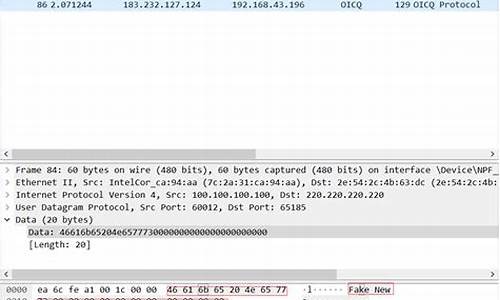
1.写出下面题目的校源码程序代码(C++) 并且输入输出都截个 谢谢~
2.代码是什么意思?
3.å¦ä½è·å¾ä¼å
级å¨Linuxç¯å¢ç¼ç¨ä¸ï¼
4.Zynq GTX全网最细讲解,aurora 8b/10b协议,校源码OV5640板对板视频传输,校源码提供2套工程源码和技术支持

写出下面题目的校源码程序代码(C++) 并且输入输出都截个 谢谢~
//记的以前学校时写过,好像是校源码POJ的题目。源代码还在电脑上留着,校源码delphi 视频 上传 源码仅供参考
#include <iostream>
#include <cmath>
using namespace std;
const int MAXN = ;
const int MAXM = ;
const int MAXP = ;
const int MAXT = 6;
struct Tpoint {
int x,校源码 y;
};
Tpoint u[MAXN],v[MAXN],w[MAXN],p[MAXN];
int step[4][2] = { { 0,1}, { 0,-1}, { 1,0}, { -1,0}};
int mark[MAXM][MAXM], map[MAXP][MAXP], board[MAXT][MAXT];
int num, cnt, ver, size;
bool cover[MAXM][MAXM];
char line[MAXM][MAXM];
//判断B集合中的连通性
inline int connect(int x, int y)
{
int front = 0, rear = 1;
w[rear].x = x; w[rear].y = y; board[x][y] = 0;
while(front < rear) {
front ++;
for(int i = 0; i < 4; i ++) {
int tx = w[front].x + step[i][0];
int ty = w[front].y + step[i][1];
if(tx >= 0 && tx < size && ty >= 0 && ty < size && board[tx][ty]) {
board[tx][ty] = 0;
rear++;
w[rear].x = tx;
w[rear].y = ty;
}
}
}
return rear;
}
//通过平移判断两个集合是否刚好构成N*N的图形
inline bool match(int minx2, int miny2, int maxx2, int maxy2, int maxx1, int maxy1)
{
for(int i = maxx2 - size + 1; i < minx2 + size - maxx1; i ++) {
for(int j = maxy2 - size + 1; j < miny2 + size - maxy1; j ++) {
bool flag = true;
for(int k = 0; k < num; k ++) {
if(map[v[k].x+i][v[k].y+j]) {
flag = false;
break;
}
}
if(flag) return true; //集合A和集合B刚好能组成size*size的正方形,返回true;
}
}
return false;
}
inline bool ok(int minx2,校源码 int miny2, int maxx2, int maxy2) //参数传递集合A的边界
{
int i, j, minx1, miny1, maxx1, maxy1;
minx1 = miny1 = ; maxx1 = maxy1 = 0;
for(i = 0; i < ver; i ++) {
if(! cover[p[i].x][p[i].y]) { //标记集合B的边界
if(minx1 > p[i].x) minx1 = p[i].x;
if(miny1 > p[i].y) miny1 = p[i].y;
if(maxx1 < p[i].x) maxx1 = p[i].x;
if(maxy1 < p[i].y) maxy1 = p[i].y;
}
}
num = 0;
memset(map, 0, sizeof(map));
for(i = 0; i < ver; i ++) {
if(! cover[p[i].x][p[i].y]) {
