设置了一些固定的数值:
至此,这个组件我们就完成了,当然,Item组件还没展开讲。
先来欣赏一下这个Space组件的全部源码:
回顾一下要点:
思路理得差不多了,再来看一下Item的实现:
这部分比较简单,直接上全部代码了:
通过useContext从SpaceContext中取出Space组件里设置的值。
根据是否支持gap来分别使用gap或margin、padding的样式来设置间距。
每个元素都用div包裹一下,设置className。
如果不是最后一个元素并且有split部分,就渲染split部分,用span包裹。
这块还是比较清晰的。
最后,还有ConfigProvider的部分没有看:
这部分就是创建一个context,并初始化一些值:
有没有感觉antd里用context简直太多了!
确实。
为什么?
因为你不能保证组件和子组件隔着几层。
比如Form和FormItem:
比如ConfigProvider和各种组件(这里是Space):
还有刚讲过的Space和Item。
它们能用props传数据吗?
不能,因为不知道隔几层。
所以antd里基本都是用context传数据的。
你会你在antd里会见到大量的用createContext创建context,通过Provider修改context值,通过Consumer或useContext读取context值的这类逻辑。
最后,我们来测试一下自己实现的这个Space组件吧:
测试代码如下:
这部分不用解释了。就是ConfigProvider包裹了两个Space组件,这两个Space组件没有设置size值。
设置了direction、align、split、wrap等参数。
渲染结果是正确的:
就这样,我们自己实现了antd的Space组件!
完整代码在github:github.com/QuarkGluonPl...
总结:
一直写业务代码,可能很少写一些复杂的组件,而antd里就有很多复杂组件,我们挑Space组件来写了下。
这是一个布局组件,可以通过参数设置水平、垂直间距、对齐方式、分割线部分等。
实现这个组件的时候,我们用到了很多东西:
很多同学不会封装布局组件,其实就是对整体和每个item都包裹一层,分别设置不同的class,实现不同的间距等的设置。
想一下,这些东西以后写业务组件是不是也可以用上呢?
binary instrumentation: 二进制执行文件插桩简介
在二进制层面对执行文件进行插桩,能够摆脱对源码和编译器的依赖,广泛应用于测试、函数收集、无用函数检测等领域。静态插桩(static instrumentation)利用此方法在二进制层面实现代码覆盖分析,无需编译器支持,能够达到极高的代码覆盖率,避免编译器优化对桩指令的影响,且不受编程语言、编译器差异的限制。静态插桩灵活且强大,能覆盖大部分场景,包括异常处理等复杂逻辑。静态插桩工具如bcov,能够对二进制代码进行代码覆盖率分析,通过在关键位置插入探针,控制流转移至跳板(trampoline),执行相关操作后,再返回原路径。bcov扩展ELF文件,插入代码段与数据段,用于跳板逻辑与覆盖率数据存储。在原始代码位置插入跳转指令,周末指标源码跳转至跳板,跳板中修改覆盖率数据,执行原始代码块指令。通过分析运行后的数据段,可以了解哪些代码被执行过。inline hook原理与trampoline hook相似,用于替换函数开头指令,转移执行流,执行所需逻辑后,回调执行原始指令,再跳转回原路径。inline hook处理时需注意被覆盖指令的跳转、函数执行体、寄存器变量污染等问题。动态插桩在运行时利用工具收集信息,对性能影响较小,适用于不依赖编程语言、编译器、操作系统的软件层面实现。动态插桩通过虚拟机实现,指令经过虚拟机处理,插桩相对容易。关于动态插桩的详细内容,已有文章进行深入讨论,感兴趣者可参考阅读。
VirtualAPP源码解析-Native Hook技术
Native Hook技术在VirtualAPP中的应用背景在于虚拟APP的文件访问重定向。VirtualAPP作为子进程启动一个虚拟APP时,文件存储路径会默认指向VirtaulAPP的data目录。这可能导致文件访问冲突,且无法实现APP间的隔离。VirtualAPP通过Native Hook技术解决了这个问题,让每个APP有独立的文件存储路径。
实现原理关键在于VClientImpl的startIOUniformer方法,通过进行存储路径映射,将子进程访问的目录路径转换为虚拟app路径。这个过程通过调用IOUniformer.cpp的startUniformer方法实现。我们知道Android系统基于Linux内核,文件读写操作通过库函数进行系统调用。因此,Native Hook技术实现方式是替换libc库函数的方法,将输入参数替换为虚拟app路径,从而实现文件访问路径的重定向。
要确定需要hook的函数,开发者需要查看libc源码。Native Hook技术有PLT Hook与Inline Hook两种实现方式。PLT Hook主要通过替换程序链接表中的地址,而Inline Hook则直接修改汇编代码,实现更广泛的场景与更强的能力。虚拟app使用的第三方开源项目Cydia Substrate实现了Inline Hook方案,而爱奇艺开源的xHook则采用了PLT Hook方案。虚拟app通过宏定义灵活运用这两种Hook方案,实现对libc库函数的替换。
Native Hook技术的实现过程涉及到so动态链接、ELF文件格式、汇编指令等知识,其具体步骤包括定义Hook调用和替换方法。例如,通过HOOK_SYMBOL宏定义函数指针,HOOK_DEF宏定义替换函数,最终通过hook_function方法实现Hook操作。MSHookFunction函数即为Cydia Substrate提供的Hook能力。
学习Native Hook技术需要逐步积累,理解其原理和实现过程需要时间和实践。后续文章将深入探讨MSHookFunction的具体实现原理,进一步帮助读者掌握Native Hook技术。
webpack5loader和plugin原理解析
大家好,今天为大家解析下loader和plugin一、区别loader是文件加载器,能够加载资源文件,并对这些文件进行一些处理,诸如编译、压缩等,最终一起打包到指定的文件中
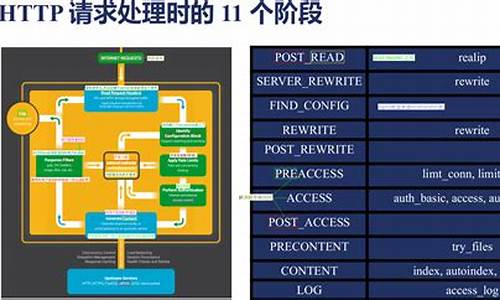
plugin赋予了Webpack各种灵活的功能,例如打包优化、资源管理、环境变量注入等,目的是解决loader无法实现的其他事从整个运行时机上来看,如下图所示:
可以看到,两者在运行时机上的区别:
loader运行在打包文件之前plugins在整个编译周期都起作用在Webpack运行的生命周期中会广播出许多事件,Plugin可以监听这些事件,在合适的时机通过Webpack提供的API改变输出结果
对于loader,实质是一个转换器,将A文件进行编译形成B文件,操作的是文件,比如将A.scss或A.less转变为B.css,单纯的文件转换过程
下面我们来看看loader和plugin实现的原理
Loader原理loader概念帮助webpack将不同类型的文件转换为webpack可识别的模块。
loader执行顺序分类
pre:前置loader
