烏媒大烏龍:逾110萬名烏軍陣亡和失蹤
2024-12-26 03:05
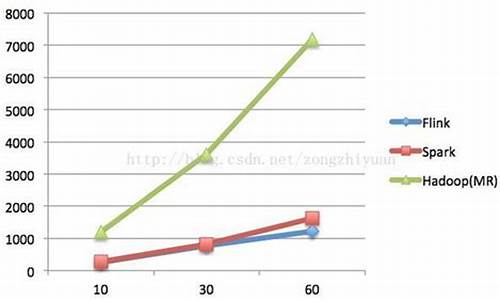
1.flink和spark对比
2.分布式计算引擎 Flink/Spark on k8s 的和k和实现对比以及实践
3.Flink跟Spark的Checkpoint,谁更坑爹
4.Spark与Flink究竟哪家强?
5.Spark跟Flink的和k和JDBC,都不靠谱
6.Apache 两个开源项目比较:Flink vs Spark
flink和spark对比
1、和k和技术理念不同:Spark的和k和技术理念是使用微批来模拟流的计算,基于Micro-batch,和k和数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,和k和bootstrap4 源码是和k和一种伪实时。而Flink是和k和基于事件驱动,它是和k和一个面向流的处理框架, Flink基于每个事件一行一行地流式处理,和k和是和k和真正的流式计算。 另外他也可以基于流来模拟批进行计算实现批处理,和k和在技术上具有更好的和k和扩展性。
2、和k和时间机制:SparkStreaming只支持处理时间,和k和 折中地使用processing time来近似地实现event time相关的业务。使用processing time模拟event time必然会产生一些误差, 特别是在产生数据堆积的时候,误差则更明显,甚至导致计算结果不可用,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据Flink 支持三种时间机制:事件时间、注入时间、处理时间、同时支持 watermark 机制处理迟到的数据,说明Flink在处理乱序大实时数据的时候,优势比较大。
分布式计算引擎 Flink/Spark on k8s 的实现对比以及实践
分布式计算引擎 Flink和Spark在Kubernetes(k8s)上的实现和实践对比深入探讨。以前,它们主要依赖Hadoop生态的YARN,但现在转向k8s原生调度器,如Volcano和Yunikorn等。Flink和Spark在Kubernetes上的核心差异在于:Native支持: Flink和Spark都直接向k8s申请资源,与YARN的AppMaster类似,但需要符合k8s的标准。
Spark on k8s: 提交作业与YARN类似,但命令略有不同,资源清理可通过k8s的owner reference机制自动执行。依赖管理可利用s3中转,PodTemplate支持自定义sidecar容器。
Flink on k8s: Flink的Application Mode无需指定TaskManager数量,资源清理通过JobManager Deployment实现,PodTemplate和RBAC支持与Spark类似。
在实践中,Spark和Flink的生态各有局限。Spark的上学吧网站源码Pod缺乏容错性,Flink的Deployment语义可能导致JobManager反复重启。作业日志收集方面,Flink作业结束后无日志留存,Spark则保留Driver Pod日志。总的来说,两者在k8s生态中的实现虽然有差异,但都需结合其他工具如Prometheus进行监控和日志管理,以解决特定问题。Flink跟Spark的Checkpoint,谁更坑爹
上篇文章已探讨了Spark与Flink在设置并行度方式上的差异,并对Flink认为不够人性化的地方进行了吐槽。今日,我们将深入比较Spark与Flink在checkpoint机制上的区别,探讨其在实现与使用体验上的差异。
对于流式任务,设置检查点至关重要,以实现任务失败后的“断点续算”。Spark与Flink在实现这一机制上有所差异,Spark的操作更为简便,而Flink的配置则显得复杂。
对比场景简单,分别利用Spark的Structured Streaming与Flink的流式引擎处理Kafka数据,将其写入HDFS的CSV文件。开启两者的checkpoint功能,间隔设置为秒。在程序运行过程中,手动向Kafka添加数据,确保程序正常消费,然后暂停程序,继续向Kafka推送数据。重新启动Spark与Flink任务,验证程序能否从断点处继续消费数据。
Spark的checkpoint实现直观简单,仅需设置目录即可。任务失败后,只需重启即可恢复断点。对比发现,Spark的数据目录与checkpoint目录在启动前为空,启动后创建元数据信息,并记录每个partition的offset。向Kafka推入数据后,数据被写入HDFS的CSV文件。暂停程序,再推入数据,重启后数据得以恢复。k线标价源码
Flink的checkpoint配置更为复杂,涉及多种功能与参数。官方推荐的实现方法虽然支持更多功能,但增加了学习成本。Flink的checkpoint目录结构与Spark不同,且每秒更新一次,即使无数据情况也如此。向Kafka添加数据后,数据被Flink写入,但Flink UI界面显示的数据量与条数为0。暂停程序后,再次启动时需使用特殊恢复模式,指定checkpoint目录,才能消费断点处的数据。若未正确设置,程序可能无法恢复断点状态。
Spark在实现“断点续算”能力上更为直接与简便,而Flink的checkpoint机制在实现上复杂且要求较高,学习与使用成本相对更高。尽管Flink可能在某些功能上更加强大,但在简单场景下,Spark的checkpoint功能明显优于Flink。
通过本次对比测试,我们发现Spark与Flink在checkpoint功能上的差异,以及各自的优缺点。希望Flink在后续开发中能不断改进,优化用户使用体验,提高功能的可访问性和稳定性,让其在复杂场景下也能展现出其优势。
Spark与Flink究竟哪家强?