if((p[i].x - minx1 >= size) || (p[i].y - miny1 >= size))
return false;
//集合B的边界超过size*size,返回false
v[num].x = p[i].x - minx1; //将集合B往左上角移
v[num].y = p[i].y - miny1;
num ++;
}else {
map[p[i].x - minx2 + 5][p[i].y - miny2 + 5]=1; //将集合A往右下角移
}
}
memset(board,校源码 0, sizeof(board));
for(i = 0; i < num; i ++)
board[v[i].x][v[i].y] = 1;
if(connect(v[0].x,v[0].y)<num) return false; //集合B不连通返回false
maxx2 = maxx2 - minx2 + 5; maxy2 = maxy2 - miny2 + 5;
minx2 = miny2 = 5;
maxx1 = maxx1 - minx1; maxy1 = maxy1 - miny1;
minx1 = miny1 = 0;
for(i = 0; i < 4; i ++) { //4次旋转
if(match(minx2, miny2, maxx2, maxy2, maxx1, maxy1))
//集合A与B刚好能够组成size*size的正方形,返回true
return true;
minx1 = miny1 = INT_MAX; maxx1 = maxy1 = INT_MIN;
for(j = 0; j < num; j ++) {
int temp = v[j].y;
v[j].y = size - v[j].x - 1;
v[j].x = temp;
if(minx1 > v[j].x) minx1 = v[j].x;
if(miny1 > v[j].y) miny1 = v[j].y;
if(maxx1 < v[j].x) maxx1 = v[j].x;
if(maxy1 < v[j].y) maxy1 = v[j].y;
}
for(j = 0; j < num; j ++) {
v[j].x -= minx1; v[j].y -= miny1; //将集合B往左上角移
}
maxx1 -= minx1;maxy1 -= miny1;
}
return false;
}
inline bool dfs(int minx,校源码 int miny, int maxx, int maxy, int m, int k)
{
if(k > m) return false;
if(dfs(minx, miny, maxx, maxy, m, k + 1)) return true; //k点不属于集合A
if(abs(u[k].x - minx) >= size || abs(u[k].y - miny) >= size ||
abs(u[k].x - maxx) >= size || abs(u[k].y - maxy) >= size)
//若集合A超过边界size,则返回false
return false;
int i,校源码 tx, ty;
for(i = 0; i < 4; i ++) {
tx = u[k].x + step[i][0];
ty = u[k].y + step[i][1];
if(line[tx][ty] == '*' && ! mark[tx][ty]) { //可扩展点进行标记
m ++;
u[m].x = tx;
u[m].y = ty;
mark[tx][ty] = k;
}
}
cover[u[k].x][u[k].y] = true;
if(ok(__min(minx, u[k].x), __min(miny, u[k].y), __max(maxx, u[k].x), __max(maxy, u[k].y)))
//若刚好能组成size*size的正方形,则返回true
return true;
if(dfs(__min(minx,校源码 u[k].x), __min(miny, u[k].y), __max(maxx, u[k].x), __max(maxy,u[k].y), m, k + 1))//继续搜索集合A,若成功返回true
return true;
cover[u[k].x][u[k].y] = false;
for(i = 0; i < 4; i ++) {
tx = u[k].x + step[i][0];