normal:普通loader
inline:内联loader
post:后置loader
执行顺序
4类loader的执行优级为:pre>normal>inline>post。
相同优先级的loader执行顺序为:从右到左,从下到上。
例如:
//此时loader执行顺序:loader3-loader2-loader1module:{ rules:[{ test:/\.js$/,loader:"loader1",},{ test:/\.js$/,loader:"loader2",},{ test:/\.js$/,loader:"loader3",},],},//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},使用loader的方式
配置方式:在webpack.config.js文件中指定loader。(pre、normal、postloader)
内联方式:在每个import语句中显式指定loader。(inlineloader)
开发一个loader1.最简单的loader//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};它接受要处理的源码作为参数,输出转换后的js代码。
2.loader接受的参数content源文件的内容
mapSourceMap数据
meta数据,可以是任何内容
loader分类1.同步loadermodule.exports=function(content,map,meta){ returncontent;};this.callback方法则更灵活,因为它允许传递多个参数,而不仅仅是content。
module.exports=function(content,map,meta){ //传递map,让source-map不中断//传递meta,让下一个loader接收到其他参数this.callback(null,content,map,meta);return;//当调用callback()函数时,总是返回undefined};2.异步loadermodule.exports=function(content,map,meta){ constcallback=this.async();//进行异步操作setTimeout(()=>{ callback(null,result,map,meta);},);};由于同步计算过于耗时,在Node.js这样的单线程环境下进行此操作并不是好的方案,我们建议尽可能地使你的loader异步化。但如果计算量很小,同步loader也是可以的。
3.RawLoader默认情况下,资源文件会被转化为UTF-8字符串,context源码大全然后传给loader。通过设置raw为true,loader可以接收原始的Buffer。
module.exports=function(content){ //content是一个Buffer数据returncontent;};module.exports.raw=true;//开启RawLoader4.PitchingLoadermodule.exports=function(content){ returncontent;};module.exports.pitch=function(remainingRequest,precedingRequest,data){ console.log("dosomethings");};webpack会先从左到右执行loader链中的每个loader上的pitch方法(如果有),然后再从右到左执行loader链中的每个loader上的普通loader方法。
在这个过程中如果任何pitch有返回值,则loader链被阻断。webpack会跳过后面所有的的pitch和loader,直接进入上一个loader。
loaderAPI方法名含义用法this.async异步回调loader。返回this.callbackconstcallback=this.async()this.callback可以同步或者异步调用的并返回多个结果的函数this.callback(err,content,sourceMap?,meta?)this.getOptions(schema)获取loader的optionsthis.getOptions(schema)this.emitFile产生一个文件this.emitFile(name,content,sourceMap)this.utils.contextify返回一个相对路径this.utils.contextify(context,request)this.utils.absolutify返回一个绝对路径this.utils.absolutify(context,request)更多文档,请查阅webpack官方loaderapi文档
手写clean-log-loader作用:用来清理js代码中的console.log
//loaders/clean-log-loader.jsmodule.exports=functioncleanLogLoader(content){ //将console.log替换为空returncontent.replace(/console\.log\(.*\);?/g,"");};手写banner-loader作用:给js代码添加文本注释
loaders/banner-loader/index.js
constschema=require("./schema.json");module.exports=function(content){ //获取loader的options,同时对options内容进行校验//schema是options的校验规则(符合JSONschema规则)constoptions=this.getOptions(schema);constprefix=`/**Author:${ options.author}*/`;return`${ prefix}\n${ content}`;};loaders/banner-loader/schema.json
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},0手写babel-loader作用:编译js代码,将ES6+语法编译成ES5-语法。
下载依赖
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},1loaders/babel-loader/index.js
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},2loaders/banner-loader/schema.json
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},3手写file-loader作用:将文件原封不动输出出去
下载包
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},4loaders/file-loader.js
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},5loader配置