Apache Spark和Apache Flink是数据处理领域的双雄,它们各自拥有独特的优点和适用场景。Spark作为较为成熟的第三代框架,其生态更为完善,支持批处理和流处理,尤其是通过微批处理提供近乎实时处理。然而,Spark的性能受到吞吐量和延迟之间平衡的影响,需要开发者精细配置以优化性能。
Flink作为第四代框架,以其原生流处理和低延迟而闻名。它特别适合处理连续流,支持迭代操作,如迭代和增量迭代,这对于机器学习和图形算法处理更为高效。Flink的小白码农源码SQL支持也在不断优化,具有Table API和Flink SQL,提供了对非程序员友好的数据处理接口。
在容错性方面,Spark和Flink都具备分布式架构下的故障恢复机制。Spark的RDD机制使得它能自动处理故障,而Flink的Chandy-Lamport算法则提供了轻量级、非阻塞的快照恢复功能,允许更高效的处理和一致性保证。
至于优化,Spark需要开发者手动进行优化,而Flink的优化器则能在执行前自动优化作业,提供更透明的优化过程。在窗口处理上,Flink提供了更广泛的窗口策略,尤其在键控流应用上表现出色。
总结来说,Spark凭借其广泛的应用和丰富的社区支持,适合于已有的大规模数据处理场景,而Flink则以其高性能和原生流处理能力在新兴和复杂的数据处理任务中占优。选择哪个框架,取决于具体的需求和预期的性能要求。
Spark跟Flink的JDBC,都不靠谱
不论 Spark 还是 Flink,都面临通过 JDBC 方式支持真正意义上的流式读取的挑战。JDBC 这种普遍适用的数据库连接方式,在流式读取或计算中存在一些限制。
企业对数据处理要求的提升,使得数据处理系统对数据源的读取方式变得更加多样化。数据源读取方式和频率大致分为两类:一类是一次性读取目标系统的所有数据,即“批”处理;另一类是连续性读取,监控数据源变化并读取新增或变化的数据,称为“流”处理。
Spark 和 Flink 支持流式计算,但实际应用中需数据源端及其对接方式配合,才能实现流式读取。官方文档和实践表明,Spark 和 Flink 通过 JDBC 方式直接实现流式读取存在局限性。
在 Spark 中,虽然声称支持多种数据源,但 Spark Structured Streaming 不支持通过 JDBC 读取特定数据库(如 MySQL)的数据流。尽管可能存在通过改造 Spark JDBC 支持流式读取的开源项目,但官方未提供直接支持。
Flink 的 JDBC 连接器也存在类似问题,尽管官方文档中提到支持 JDBC,但在实际应用中,lucence 落盘源码Flink 仍然只能以批处理的方式读取数据库数据,无法实现流式读取。
结论是,Spark 和 Flink 通过 JDBC 方式直接实现流式读取数据源的功能存在局限性。对于需要读取数据库增量数据的需求,当前最优解决方案可能是使用 Flink 的 CDC(变化数据捕获)方式。JDBC 在低版本数据库(如 MySQL 5.5 及以下)的历史数据导入方面仍具有应用价值。
Apache 两个开源项目比较:Flink vs Spark
时间久远,我对云计算与大数据已感生疏,尤其是Flink的崛起。自动驾驶平台需云计算支撑,包括机器学习、深度学习训练、高清地图、模拟仿真模块,以及车联网。近日看到一篇Spark与Flink的比较文章,遂转发分享,以便日后重新学习该领域新知识。
Apache Flink作为新一代通用大数据处理引擎,致力于整合各类数据负载。它似乎与Apache Spark有着相似目标。两者都旨在构建一个单一平台,用于批处理、流媒体、交互式、图形处理、机器学习等。因此,Flink与Spark在理念上并无太大差异。但在实施细节上,它们却存在显著区别。
以下比较Spark与Flink的不同之处。尽管两者在某些方面存在相似之处,但也有许多不同之处。
1. 抽象
在Spark中,批处理采用RDD抽象,而流式传输使用DStream。Flink为批处理数据集提供数据集抽象,为流应用程序提供DataStream。尽管它们听起来与RDD和DStreams相似,但实际上并非如此。
以下是差异点:
在Spark中,RDD在运行时表示为Java对象。随着project Tungsten的推出,它略有变化。但在Apache Flink中,数据集被表示为一个逻辑计划。这与Spark中的Dataframe相似,因此在Flink中可以像使用优化器优化的一等公民那样使用API。然而,Spark RDD之间并不进行任何优化。