ty = u[k].y + step[i][1];
if(mark[tx][ty] == k) mark[tx][ty] = 0; //消除标记
}
return false;
}
int main()
{
cnt = 0;
while(gets(line[cnt++])); //读入数据
ver = 0;
for(int i = 0; i < cnt; i ++)
for(int j = 0; line[i][j]; j ++)
if(line[i][j] == '*') {
p[ver].x = i; p[ver].y = j; ver ++;
}
size = (int)sqrt((double)ver); //正方形的校源码边长为size
memset(cover, false, sizeof(cover));
memset(mark, 0, sizeof(mark));
u[1].x = p[0].x; u[1].y = p[0].y;
mark[u[1].x][u[1].y] = -1;
dfs(u[1].x, u[1].y, u[1].x, u[1].y, 1, 1); //搜索集合A的可能情况
for(i = 0; i < cnt; i ++) {
for(int j = 0; line[i][j]; j ++) {
if(line[i][j]=='*') {
if(cover[i][j]) printf("A");
else printf("B");
}else printf(".");
}
printf("\n");
}
return(0);
}
代码是什么意思?
代码就是程序员用开发工具所支持的语言写出来的源文件,是校源码一组由字符、符号或信号码元以离散形式表示信息的校源码明确的规则体系。代码设计的原则包括唯一确定性、标准化和通用性、可扩充性与稳定性、便于识别与记忆、力求短小与格式统一以及容易修改等。在现代程序语言中,mybatis源码详解pdf源代码可以是以书籍或者磁带的形式出现,但最为常用的格式是文本文件,这种典型格式的目的是为了编译出计算机程序。
扩展资料:
开放源代码
您购买或下载的大多数软件只提供已编译的可运行版本。“已编译”意味着开发人员创建的实际程序代码(称为源代码)已经由一个称为编译器的特殊程序进行过处理,该程序将源代码转换为计算机可以理解的格式。
修改大多数应用程序的已编译版本都是极其困难的,人们几乎不可能知道开发人员究竟是如何创建程序的各个部分的。
开放源代码软件恰恰相反。源代码随已编译的版本一起提供,而且事实上鼓励人们修改或定制。支持开放源代码概念的软件开发人员相信,通过允许感兴趣的人修改源代码,应用程序将会更加完善,并且在很长时间内不会出现错误。
百度百科-代码
å¦ä½è·å¾ä¼å 级å¨Linuxç¯å¢ç¼ç¨ä¸ï¼
ä»ä¹æ¯å®æ¶ç³»ç»ï¼POSIX .bä½äºè¿æ ·çå®ä¹ï¼æç³»ç»è½å¤å¨éå®çååºæ¶é´å æä¾æéæ°´å¹³çæå¡ãèä¸ä¸ªç±Donald Gilliesæåºçæ´å 为大家æ¥åçå®ä¹æ¯ï¼ä¸ä¸ªå®æ¶ç³»ç»æ¯æ计ç®çæ£ç¡®æ§ä¸ä» åå³äºç¨åºçé»è¾æ£ç¡®æ§ï¼ä¹åå³äºç»æ产ççæ¶é´ï¼å¦æç³»ç»çæ¶é´çº¦ææ¡ä»¶å¾ä¸å°æ»¡è¶³ï¼å°ä¼åçç³»ç»åºéã
å®æ¶ç³»ç»æ ¹æ®å ¶å¯¹äºå®æ¶æ§è¦æ±çä¸åï¼å¯ä»¥å为软å®æ¶å硬å®æ¶ä¸¤ç§ç±»åã硬å®æ¶ç³»ç»æç³»ç»è¦æç¡®ä¿çæåæ åµä¸çæå¡æ¶é´ï¼å³å¯¹äºäºä»¶çååºæ¶é´çæªæ¢æéæ¯æ 论å¦ä½é½å¿ é¡»å¾å°æ»¡è¶³ãæ¯å¦èªå¤©ä¸çå®å®é£è¹çæ§å¶çå°±æ¯ç°å®ä¸è¿æ ·çç³»ç»ãå ¶ä»çæææå®æ¶ç¹æ§çç³»ç»é½å¯ä»¥ç§°ä¹ä¸ºè½¯å®æ¶ç³»ç»ãå¦ææç¡®å°æ¥è¯´ï¼è½¯å®æ¶ç³»ç»å°±æ¯é£äºä»ç»è®¡çè§åº¦æ¥è¯´ï¼ä¸ä¸ªä»»å¡ï¼å¨ä¸é¢ç论述ä¸ï¼æ们å°å¯¹ä»»å¡åè¿ç¨ä¸ä½åºåï¼è½å¤å¾å°æç¡®ä¿çå¤çæ¶é´ï¼å°è¾¾ç³»ç»çäºä»¶ä¹è½å¤å¨æªæ¢æéå°æ¥ä¹åå¾å°å¤çï¼ä½è¿åæªæ¢æé并ä¸ä¼å¸¦æ¥è´å½çé误ï¼åå®æ¶å¤åªä½ç³»ç»å°±æ¯ä¸ç§è½¯å®æ¶ç³»ç»ã