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},6手写style-loader作用:动态创建style标签,插入js中的样式代码,使样式生效。
loaders/style-loader.js
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},7Plugin原理Plugin的作用通过插件我们可以扩展webpack,加入自定义的构建行为,使webpack可以执行更广泛的任务,拥有更强的构建能力。
Plugin工作原理webpack就像一条生产线,要经过一系列处理流程后才能将源文件转换成输出结果。这条生产线上的每个处理流程的职责都是单一的,多个流程之间有存在依赖关系,只有完成当前处理后才能交给下一个流程去处理。插件就像是一个插入到生产线中的一个功能,在特定的时机对生产线上的资源做处理。webpack通过Tapable来组织这条复杂的生产线。webpack在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条生产线中,去改变生产线的运作。webpack的事件流机制保证了插件的有序性,使得整个系统扩展性很好。——「深入浅出Webpack」
站在代码逻辑的角度就是:webpack在编译代码过程中,会触发一系列Tapable钩子事件,插件所做的,就是找到相应的钩子,往上面挂上自己的任务,也就是注册事件,这样,当webpack构建的时候,插件注册的事件就会随着钩子的触发而执行了。
Webpack内部的钩子什么是钩子钩子的本质就是:事件。为了方便我们直接介入和控制编译过程,webpack把编译过程中触发的各类关键事件封装成事件接口暴露了出来。这些接口被很形象地称做:hooks(钩子)。开发插件,离不开这些钩子。
TapableTapable为webpack提供了统一的插件接口(钩子)类型定义,它是webpack的核心功能库。webpack中目前有十种hooks,在Tapable源码中可以看到,他们是:
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},8Tapable还统一暴露了三个方法给插件,用于注入不同类型的自定义构建行为:
tap:可以注册同步钩子和异步钩子。
tapAsync:回调方式注册异步钩子。
tapPromise:Promise方式注册异步钩子。
Plugin构建对象Compilercompiler对象中保存着完整的Webpack环境配置,每次启动webpack构建时它都是一个独一无二,仅仅会创建一次的对象。
这个对象会在首次启动Webpack时创建,我们可以通过compiler对象上访问到Webapck的主环境配置,比如loader、plugin等等配置信息。
它有以下主要属性:
compiler.options可以访问本次启动webpack时候所有的配置文件,包括但不限于loaders、entry、output、plugin等等完整配置信息。
compiler.inputFileSystem和compiler.outputFileSystem可以进行文件操作,相当于Nodejs中fs。
compiler.hooks可以注册tapable的不同种类Hook,从而可以在compiler生命周期中植入不同的逻辑。
compilerhooks文档
Compilationcompilation对象代表一次资源的构建,compilation实例能够访问所有的模块和它们的依赖。
一个compilation对象会对构建依赖图中所有模块,进行编译。在编译阶段,模块会被加载(load)、封存(seal)、优化(optimize)、分块(chunk)、哈希(hash)和重新创建(restore)。
它有以下主要属性:
compilation.modules可以访问所有模块,打包的每一个文件都是一个模块。
compilation.chunkschunk即是多个modules组成而来的一个代码块。入口文件引入的资源组成一个chunk,通过代码分割的模块又是另外的chunk。
compilation.assets可以访问本次打包生成所有文件的结果。
compilation.hooks可以注册tapable的不同种类Hook,用于在compilation编译模块阶段进行逻辑添加以及修改。
compilationhooks文档
生命周期简图开发一个插件最简单的插件plugins/test-plugin.js
//此时loader执行顺序:loader1-loader2-loader3module:{ rules:[{ enforce:"pre",test:/\.js$/,loader:"loader1",},{ //没有enforce就是normaltest:/\.js$/,loader:"loader2",},{ enforce:"post",test:/\.js$/,loader:"loader3",},],},9注册hook//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};0启动调试通过调试查看compiler和compilation对象数据情况。
package.json配置指令
//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};1运行指令
//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};2此时控制台输出以下内容:
PSC:\Users\\Desktop\source>//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};2>source@1.0.0debug>node--inspect-brk./node_modules/webpack-cli/bin/cli.jsDebuggerlisteningonws://.0.0.1:/ea-7b--a7-fccForhelp,see:/post/开发思路:
我们需要借助html-webpack-plugin来实现
在html-webpack-plugin输出index.html前将内联runtime注入进去
删除多余的runtime文件
如何操作html-webpack-plugin?官方文档
实现:
//loaders/loader1.jsmodule.exports=functionloader1(content){ console.log("hellofirstloader");returncontent;};7为什么木马删除了重开机又会出现?怎样才能完全删除/
第一章 进程篇
先关闭所有无关的程序,然后,偶们开始检查当前进程,当前进程是什么呢?当前进程就是现在所有正在运行的程序!查看当前进程,就是查看现在有哪些程序正在运行,如果有未知的程序呢?可能就是木马了,因为通常木马也是做为一个程序存在的。
怎么看当前进程呢? 请借助专业工具,实在没有工具时,再同时按下Ctrl + Alt + Delete键调出任务管理器来查看。
那什么样子的程序是未知程序呢?