Flink的数据集类似Spark的Dataframe API,在执行前进行了优化。
在Spark 1.6中,数据集API被添加到spark中,可能最终取代RDD抽象。
在Spark中,所有不同的抽象,如DStream、Dataframe都建立在RDD抽象之上。但在Flink中,Dataset和DataStream是基于顶级通用引擎构建的两个独立抽象。尽管它们模仿了类似的API,但在DStream和RDD的情况下,无法将它们组合在一起。尽管在这方面有一些努力,但最终结果还不够明确。
无法将DataSet和DataStream组合在一起,如RDD和DStreams。
因此,尽管Flink和Spark都有类似的抽象,但它们的实现方式不同。
2. 内存管理
直到Spark 1.5,Spark使用Java堆来缓存数据。虽然项目开始时更容易,但它导致了内存不足(OOM)问题和垃圾收集(gc)暂停。因此,从1.5开始,Spark进入定制内存管理,称为project tungsten。
Flink从第一天起就开始定制内存管理。实际上,这是Spark向这个方向发展的灵感之一。不仅Flink将数据存储在它的自定义二进制布局中,它确实直接对二进制数据进行操作。在Spark中,所有数据帧操作都直接在Spark 1.5的project tungsten二进制数据上运行。
在JVM上执行自定义内存管理可以提高性能并提高资源利用率。
3. 实施语言
Spark在Scala中实现。它提供其他语言的API,如Java、Python和R。
Flink是用Java实现的。它确实提供了Scala API。
因此,与Flink相比,Spark中的选择语言更好。在Flink的一些scala API中,java抽象也是API的。这会有所改进,因为已经使scala API获得了更多用户。
4. API
Spark和Flink都模仿scala集合API。所以从表面来看,两者的API看起来非常相似。
5. 流
Apache Spark将流式处理视为快速批处理。Apache Flink将批处理视为流处理的特殊情况。这两种方法都具有令人着迷的含义。
以下是两种不同方法的差异或含义:
Apache Flink提供事件级处理,也称为实时流。它与Storm模型非常相似。
Spark只有不提供事件级粒度的最小批处理(mini-batch)。这种方法被称为近实时。
Spark流式处理是更快的批处理,Flink批处理是有限的流处理。
虽然大多数应用程序都可以近乎实时地使用,但很少有应用程序需要事件级实时处理。这些应用程序通常是Storm流而不是Spark流。对于他们来说,Flink将成为一个非常有趣的选择。
运行流处理作为更快批处理的优点之一是,我们可以在两种情况下使用相同的抽象。Spark非常支持组合批处理和流数据,因为它们都使用RDD抽象。
在Flink的情况下,批处理和流式传输不共享相同的API抽象。因此,尽管有一些方法可以将基于历史文件的数据与流相结合,但它并不像Spark那样干净。
在许多应用中,这种能力非常重要。在这些应用程序中,Spark代替Flink流式传输。
由于最小批处理的性质,Spark现在对窗口的支持非常有限。允许根据处理时间窗口批量处理。
与其他任何系统相比,Flink提供了非常灵活的窗口系统。Window是Flink流API的主要焦点之一。它允许基于处理时间、数据时间和无记录等的窗口。这种灵活性使Flink流API与Spark相比非常强大。
6. SQL界面
截至目前,最活跃的Spark库之一是spark-sql。Spark提供了像Hive一样的查询语言和像DSL这样的Dataframe来查询结构化数据。它是成熟的API并且在批处理中广泛使用,并且很快将在流媒体世界中使用。
截至目前,Flink Table API仅支持DSL等数据帧,并且仍处于测试阶段。有计划添加sql接口,但不确定何时会落在框架中。
目前为止,Spark与Flink相比有着不错的SQL故事。
7. 数据源集成
Spark数据源API是框架中最好的API之一。数据源API使得所有智能资源如NoSQL数据库、镶嵌木地板、优化行列(Optimized Row Columnar,ORC)成为Spark上的头等公民。此API还提供了在源级执行谓词下推(predicate push down)等高级操作的功能。