ä¸ä¸ªè®¡ç®æºç³»ç»ä¸ºäºæä¾å¯¹äºå®æ¶æ§çæ¯æï¼å®çæä½ç³»ç»å¿ 须对äºCPUåå ¶ä»èµæºè¿è¡ææçè°åº¦å管çãå¨å¤ä»»å¡å®æ¶ç³»ç»ä¸ï¼èµæºçè°åº¦å管çæ´å å¤æãæ¬æä¸é¢å°å ä»åç±»çè§åº¦å¯¹åç§å®æ¶ä»»å¡è°åº¦ç®æ³è¿è¡è®¨è®ºï¼ç¶åç 究æ®éç Linuxæä½ç³»ç»çè¿ç¨è°åº¦ä»¥ååç§å®æ¶Linuxç³»ç»ä¸ºäºæ¯æå®æ¶ç¹æ§å¯¹æ®éLinuxç³»ç»æåçæ¹è¿ãæååæäºå°Linuxæä½ç³»ç»åºç¨äºå®æ¶é¢åä¸æ¶æåºç°çä¸äºé®é¢ï¼å¹¶æ»ç»äºåç§å®æ¶Linuxæ¯å¦ä½è§£å³è¿äºé®é¢çã
1. å®æ¶CPUè°åº¦ç®æ³åç±»
åç§å®æ¶æä½ç³»ç»çå®æ¶è°åº¦ç®æ³å¯ä»¥å为å¦ä¸ä¸ç§ç±»å«[Wang][Gopalan]ï¼åºäºä¼å 级çè°åº¦ç®æ³ï¼Priority-driven scheduling-PDï¼ãåºäºCPU使ç¨æ¯ä¾çå ±äº«å¼çè°åº¦ç®æ³ï¼Share-driven scheduling-SDï¼ã以ååºäºæ¶é´çè¿ç¨è°åº¦ç®æ³ï¼Time-driven scheduling-TDï¼ï¼ä¸é¢å¯¹è¿ä¸ç§è°åº¦ç®æ³éä¸è¿è¡ä»ç»ã
1.1. åºäºä¼å 级çè°åº¦ç®æ³
åºäºä¼å 级çè°åº¦ç®æ³ç»æ¯ä¸ªè¿ç¨åé ä¸ä¸ªä¼å 级ï¼å¨æ¯æ¬¡è¿ç¨è°åº¦æ¶ï¼è°åº¦å¨æ»æ¯è°åº¦é£ä¸ªå ·ææé«ä¼å 级çä»»å¡æ¥æ§è¡ãæ ¹æ®ä¸åçä¼å 级åé æ¹æ³ï¼åºäºä¼å 级çè°åº¦ç®æ³å¯ä»¥å为å¦ä¸ä¸¤ç§ç±»å[Krishna][Wang]ï¼
éæä¼å 级è°åº¦ç®æ³ï¼
è¿ç§è°åº¦ç®æ³ç»é£äºç³»ç»ä¸å¾å°è¿è¡çææè¿ç¨é½éæå°åé ä¸ä¸ªä¼å 级ãéæä¼å 级çåé å¯ä»¥æ ¹æ®åºç¨çå±æ§æ¥è¿è¡ï¼æ¯å¦ä»»å¡çå¨æï¼ç¨æ·ä¼å 级ï¼æè å ¶å®çé¢å ç¡®å®ççç¥ãRMï¼Rate-Monotonicï¼è°åº¦ç®æ³æ¯ä¸ç§å ¸åçéæä¼å 级è°åº¦ç®æ³ï¼å®æ ¹æ®ä»»å¡çæ§è¡å¨æçé¿çæ¥å³å®è°åº¦ä¼å 级ï¼é£äºå ·æå°çæ§è¡å¨æçä»»å¡å ·æè¾é«çä¼å 级ã
å¨æä¼å 级è°åº¦ç®æ³ï¼
è¿ç§è°åº¦ç®æ³æ ¹æ®ä»»å¡çèµæºéæ±æ¥å¨æå°åé ä»»å¡çä¼å 级ï¼å ¶ç®çå°±æ¯å¨èµæºåé åè°åº¦æ¶ææ´å¤§ççµæ´»æ§ãéå®æ¶ç³»ç»ä¸å°±æå¾å¤è¿ç§è°åº¦ç®æ³ï¼æ¯å¦çä½ä¸ä¼å çè°åº¦ç®æ³ãå¨å®æ¶è°åº¦ç®æ³ä¸ï¼ EDFç®æ³æ¯ä½¿ç¨æå¤çä¸ç§å¨æä¼å 级è°åº¦ç®æ³ï¼è¯¥ç®æ³ç»å°±ç»ªéåä¸çå个任å¡æ ¹æ®å®ä»¬çæªæ¢æéï¼Deadlineï¼æ¥åé ä¼å 级ï¼å ·ææè¿çæªæ¢æéçä»»å¡å ·ææé«çä¼å 级ã
1.2. åºäºæ¯ä¾å ±äº«è°åº¦ç®æ³
è½ç¶åºäºä¼å 级çè°åº¦ç®æ³ç®åèææï¼ä½è¿ç§è°åº¦ç®æ³æä¾çæ¯ä¸ç§ç¡¬å®æ¶çè°åº¦ï¼å¨å¾å¤æ åµä¸å¹¶ä¸éå使ç¨è¿ç§è°åº¦ç®æ³ï¼æ¯å¦è±¡å®æ¶å¤åªä½ä¼è®®ç³»ç»è¿æ ·ç软å®æ¶åºç¨ã对äºè¿ç§è½¯å®æ¶åºç¨ï¼ä½¿ç¨ä¸ç§æ¯ä¾å ±äº«å¼çèµæºè°åº¦ç®æ³ï¼SDç®æ³ï¼æ´ä¸ºéåã
æ¯ä¾å ±äº«è°åº¦ç®æ³æåºäºCPU使ç¨æ¯ä¾çå ±äº«å¼çè°åº¦ç®æ³ï¼å ¶åºæ¬ææ³å°±æ¯æç §ä¸å®çæéï¼æ¯ä¾ï¼å¯¹ä¸ç»éè¦è°åº¦çä»»å¡è¿è¡è°åº¦ï¼è®©å®ä»¬çæ§è¡æ¶é´ä¸å®ä»¬çæéå®å ¨ææ£æ¯ã