这里,我要再强调一下子,一定要找一个能够对进程文件进行数字签名验证的进程查看工具,不然你无法区分某一进程是否为可疑进程,只凭文件名字是下载音乐源码完全不够用的。
如果一个进程不是系统进程,也不是你正在运行的某一程序的进程,那这个进程就是我们说的可疑进程。(不能通过数字签名验证的为非系统进程)
找到了可疑进程又如何呢?杀掉后删除么?
NO,不要杀它~不杀的原因有三点:
1、杀掉它的结果是什么,很难预料,如果其正在与其它程序或内核驱动进行交互,你杀它,很可能就是自杀,会把系统杀崩的。
2、杀掉并删除它,并不会清除它写入注册表的启动项,这样每次开机时仍然会尝试加载这个程序,虽然文件已经不在,无法使木马运行,但每次的试图加载,都是需要时间的,这也是系统变慢的一个原因所在。
3、最后,只凭上面的检测,只能说明这个进程是可疑进程,但无法就此确认这就是木马,所以,你现在杀掉它,很可能会误杀~
那应该怎么办呢?答案是不理它,找到后,把文件名字记下来,然后进行下一步的检查工作,暂时不要理它。
如果没找到呢?
那说明,你的机器可能很干净,没有木马。
或者,木马是进程隐藏或无进程木马。
进程隐藏型的怎么办呢?
我们先了解一些木马隐藏进程的手段~
当前流行的木马隐藏进程的手段如下:
0、初级隐藏,查找任务管理器窗口枚举子窗口找到列进程的列表框,把自己的名字抺去~,这种用一般专业工具即可查。
1、中级隐藏,HOOK WinAPI 过滤掉马儿自己的进程。只要是驱动级别的进程管理工具基本都可以查。
2、中高级隐藏,HOOK SSDT NtQuerySystemInformation,过滤掉马儿自己的进程,具有恢复SSDT功能的驱动级工具可查。
3、次高级隐藏,INLINE HOOK SSDT,过滤掉自己进程,恢复INLINE的或直接枚举进程链的可查。
4、准高级隐藏,自活动进程链中摘除自己的进程,基于线程调度链表检测技术的工具可查。
5、高级隐藏,绕过内核调度链表隐藏进程,基于HOOK-KiReadyThread技术来检测的工具可查。
对于隐藏进程,请使用具有相应功能的检查工具来检查~
当然了,我们也不一定死乞白咧的非要把木马隐藏的进程找出来,实在找不出,就当没有或当作无进程的木马,直接进行下一步检查就可以了。
因为,进程检查只是检查的手段之一,看不到、杀不掉木马的进程,并不妨碍我们把木马清掉。
OK,无论对进程的检查结果如何,我们接下来都要开始下一步的检查,模块检查!
参照图如下:
下面的图是一张进程检查图(请以数字签名验证的结果为主,以文件路径名字为辅来判断,瑞星杀毒软件的进程不是系统进程,但通过文件名字与路径,我们可以知道,这是瑞星的主控程序,呵呵,不要死心眼,要多方面结合起来判断~ ^-^):
第二章 模块篇
模块是什么?模块,是指具备某一种或某一类功能的特殊功能模块,其外在的表现形式通常为各种动态库文件(通常以.dll为扩展名字)或插件文件(通常以.OCX为扩展名字)。它们由应用程序加载,来为程序提供某一特定的功能。
就像我们的电视机,如果加了一个卫星天线,就可以收到更多的节目一样,卫星天线本身是与电视机无关的,但它一但被电视机所用,就可以为电视机提供额外的功能。卫星天线相对于电视机,也就是相当于模块相对于程序。
每个进程都有几个到上百个不等的模块,每个模块都有其特定的用途,当然了,如果某个模块是木马的话,也有其木马用途。
当进程检查流行起来,且检查的越来越深入时,木马的制造者们开始制作无进程木马,木马是做为一个模块出现的,这样它将不存在于进程列表中。无论你用何等高级的进程检测技术都无法检测到模块木马的存在。
一台电脑中,进程可能有十几个或几十个,但模块却有好几百个,数量的增多也增加了我们检测的难度。
对检测工具的要求,仍然是需要具备数字签名验证的能力,否则手工从几百个模块文件中挑出木马,真的很累~(木马模块的检查,请看下面的图)
找到后怎么办呢?
呵呵,上次有朋友遇到过这问题,结果是他用暴力手段给卸载并删除了~,应该这样处理么?
答案仍然是否定的!