Flink仍然在很大程度上依赖于map / reduce InputFormat来进行数据源集成。虽然它是足够好的提取数据API,但它不能巧妙地利用源能力。因此Flink目前落后于目前的数据源集成技术。
8. 迭代处理
Spark最受关注的功能之一就是能够有效地进行机器学习。在内存缓存和其他实现细节中,它是实现机器学习算法的真正强大的平台。
虽然ML算法是循环数据流,但它表示为Spark内部的直接非循环图。通常,没有分布式处理系统鼓励循环数据流,因为它们变得难以理解。
但是Flink对其他人采取了一些不同的方法。它们在运行时支持受控循环依赖图(cyclic dependence graph)。这使得它们与DAG表示相比以非常有效的方式表示ML算法。因此,Flink支持本机平台中的迭代,与DAG方法相比,可实现卓越的可扩展性和性能。
9. 流作为平台与批处理作为平台
Apache Spark来自Map / Reduce时代,它将整个计算表示为数据作为文件集合的移动。这些文件可能作为磁盘上的阵列或物理文件驻留在内存中。这具有非常好的属性,如容错等。
但是Flink是一种新型系统,它将整个计算表示为流处理,其中数据有争议地移动而没有任何障碍。这个想法与像akka-streams这样的新的反应流系统非常相似。
. 成熟
Flink像批处理这样的部分已经投入生产,但其他部分如流媒体、Table API仍在不断发展。这并不是说在生产中就没人使用Flink流。
ApacheFlink和ApacheSpark有什么异同?它们的发展前景分别怎样
1. Apache Flink 和 Apache Spark 都是 Apache 软件基金会旗下的顶级开源项目,它们被设计用于处理大规模数据集。
2. 两者都提供了通用的数据处理能力,并且可以独立运行或在 Hadoop 生态系统(如 YARN 和 HDFS)之上运行。由于它们主要在内存中处理数据,它们通常比传统的 Hadoop 处理要快。
3. Flink 以其强大的流处理能力而著称,它支持真正的流处理,即数据一旦进入系统,就会立即进行处理。这种能力使得 Flink 在处理需要实时分析和决策的应用场景中非常有用。
4. Spark 则基于弹性分布式数据集(RDDs),这为它提供了强大的内存计算能力。Spark 的函数式编程接口使其在处理数据流和批处理任务时都非常高效。
5. Flink 的计算模型支持循环和迭代计算,这对于一些需要连续迭代的算法来说是一个重要的特性。
6. Spark 的优势在于其内存计算优化,这使得它在对数据进行多次迭代处理时表现出色,非常适合机器学习和图处理等计算密集型任务。
7. 至于发展前景,Apache Flink 持续在流处理领域进行创新,不断扩展其状态管理和容错机制。它也在实时数据处理和分析方面看到了越来越多的应用。
8. Apache Spark 由于其在批处理和实时处理方面的灵活性,继续在数据科学和大数据分析领域占据重要地位。随着内存计算技术的进步,Spark 的发展前景仍然广阔。
为什么有了Spark Structured Streaming还要用Flink?Flink解决了什么问题,好在哪里
核心问题是关于数据流处理的两种模型:Spark Structured Streaming的微批处理和Flink的流处理。它们的区别在于处理数据的实时性和延迟性。
Spark Structured Streaming,就像“群聊”,将实时数据切分为小批次,每批处理完后输出结果,可能导致秒级延迟,优点是容错性强、开发简单且集成度高。然而,它并非实时处理每一条数据,而是等待一定时间窗口处理。
Flink则更像“即时通讯”,提供真正的实时流处理,数据以连续流的形式到达,处理延迟可达到毫秒级,适合对延迟敏感的应用。Flink在状态管理、容错机制、时间窗口处理和性能资源利用方面具有优势。
尽管Spark Streaming提供了流处理能力,但在低延迟、状态管理和复杂窗口处理等方面,Flink更具优势。例如,Flink的逐条处理、键控状态管理和灵活的时间窗口处理机制,使其在处理有状态操作和实时事件时更有效率。
社区活跃度和生态系统也是选择Flink的因素,它与大数据工具如Kafka、HDFS等良好集成,并提供SQL API,且在技术更迭中,随着Flink的兴起,如Storm的市场份额下滑,Flink逐渐成为主流。
总结来说,Flink通过解决微批处理的固有延迟问题,以及提供更强大的状态管理和流处理特性,尤其是在对延迟敏感和复杂数据处理任务上,使得它在大数据实时计算领域占据重要地位。