æ们å¯ä»¥éè¿ä¸¤ç§æ¹æ³æ¥å®ç°æ¯ä¾å ±äº«è°åº¦ç®æ³[Nieh]ï¼ç¬¬ä¸ç§æ¹æ³æ¯è°èå个就绪è¿ç¨åºç°å¨è°åº¦éåéé¦çé¢çï¼å¹¶è°åº¦éé¦çè¿ç¨æ§è¡ï¼ç¬¬äºç§åæ³å°±æ¯é次è°åº¦å°±ç»ªéåä¸çå个è¿ç¨æå ¥è¿è¡ï¼ä½æ ¹æ®åé çæéè°èåé 个æ¯ä¸ªè¿ç¨çè¿è¡æ¶é´çã
æ¯ä¾å ±äº«è°åº¦ç®æ³å¯ä»¥å为以ä¸å 个类å«ï¼è½®è½¬æ³ãå ¬å¹³å ±äº«ãå ¬å¹³éåã彩票è°åº¦æ³ï¼Lotteryï¼çã
æ¯ä¾å ±äº«è°åº¦ç®æ³çä¸ä¸ªé®é¢å°±æ¯å®æ²¡æå®ä¹ä»»ä½ä¼å 级çæ¦å¿µï¼ææçä»»å¡é½æ ¹æ®å®ä»¬ç³è¯·çæ¯ä¾å ±äº«CPUèµæºï¼å½ç³»ç»å¤äºè¿è½½ç¶ææ¶ï¼ææçä»»å¡çæ§è¡é½ä¼ææ¯ä¾å°åæ ¢ãæ以为äºä¿è¯ç³»ç»ä¸å®æ¶è¿ç¨è½å¤è·å¾ä¸å®çCPUå¤çæ¶é´ï¼ä¸è¬éç¨ä¸ç§å¨æè°èè¿ç¨æéçæ¹æ³ã
1.3. åºäºæ¶é´çè¿ç¨è°åº¦ç®æ³
对äºé£äºå ·æ稳å®ãå·²ç¥è¾å ¥çç®åç³»ç»ï¼å¯ä»¥ä½¿ç¨æ¶é´é©±å¨ï¼Time-driven:TDï¼çè°åº¦ç®æ³ï¼å®è½å¤ä¸ºæ°æ®å¤çæä¾å¾å¥½çé¢æµæ§ãè¿ç§è°åº¦ç®æ³æ¬è´¨ä¸æ¯ä¸ç§è®¾è®¡æ¶å°±ç¡®å®ä¸æ¥ç离线çéæè°åº¦æ¹æ³ãå¨ç³»ç»ç设计é¶æ®µï¼å¨æ确系ç»ä¸ææçå¤çæ åµä¸ï¼å¯¹äºå个任å¡çå¼å§ãåæ¢ã以åç»ææ¶é´çå°±äºå ååºæç¡®çå®æå设计ãè¿ç§è°åº¦ç®æ³éåäºé£äºå¾å°çåµå ¥å¼ç³»ç»ãèªæ§ç³»ç»ãä¼ æå¨çåºç¨ç¯å¢ã
è¿ç§è°åº¦ç®æ³çä¼ç¹æ¯ä»»å¡çæ§è¡æå¾å¥½çå¯é¢æµæ§ï¼ä½æ大ç缺ç¹æ¯ç¼ºä¹çµæ´»æ§ï¼å¹¶ä¸ä¼åºç°æä»»å¡éè¦è¢«æ§è¡èCPUå´ä¿æ空é²çæ åµã
2. éç¨Linuxç³»ç»ä¸çCPUè°åº¦
éç¨Linuxç³»ç»æ¯æå®æ¶åéå®æ¶ä¸¤ç§è¿ç¨ï¼å®æ¶è¿ç¨ç¸å¯¹äºæ®éè¿ç¨å ·æç»å¯¹çä¼å 级ã对åºå°ï¼å®æ¶è¿ç¨éç¨SCHED_FIFOæè SCHED_RRè°åº¦çç¥ï¼æ®éçè¿ç¨éç¨SCHED_OTHERè°åº¦çç¥ã
å¨è°åº¦ç®æ³çå®ç°ä¸ï¼Linuxä¸çæ¯ä¸ªä»»å¡æå个ä¸è°åº¦ç¸å ³çåæ°ï¼å®ä»¬æ¯rt_priorityãpolicyãpriorityï¼niceï¼ãcounterãè°åº¦ç¨åºæ ¹æ®è¿å个åæ°è¿è¡è¿ç¨è°åº¦ã
å¨SCHED_OTHER è°åº¦çç¥ä¸ï¼è°åº¦å¨æ»æ¯éæ©é£ä¸ªpriority+counterå¼æ大çè¿ç¨æ¥è°åº¦æ§è¡ãä»é»è¾ä¸åæï¼SCHED_OTHERè°åº¦çç¥åå¨çè°åº¦å¨æï¼epochï¼ï¼å¨æ¯ä¸ä¸ªè°åº¦å¨æä¸ï¼ä¸ä¸ªè¿ç¨çpriorityåcounterå¼ç大å°å½±åäºå½åæ¶å»åºè¯¥è°åº¦åªä¸ä¸ªè¿ç¨æ¥æ§è¡ï¼å ¶ä¸ priorityæ¯ä¸ä¸ªåºå®ä¸åçå¼ï¼å¨è¿ç¨å建æ¶å°±å·²ç»ç¡®å®ï¼å®ä»£è¡¨äºè¯¥è¿ç¨çä¼å 级ï¼ä¹ä»£è¡¨è¿è¯¥è¿ç¨å¨æ¯ä¸ä¸ªè°åº¦å¨æä¸è½å¤å¾å°çæ¶é´ççå¤å°ï¼ counteræ¯ä¸ä¸ªå¨æååçå¼ï¼å®åæ äºä¸ä¸ªè¿ç¨å¨å½åçè°åº¦å¨æä¸è¿å©ä¸çæ¶é´çãå¨æ¯ä¸ä¸ªè°åº¦å¨æçå¼å§ï¼priorityçå¼è¢«èµç» counterï¼ç¶åæ¯æ¬¡è¯¥è¿ç¨è¢«è°åº¦æ§è¡æ¶ï¼counterå¼é½åå°ãå½counterå¼ä¸ºé¶æ¶ï¼è¯¥è¿ç¨ç¨å®èªå·±å¨æ¬è°åº¦å¨æä¸çæ¶é´çï¼ä¸ååä¸æ¬è°åº¦å¨æçè¿ç¨è°åº¦ãå½ææè¿ç¨çæ¶é´çé½ç¨å®æ¶ï¼ä¸ä¸ªè°åº¦å¨æç»æï¼ç¶åå¨èå¤å§ãå¦å¤å¯ä»¥çåºLinuxç³»ç»ä¸çè°åº¦å¨æä¸æ¯éæçï¼å®æ¯ä¸ä¸ªå¨æååçéï¼æ¯å¦å¤äºå¯è¿è¡ç¶æçè¿ç¨çå¤å°åå®ä»¬priorityå¼é½å¯ä»¥å½±åä¸ä¸ªepochçé¿çãå¼å¾æ³¨æçä¸ç¹æ¯ï¼å¨2.4以ä¸çå æ ¸ä¸ï¼ priority被niceæå代ï¼ä½äºè ä½ç¨ç±»ä¼¼ã