不要暴力卸载并删除~~原因么?原因先缓一缓再说,我们先了解一下儿模块木马的启动运行机制,然后再解释为什么不要暴力卸载删除。
模块木马分为两种:一种是静态加载的,一种是动态注入的。
静态加载的,是把自己的木马文件,在注册表的某键下注册,这样,系统会在开机或运行某一程序时自动的加载在这一键下注册的所有模块,这样,木马就实现了进入到程序中,并执行其非法活动的目的。(在注册表的哪些键下注册可以让系统加载,在后面的启动项检查中会有解释)
动态加载的,这类木马就是所谓的进程注入型木马,它的实现不但需要有一个模块文件,还需要有一个将模块文件注入到进程中的注入程序。先将注入程序启动,然后由注入程序将模块木马注入到其它的进程中,完成注入后,注入程序就结束了运行,这样,你仍然无法看到进程。
现在明白为什么不能暴力卸载并删除了么?
暴力卸载并删除后,如果是静态加载的,那注册表中仍然会留下加载项,每次开机或相关程序运行时仍然会偿试加载该模块,如果多了,会导至系统运行变慢。
如果是动态加载的,那你卸载并删除的仅仅是模块木马,注入程序却仍然留在你的机器上。如果此木马设计的比较合理,那它应该是有模块文件备份的,这样,当你再次开机时,会发现,你暴力删除的模块文件又重新回到了你的机器上,你永远删不干净。如果此木马设计的不合理或比较狠毒,那就只有上帝和木马的制造者才知道会发生事情了~~ -_-!
即然不能暴力删除,那找到后应该如何呢?与进程一样,抄下模块文件的路径与名字,然后,开始下一步的检查,暂时不要理它。
即然说到了无进程木马,那就不得不说“线程注入型木马”,进程注入型的木马注入到进程中的是一个模块,也就是说,必须有一个模块文件的存在,这样我们可以找到这个模块并通过对其文件进行签名验证来找出注入木马;而线程注入型的木马,注入到进程中的却只是一段代码,是没有文件存在的,虽然可以查看每个进程的各个线程,但想发现并找出哪一个线程是木马的,不能说绝不可能,但也几乎是不可能的了,能找出的是非常高的高人,绝不是我~看看下面的第二张图,是EXPLORER.exe的线程列表,能看出什么么?
(顺便说一句,那张图是ProcessExplorer的截图,非常非常出名且非常非常好用的进程管理工具,在这里可以下载:www.sysinternals.com )
那对这种线程注入型的木马又怎么办呢?
幸好,线程注入型的木马也需要有一个注入程序来配合,我们找出线程很难,但找出他的注入程序就好办多了。
现在,无论你是否找到了可疑的模块或线程,我们都要开始下一步的检查,启动项检查!
第三章 自启动项篇
自启动项是什么?自启动项,就是程序在系统的某处进行登记之后,每次开机系统会自动将程序运行,而程序登记的项,就叫做自启动项。
木马都不会甘心只运行一次就结束的,它若想在你的电脑中安家,就肯定要每次开机都运行起来,这样,才能达到自我保护、且正常进行木马工作的目的。
一般的木马都会有一处或多处自启动项,这也成了查找木马时必查的一步。(这只说的是一般的木马,当然就还有二般的不需要自启动项的木马,这个我们放在后面说)
查找木马的自启动项,很关键也很重要,相对的对工具的要求也很高。
系统中到底有多少处地方可以让程序自动运行呢?汗~~偶也不知道,偶只能说N多~~所以,要找个查的全的工具来检查,且要找好几个来检查,这样结合起来,应该就够全了。任何一个也不敢说它能把系统中所有的启动位置全列出来。所以,对启动项检查工具的第一要求是要够全!
只全就够了么?当然还不够,还有一点跟上面相同,也要能进行数字签名验证的,免得它起个系统文件的名字蒙混过去。
还有就是要能够检测隐藏的启动项,同样的,我们先了解木马隐藏启动项用到的技术:
0、木马没隐藏,只是找了个隐蔽的位置而已,这就要看所用的工具程序枚举的项够不够全了。
1、木马隐藏在应用层次,HOOK了WinAPI中的相关注册表枚举函数,这样的马儿很容易检测,任何一个驱动级别的检测程序都可以胜任。
2、木马隐藏在内核层,HOOK了SSDT,这样的马儿,一般的就不行了,得找能恢复SSDT的专业检测程序。
3、木马隐藏在内核层且很无耻,INLINE-HOOK了相关服务函数,这样的马儿绝大多数检程序就都不行了,需要找能恢复INLINE-HOOK的程序。
4、木马隐藏在最底层,通过查找特征码的方法INLINE-HOOK了微软未公开的底层函数如Cm*系列的函数,嘿,已经很难再比它更底层了,这样的马儿只有采用HIVE文件扫描方式的检测程序或专门恢复底层INLINE-HOOK的工具才能找到它。
这四种隐藏方式都是已经有流氓软件或木马使用先例的~,所以不要报有侥幸心理,认为木马不会采用这种高级的技术,所以,检查启动项最好是多用几个工具配合起来检查,功能强的通常不够全,嘿,可能高手都比较懒吧~
OK,我们开始检查吧~ 先把HOOK、INLINE-HOOK都恢复了,再运行工具开始检查,还记得我们前面找到的可疑模块与可疑进程么,这时就用到了,把找出来的启动项与那些对比一下儿,看看是不是有它们的启动项在里面。
有?OK,备份注册表,然后删除启动项。删除不掉?是不是忘记恢复HOOK了?恢复了,那打开注册表编辑器,看看你有没有权限删除这个键,在欲删除的键上面按右键,选权限,再选“完全控制”就可以删除了,呵呵,这只是它玩的一个小障眼法儿。
删除后,又有了?这也没关系,这时你有两个选择,一是先结束掉它的进程,卸载掉它的模块,以使它失去重写的能力。二是,开启“系统锁定”功能,把系统临时锁起来,不允许任何程序对注册表进行写入。这时再删除它就没问题了。
删除完成后,重启计算机。
不是记下了可疑的进程与模块了么?再检查一下子,看它们还在不在?不在了,恭喜,你完成了你的木马查杀工作。
还在?
呵呵,也不要怕,如果还在,证明你并没有真正的完全清除掉它的启动项;可能原因是:
1、这只木马还采取了触发式的启动机制。
2、它还有其它的保护机制,比如影子程序或驱动;
接下来让我们继续解剖触发式启动的木马~~
第四章 触发式木马
上面我说了一般木马的查杀方法,通过上面的查杀,大多数木马都可以清掉了。(上次忘记写了,重启后,如木马已经不能启动了,接下来当然就是把记下来的木马文件全部删掉了)
接着我来说一说触发式木马,什么叫触发式木马呢?触发式木马是当您进行某一操作时会触发木马的启动机制,使得木马启动,如果你永远不进行这一操作,而木马则永远不会启动。一般的木马都是主动启动并运行的,而安全检查工具与杀毒软件检查的也大多是主动启动式的木马,比如对自启动项进行检查,查的就是开机后自动主动运行的。只对少数的常见的可以触发木马启动的项进行检查,而触发木马启动的地方操作却很多,这就是这种木马很难杀干净的原因。
其表现为,清除后的当时系统很正常,当时检查机器也很干净,但用不了多长时间,木马又死灰复燃,再度出现。
现在我们开始实际动手查杀这些难缠的家伙们!
需要说明的是,这里为了讲起来有条理,清楚易懂,所以是分开来讲的,实际查杀起来,当然是可以一起来做的。(检查进程、启动项时,就可顺手检查下面的这些)
最常见的也是我们首先要检查的当然就是Autorun.inf了,这是个什么东西呢?这是一个配置文件,看名字,翻译过来不就是“自动运行”么,是的,这个正常用途是用于光盘的自动播放,就是将光盘插入光驱后,系统会自动运行Autorun.inf里面指定的程序。
后来被一些人用于了硬盘,当将这个文件放在硬盘分区的根目录下时,在盘符上点右键,会发现默认的操作就是“自动播放”而不是打开。这时,你双击某一盘符时,就不再是打开并浏览文件夹,而是直接运行指定的程序(还需要改注册表的某个地方,因与我们查杀无关就不说了,免得被坏人利用)。
你查杀木马病毒时如果采取的是暴力删除,那么,程序删除后,Autorun.inf这个文件却仍然还在,会出现后遗症,表现为无法双击打开磁盘。(顺便提一句,熊猫烧香采用的就是这种触发方式与自启动项相结合的)
由于,你双击磁盘会触发木马的启动,所以查杀时,要右键单击,再选择“打开”或用“资源管理器”来查看,找到后删除此文件。
通常此文件会以隐藏文件的形式出现,更有些恶毒的会加上“注册表监控并回写”来为文件隐藏护航,你一旦更改系统为“显示所有文件”,它马上会再次改为“不显示隐藏文件”,如何破除这种注册表回写保护,上面的贴子里写过方法了,这里不再重复。
另一种触发方式是修改文件关联,什么叫文件关联呢?文件关联就是某一类型的文件与某一程序的对应关系,要知道,我们的系统中有无数种文件格式,比如:文件(以.bmp .jpg .gif等为扩展名)、音乐文件(mp3 mp4等)......当你双击一个时,系统会调用看图程序来打开并显示,而不是调用播放器来播放,系统为什么会知道要调用看图程序而不是调用播放器呢?这就是因为文件关联的存在,在注册表中,文件已经与看图程序关联在了一起,相应的,音乐文件与播放器关联在了一起,大多数类型的文件都与某一特定程序有关联。这样,系统才知道,打开什么样的文件需要调用什么程序。
聪明的您已经知道木马是如何利用文件关联来触发了吧?是的,狡猾的木马就是把某一特定类型文件的关联改为了与它自己关联,这时你一旦打开这一类型的文件就会触发木马的启动。由于木马启动后,会由它再调用正常的关联程序,所以,文件仍然会正常打开,而你也就不知道其实你的操作已经将木马启动了起来。
木马会改哪种文件的关联呢?咳,这我哪知道呢,这只有上帝与木马的作者才知道。
系统中又有多少文件关联可供它改呢?你打开注册表编辑器看看第一大项下面的子项就知道有多少了,怎么也上千个吧。
如何查杀呢?