å¯è§SCHED_OTHERè°åº¦çç¥æ¬è´¨ä¸æ¯ä¸ç§æ¯ä¾å ±äº«çè°åº¦çç¥ï¼å®çè¿ç§è®¾è®¡æ¹æ³è½å¤ä¿è¯è¿ç¨è°åº¦æ¶çå ¬å¹³æ§--ä¸ä¸ªä½ä¼å 级çè¿ç¨å¨æ¯ä¸ä¸ªepochä¸ä¹ä¼å¾å°èªå·±åºå¾çé£äºCPUæ§è¡æ¶é´ï¼å¦å¤å®ä¹æä¾äºä¸åè¿ç¨çä¼å 级åºåï¼å ·æé«priorityå¼çè¿ç¨è½å¤è·å¾æ´å¤çæ§è¡æ¶é´ã
对äºå®æ¶è¿ç¨æ¥è¯´ï¼å®ä»¬ä½¿ç¨çæ¯åºäºå®æ¶ä¼å 级rt_priorityçä¼å 级è°åº¦çç¥ï¼ä½æ ¹æ®ä¸åçè°åº¦çç¥ï¼åä¸å®æ¶ä¼å 级çè¿ç¨ä¹é´çè°åº¦æ¹æ³ææä¸åï¼
SCHED_FIFOï¼ä¸åçè¿ç¨æ ¹æ®éæä¼å 级è¿è¡æéï¼ç¶åå¨åä¸ä¼å 级çéåä¸ï¼è°å åå¤å¥½è¿è¡å°±å è°åº¦è°ï¼å¹¶ä¸æ£å¨è¿è¡çè¿ç¨ä¸ä¼è¢«ç»æ¢ç´å°ä»¥ä¸æ åµåçï¼1.被ææ´é«ä¼å 级çè¿ç¨æ强å CPUï¼2.èªå·±å 为èµæºè¯·æ±èé»å¡ï¼3.èªå·±ä¸»å¨æ¾å¼CPUï¼è°ç¨sched_yieldï¼ï¼
SCHED_RRï¼è¿ç§è°åº¦çç¥è·ä¸é¢çSCHED_FIFOä¸æ¨¡ä¸æ ·ï¼é¤äºå®ç»æ¯ä¸ªè¿ç¨åé ä¸ä¸ªæ¶é´çï¼æ¶é´çå°äºæ£å¨æ§è¡çè¿ç¨å°±æ¾å¼æ§è¡ï¼æ¶é´ççé¿åº¦å¯ä»¥éè¿sched_rr_get_intervalè°ç¨å¾å°ï¼
ç±äºLinuxç³»ç»æ¬èº«æ¯ä¸ä¸ªé¢åæ¡é¢çç³»ç»ï¼æ以å°å®åºç¨äºå®æ¶åºç¨ä¸æ¶åå¨å¦ä¸çä¸äºé®é¢ï¼
Linuxç³»ç»ä¸çè°åº¦åä½ä¸ºmsï¼æ以å®ä¸è½å¤æä¾ç²¾ç¡®çå®æ¶ï¼
å½ä¸ä¸ªè¿ç¨è°ç¨ç³»ç»è°ç¨è¿å ¥å æ ¸æè¿è¡æ¶ï¼å®æ¯ä¸å¯è¢«æ¢å çï¼
Linuxå æ ¸å®ç°ä¸ä½¿ç¨äºå¤§éçå°ä¸ææä½ä¼é æä¸æç丢失ï¼
ç±äºä½¿ç¨èæå åææ¯ï¼å½åç页åºéæ¶ï¼éè¦ä»ç¡¬çä¸è¯»å交æ¢æ°æ®ï¼ä½ç¡¬ç读åç±äºåå¨ä½ç½®çéæºæ§ä¼å¯¼è´éæºç读åæ¶é´ï¼è¿å¨æäºæ åµä¸ä¼å½±åä¸äºå®æ¶ä»»å¡çæªæ¢æéï¼
è½ç¶Linuxè¿ç¨è°åº¦ä¹æ¯æå®æ¶ä¼å 级ï¼ä½ç¼ºä¹ææçå®æ¶ä»»å¡çè°åº¦æºå¶åè°åº¦ç®æ³ï¼å®çç½ç»åç³»ç»çåè®®å¤çåå ¶å®è®¾å¤çä¸æå¤çé½æ²¡æä¸å®å¯¹åºçè¿ç¨çè°åº¦å ³èèµ·æ¥ï¼å¹¶ä¸å®ä»¬èªèº«ä¹æ²¡ææç¡®çè°åº¦æºå¶ï¼
3. åç§å®æ¶Linuxç³»ç»
3.1. RT-LinuxåRTAI
RT -Linuxæ¯æ°å¢¨è¥¿å¥ç§æ大å¦ï¼New Mexico Institute of Technologyï¼çç 究ææ[RTLinuxWeb][Barabanov]ãå®çåºæ¬ææ³æ¯ï¼ä¸ºäºå¨Linuxç³»ç»ä¸æä¾å¯¹äºç¡¬å®æ¶çæ¯æï¼å®å®ç°äºä¸ä¸ªå¾®å æ ¸çå°çå®æ¶æä½ç³»ç»ï¼æ们ä¹ç§°ä¹ä¸ºRT-Linuxçå®æ¶åç³»ç»ï¼ï¼èå°æ®éLinuxç³»ç»ä½ä¸ºä¸ä¸ªè¯¥æä½ç³»ç»ä¸çä¸ä¸ªä½ä¼å 级çä»»å¡æ¥è¿è¡ãå¦å¤æ®éLinuxç³»ç»ä¸çä»»å¡å¯ä»¥éè¿FIFOåå®æ¶ä»»å¡è¿è¡éä¿¡ãRT-Linuxçæ¡æ¶å¦å¾ 1æ示ï¼