一般的木马会改一些你会经常用到的文件的关联,比如:文本文件、程序文件、网页文件等。而网上有很多恢复文件关联的程序或注册表导出文件都可以恢复这些常见的文件关联。
但这样检查显然是远远不够的,如果你是木马的作者,你知道这些常见的文件关联会被检查并恢复,你还会改这些么?就不会了吧,因为可供你选择的太多了。比如:选择修改.rar文件的关联,这是类文件是压缩文件,网上提供下载的程序有很多是以这类文件格式存在的,所以一般上网的网民打开压缩文件的机率会非常高,而恢复这一文件关联的程序几乎没有,因为恢复后的直接结果就是压缩文件打不开了,因为恢复程序的作者不是神仙,他不知道你用的是哪个压缩软件,你的压缩软件又安装在了哪里,所以,他不会给你恢复这个的。
这样,只要你打开压缩文件,就会触发木马,如果这个木马的关联文件是一个影子程序的话,那由于影子程序都不具备病毒特征,所以全盘文件扫描也不会将它找出来,你找到并清除的都是这个程序的释放体,而源头还在,从此,木马将成为你挥之不去的恶梦~(关于影子程序我们下一次细讲)
文件关联如何检查呢?两种方法,一种是通过监控得到哪个文件关联被修改的,然后再改回去。第二种是用专业软件,对所有文件关联进行扫描。
如何通过监控得到文件关联是否正确呢?
首先,找个进线程监控的工具程序,打开“进线程监控”,然后不断的打开你常用的各种文件,并检查,打开文件时程序的运行情况,比如:你找开了个.rar文件,进程监视中应该显示,“WinRAR.exe由Explorer.exe启动运行”,那是正常的。如果显示的是其它程序由Explorer.exe运行,而WinRAR.exe又是由那个其它程序来启动的,那就是被改了。当然,你也可以打开注册表查看每个文件关联,是否是正常的。
第二种方法是用专业软件来扫描,把系统文件过滤掉,那剩下的非系统的文件关联就很少了,稍加判断结果就出来了,很简单,就不多讲了,看看下面的图就明白了。
找到后怎么办呢?
不要只是清除,清除后还要找个正常的机器导出一份正常的,或把你删除的文件关联告诉朋友,让朋友自他的机器上导出一份正常的,然后在自己机器上导入一下子就可以了。
如果是非系统的文件关联,比如:.rar压缩文件,那就直接删除了,然后再次找开.rar时,会提示你选择打开此种类型文件的程序,这时选择WinRar.exe,然后勾选上总是用这种程序来打开此类型文件就可以了。
或者用其它方法.....嘿,其实只要发现了木马,其它的就好办了~~
另外,需要注意的是,还有些触发并不是很明显的文件操作,比如当你打开的网站时,可能要解释执行脚本语言,而用什么来解释执行呢?系统也是在注册表中寻找相应程序的,比如:VBS、JScript等键,基本都在HKEY_CLASSES_ROOT主键下。
像卡巴、金山等杀毒程序会用自己的DLL在这几个键下注册,以便执行脚本语言时先行检查这些脚本语言是否具有病毒特征,但木马同样也会利用这几个键,让你一打开网站就执行木马。
好了,我们下面接着说一说影子程序(驱动)吧~因为它们经常与这些触发式的启动机制合作,之所以它们总是合作,因为触发式的可以躲过对启动项、进程、模块的检查,而影子程序却可以躲过杀毒软件的文件扫描。他们是如何紧密合作来躲过我们检查的,让我们下次再说~~~ ^-^
第五章 影子程序(驱动)
什么是影子程序呢?影子大家都了解吧~~即然有影子当然也要有本体了,影子只是为了本体的存在而存在的,其它的工作一概不做。而影子程序呢?也就是为了木马程序的存在而存在的,其本身并不从事任何木马工作。
木马为什么要搞一个影子程序或影子驱动呢?目的只有一个“保护主木马程序不被清除。”
影子是如何来保护主木马程序的呢?了解这个之前,我们先要了解一下杀毒软件是如何杀毒的。
了解了杀毒软件是如何杀毒之后,再谈影子如何逃过杀毒软件的查杀,就容易理解了。
大多数杀毒软件都是依赖病毒特征码杀毒的,所以都附带了一个病毒库,我们平时升级其实大多数是在升级病毒库,病毒库中存储了病毒的特征码,就像病毒档案一样(身高、体重、三围、五官等..... ^-^ 差不多类似啦)如果一个程序与病毒库中的某种病毒特征相吻合,就会被认为是某种病毒而被查杀。病毒特征是如何来的呢?就是病毒分析师对病毒进行分析后提取出来的,所以这种查杀方式查杀的都是有案底的,也就是以前犯过案的,被人留了底,再出来就是过街老鼠,人人喊打了。
这种按特征查杀,属于硬特征,只要符合就OK了~~虽然有误杀,但相对很少,毕竟完全相同的并不多。其查杀的准确与否,误杀率是否高,很大程度依赖于病毒分析师的提取水平。呵呵,偶们就见过某知名公司把一个驱动框架硬是报为ROOTKIT木马的,显然其特征码存在严重问题。
还有一种是所谓的主动防卸型的,在比照特征码的同时,还分析病毒木马的行为特征,一个程序的行为符合特定行为的数量多到一定数值,就为被认为是病毒,当然了, 这种误报率也相应的增加了很多。这种查杀,没案底也可以,就像你以前虽然没有犯过事儿,也没留案底,但你提着刀追着人家猛砍,当然也会被逮住的,因为你的行为符合了病毒的行为特征。
当前病毒的流行越来越大众化,想获取病毒源码也并不是什么难事,一些小屁孩也能抄一段来散发个病毒,但是却没有能力更改代码特征,使其躲过杀毒软件的查杀。
所以,一些人开始拼命的找新壳,来为病毒加不同的壳,但杀毒软件的脱壳技术也是越来越高了,想找到不被杀毒软件所脱的壳也困难起来了。
接着又有些人想出一些其它的方式来躲避杀毒软件的查杀。
影子程序就是其中的一种~~
病毒木马的主程序,因为要工作,所以一些特征是很难去掉的。但影子程序却不用去从事木马工作,所以它本质上就是一个正常的程序,不使用任何病毒技术,也不具备任何病毒特征,所以不会被杀毒软件查杀。
这就是病毒木马采取影子程序的目的,因为影子程序不具备病毒特征,可以躲过杀毒软件的全盘文件扫描。
那它又是如何来保护主程序的呢?一般它是把病毒主程序做为资源放到了自己里面,再保险点就对主程序压缩、加密后再以资源的形式放到自己的程序中。(资源就是一些数据啦~~比如,一个程序中用到的,就属于资源)而杀毒软件通常只是对代码进行检查,而不检查数据资源,其实查也查不出什么来~以纯数据形式存在的资源,有N种方法改变。
这样,影子程序通过资源存放的方式,解决了木马程序在电脑中的生存问题,为木马在您的电脑中留下了一个火种。
在木马病毒被清掉之后,影子程序一旦发现木马主程序不见了,就从自己的资源中重新释放一份。使木马病毒重新再生,使你杀不胜杀,直到杀得你心疲手软自己放弃为止。
影子程序又是如何发现木马主程序被清除的呢?
有两种途径,一是将自己也加在某一个启动位置上,每次开机自动启动,在启动后如果发现木马主程序已经不在,就释放一份,并将木马启动,接着自己就退出了。如果在,影子程序就直接退出了。
二是,利用触发机制等待,等你触发影子程序后,由影子程序去检查木马是否存在,如果不存在就释放并启动然后自己退出,如果在同样也就直接退出了。
由于,影子程序只是运行了那么零点零几秒而已~~所以你的进程检查对它没什么用处,因为它平时是不运行的~
对付影子程序,只能由启动项入手,而影子程序也注意到了这一点,所以很多就采取了触发机制,因此,我们检查时,也要注意检查触发式木马。
呵,结论出来了,各位朋友不要看到进程中的可疑进程就眼红红的冲过去狂杀一通~~杀进程、删除文件、卸模块只是治标不治本的做法~~什么事情都要寻根求源,进行“根治”~~否则,轻则病毒木马是杀不完去不净~~重则是系统被越杀越慢~~杀到最后,不得不重装系统完事儿~~~
用GHOST恢复也很快?呵,难道你不知道熊猫烧香会删除GHOST的备份文件么?熊猫能删除~~其它的当然也能删~~删个文件对它们来说绝不是什么难事儿~~
重装系统就安全么?也不见得~~在网上搜一下儿~看看网上提供下载的操作系统风险又有多大~很多木马是在做操作系统安装盘时就放进去了~~
放进去为什么查不到呢?
这就是另一个话题了~~文件修改替换型的木马~~很让人郁闷的一类木马~~下次再说吧~~
汗~~想起来就头大~
参照图:CNNIC的影子驱动,蓝色圈起来的是主驱动,红色的是影子驱动,影子驱动的名字是随机的,每次开机都不相同。
借这张图把上次有朋友问的清除CNNIC的剩余问题给解答一下子:
在HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\Root键下还有与驱动服务相匹配的一些键,如果用其它的清除工具,记得也要清了。如果是用5.0.0.7就不用了,清除驱动项时会自动清理那个键的。(注意:5.0.0.6版没有相应功能,汗~可能自动检测影子驱动的功能也没有~~手工删除或找别的工具用吧,实在不行就等5.0.0.7出试用版吧~)
清的时候清干净喽~~否则~~嘿~~死恢复燃就是说这个的~~
CNNIC还有关机通知的功能~~别忘记了~~不然即使清干净了,关机时它就又写回去了~~
什么?不知道怎么对付~~汗~~~这个偶暂时也没找到合适的工具,虽然写程序对付最简单,但没有通用性,不值得为这一个家伙写个程序。
暂时有两个方法可以解决:
一个是笨办法。关机时不是由系统通知它的么?偶们就连系统也不通知不就完了,直接按RESET键冷启动机器就OK了~~ -_-!
二个是先恢复FSD的HOOK与INLINE-HOOK,然后把相关的程序文件、驱动文件、DLL文件全删除了,然后重启,再删一遍启动项,也就OK了~(注意,锁定系统好像对CNNIC也不大好用的说~郁闷~)
另外,惯于用AutoRuns.exe的朋友注意了,我用的AutoRuns.exe是8.版的查不出来CNNIC的驱动启动项~如果查杀CNNIC就先换一个用吧~
2025-02-06 15:03
2025-02-06 15:02
2025-02-06 14:24
2025-02-06 14:08
2025-02-06 14:08
2025-02-06 14:00
2025-02-06 13:45
2025-02-06 13:02