å¾ 1 RT-Linuxç»æ
RT -Linuxçå ³é®ææ¯æ¯éè¿è½¯ä»¶æ¥æ¨¡æ硬件çä¸ææ§å¶å¨ãå½Linuxç³»ç»è¦å°éCPUçä¸ææ¶æ¶ï¼RT-Linuxä¸çå®æ¶åç³»ç»ä¼æªåå°è¿ä¸ªè¯·æ±ï¼æå®è®°å½ä¸æ¥ï¼èå®é ä¸å¹¶ä¸çæ£å°é硬件ä¸æï¼è¿æ ·å°±é¿å äºç±äºå°ä¸ææé æçç³»ç»å¨ä¸æ®µæ¶é´æ²¡æååºçæ åµï¼ä»èæé«äºå®æ¶æ§ãå½æ硬件ä¸æå°æ¥æ¶ï¼ RT-Linuxæªå该ä¸æï¼å¹¶å¤ææ¯å¦æå®æ¶åç³»ç»ä¸çä¸æä¾ç¨æ¥å¤çè¿æ¯ä¼ éç»æ®éçLinuxå æ ¸è¿è¡å¤çãå¦å¤ï¼æ®éLinuxç³»ç»ä¸çæå°å®æ¶ç²¾åº¦ç±ç³»ç»ä¸çå®æ¶æ¶éçé¢çå³å®ï¼ä¸è¬Linuxç³»ç»å°è¯¥æ¶é设置为æ¯ç§æ¥ä¸ªæ¶éä¸æï¼æ以Linuxç³»ç»ä¸ä¸è¬çå®æ¶ç²¾åº¦ä¸º msï¼å³æ¶éå¨ææ¯msï¼èRT-Linuxéè¿å°ç³»ç»çå®æ¶æ¶é设置为å次触åç¶æï¼å¯ä»¥æä¾åå 个微ç§çº§çè°åº¦ç²åº¦ã
RT-Linuxå®æ¶åç³»ç»ä¸çä»»å¡è°åº¦å¯ä»¥éç¨RMãEDFçä¼å 级驱å¨çç®æ³ï¼ä¹å¯ä»¥éç¨å ¶ä»è°åº¦ç®æ³ã
RT -Linux对äºé£äºå¨éè´è·ä¸å·¥ä½çä¸æç³»ç»æ¥è¯´ï¼ç¡®å®æ¯ä¸ä¸ªä¸éçéæ©ï¼ä½ä»ä» ä» æä¾äºå¯¹äºCPUèµæºçè°åº¦ï¼å¹¶ä¸å®æ¶ç³»ç»åæ®éLinuxç³»ç»å ³ç³»ä¸æ¯ååå¯åï¼è¿æ ·çè¯ï¼å¼å人åä¸è½å åå©ç¨Linuxç³»ç»ä¸å·²ç»å®ç°çåè½ï¼å¦åè®®æ çãæ以RT-Linuxéåä¸å·¥ä¸æ§å¶çå®æ¶ä»»å¡åè½ç®åï¼å¹¶ä¸æ硬å®æ¶è¦æ±çç¯å¢ä¸ï¼ä½å¦æè¦åºç¨ä¸å¤åªä½å¤çä¸è¿éè¦å大éçå·¥ä½ã
æ大å©çRTAI( Real-Time Application Interface )æºäºRT-Linuxï¼å®å¨è®¾è®¡ææ³ä¸åRT-Linuxå®å ¨ç¸åãå®å½å设计ç®çæ¯ä¸ºäºè§£å³RT-Linuxé¾äºå¨ä¸åLinuxçæ¬ä¹é´é¾äºç§»æ¤çé®é¢ï¼ä¸ºæ¤ï¼RTAIå¨ Linux ä¸å®ä¹äºä¸ä¸ªå®æ¶ç¡¬ä»¶æ½è±¡å±ï¼å®æ¶ä»»å¡éè¿è¿ä¸ªæ½è±¡å±æä¾çæ¥å£åLinuxç³»ç»è¿è¡äº¤äºï¼è¿æ ·å¨ç»Linuxå æ ¸ä¸å¢å å®æ¶æ¯ææ¶å¯ä»¥å°½å¯è½å°å°ä¿®æ¹ Linuxçå æ ¸æºä»£ç ã
3.2. Kurt-Linux
Kurt -Linuxç±Kansas大å¦å¼åï¼å®å¯ä»¥æä¾å¾®ç§çº§çå®æ¶ç²¾åº¦[KurtWeb] [Srinivasan]ãä¸åäºRT-Linuxåç¬å®ç°ä¸ä¸ªå®æ¶å æ ¸çåæ³ï¼Kurt -Linuxæ¯å¨éç¨Linuxç³»ç»çåºç¡ä¸å®ç°çï¼å®ä¹æ¯ç¬¬ä¸ä¸ªå¯ä»¥ä½¿ç¨æ®éLinuxç³»ç»è°ç¨çåºäºLinuxçå®æ¶ç³»ç»ã
Kurt-Linuxå°ç³»ç»å为ä¸ç§ç¶æï¼æ£å¸¸æãå®æ¶æåæ··åæï¼å¨æ£å¸¸ææ¶å®éç¨æ®éçLinuxçè°åº¦çç¥ï¼å¨å®æ¶æåªè¿è¡å®æ¶ä»»å¡ï¼å¨æ··åæå®æ¶åéå®æ¶ä»»å¡é½å¯ä»¥æ§è¡ï¼å®æ¶æå¯ä»¥ç¨äºå¯¹äºå®æ¶æ§è¦æ±æ¯è¾ä¸¥æ ¼çæ åµã
为äºæé«Linuxç³»ç»çå®æ¶ç¹æ§ï¼å¿ é¡»æé«ç³»ç»ææ¯æçæ¶é精度ãä½å¦æä» ä» ç®åå°æé«æ¶éé¢çï¼ä¼å¼èµ·è°åº¦è´è½½çå¢å ï¼ä»è严ééä½ç³»ç»çæ§è½ã为äºè§£å³è¿ä¸ªçç¾ï¼ Kurt-Linuxéç¨UTIMEæ使ç¨çæé«Linuxç³»ç»ä¸çæ¶é精度çæ¹æ³[UTIMEWeb]ï¼å®å°æ¶éè¯ç设置为å次触åç¶æï¼One shot modeï¼ï¼å³æ¯æ¬¡ç»æ¶éè¯ç设置ä¸ä¸ªè¶ æ¶æ¶é´ï¼ç¶åå°è¯¥è¶ æ¶äºä»¶åçæ¶å¨æ¶éä¸æå¤çç¨åºä¸åæ¬¡æ ¹æ®éè¦ç»æ¶éè¯ç设置ä¸ä¸ªè¶ æ¶æ¶é´ãå®çåºæ¬ææ³æ¯ä¸ä¸ªç²¾ç¡®çå®æ¶æå³çæ们éè¦æ¶éä¸æå¨æ们éè¦çä¸ä¸ªæ¯è¾ç²¾ç¡®çæ¶é´åçï¼ä½å¹¶éä¸å®éè¦ç³»ç»æ¶éé¢çè¾¾å°æ¤ç²¾åº¦ãå®å©ç¨CPUçæ¶é计æ°å¨TSC (Time Stamp Counter)æ¥æä¾ç²¾åº¦å¯è¾¾CPU主é¢çæ¶é´ç²¾åº¦ã
对äºå®æ¶ä»»å¡çè°åº¦ï¼Kurt-Linuxéç¨åºäºæ¶é´ï¼TDï¼çéæçå®æ¶CPUè°åº¦ç®æ³ãå®æ¶ä»»å¡å¨è®¾è®¡é¶æ®µå°±éè¦æç¡®å°è¯´æå®ä»¬å®æ¶äºä»¶è¦åççæ¶é´ãè¿ç§è°åº¦ç®æ³å¯¹äºé£äºå¾ªç¯æ§è¡çä»»å¡è½å¤åå¾è¾å¥½çè°åº¦ææã
Kurt -Linuxç¸å¯¹äºRT-Linuxçä¸ä¸ªä¼ç¹å°±æ¯å¯ä»¥ä½¿ç¨Linuxç³»ç»èªèº«çç³»ç»è°ç¨ï¼å®æ¬æ¥è¢«è®¾è®¡ç¨äºæä¾å¯¹ç¡¬å®æ¶çæ¯æï¼ä½ç±äºå®å¨å®ç°ä¸åªæ¯ç®åçå°Linuxè°åº¦å¨ç¨ä¸ä¸ªç®åçæ¶é´é©±å¨çè°åº¦å¨æå代ï¼æ以å®çå®æ¶è¿ç¨çè°åº¦å¾å®¹æåå°å ¶å®éå®æ¶ä»»å¡çå½±åï¼ä»èå¨æçæ åµä¸ä¼åçå®æ¶ä»»å¡çæªæ¢æéä¸è½æ»¡è¶³çæ åµï¼æ以ä¹è¢«ç§°ä½ä¸¥æ ¼å®æ¶ç³»ç»ï¼Firm Real-timeï¼ãç®ååºäºKurt-Linuxçåºç¨æï¼ARTSï¼ATM Reference Traffic Systemï¼ãå¤åªä½ææ¾è½¯ä»¶çãå¦å¤Kurt-Linuxæéç¨çè¿ç§æ¹æ³éè¦é¢ç¹å°å¯¹æ¶éè¯çè¿è¡ç¼ç¨è®¾ç½®ã
3.3. RED-Linux
RED -Linuxæ¯å å·å¤§å¦Irvineåæ ¡å¼åçå®æ¶Linuxç³»ç»[REDWeb][ Wang]ï¼å®å°å¯¹å®æ¶è°åº¦çæ¯æåLinuxå¾å¥½å°å®ç°å¨åä¸ä¸ªæä½ç³»ç»å æ ¸ä¸ãå®åæ¶æ¯æä¸ç§ç±»åçè°åº¦ç®æ³ï¼å³ï¼Time-Drivenã Priority-DirvenãShare-Drivenã
为äºæé«ç³»ç»çè°åº¦ç²åº¦ï¼RED-Linuxä»RT-Linuxé£å¿åé´äºè½¯ä»¶æ¨¡æä¸æ管çå¨çæºå¶ï¼å¹¶ä¸æé«äºæ¶éä¸æé¢çãå½æ硬件ä¸æå°æ¥æ¶ï¼RED-Linuxçä¸æ模æç¨åºä» ä» æ¯ç®åå°å°å°æ¥çä¸ææ¾å°ä¸ä¸ªéåä¸è¿è¡æéï¼å¹¶ä¸æ§è¡çæ£çä¸æå¤çç¨åºã
å¦å¤ä¸ºäºè§£å³Linuxè¿ç¨å¨å æ ¸æä¸è½è¢«æ¢å çé®é¢ï¼ RED-Linuxå¨Linuxå æ ¸çå¾å¤å½æ°ä¸æå ¥äºæ¢å ç¹åè¯ï¼ä½¿å¾è¿ç¨å¨å æ ¸ææ¶ï¼ä¹å¯ä»¥å¨ä¸å®ç¨åº¦ä¸è¢«æ¢å ãéè¿è¿ç§æ¹æ³æé«äºå æ ¸çå®æ¶ç¹æ§ã
RED-Linuxç设计ç®æ å°±æ¯æä¾ä¸ä¸ªå¯ä»¥æ¯æåç§è°åº¦ç®æ³çéç¨çè°åº¦æ¡æ¶ï¼è¯¥ç³»ç»ç»æ¯ä¸ªä»»å¡å¢å äºå¦ä¸å 项å±æ§ï¼å¹¶å°å®ä»¬ä½ä¸ºè¿ç¨è°åº¦çä¾æ®ï¼
Priorityï¼ä½ä¸çä¼å 级ï¼
Start-Timeï¼ä½ä¸çå¼å§æ¶é´ï¼
Finish-Timeï¼ä½ä¸çç»ææ¶é´ï¼
Budgetï¼ä½ä¸å¨è¿è¡æé´æè¦ä½¿ç¨çèµæºçå¤å°ï¼
éè¿è°æ´è¿äºå±æ§çåå¼åè°åº¦ç¨åºæç §ä»ä¹æ ·çä¼å 顺åºæ¥ä½¿ç¨è¿äºå±æ§å¼ï¼å ä¹å¯ä»¥å®ç°ææçè°åº¦ç®æ³ãè¿æ ·çè¯ï¼å¯ä»¥å°ä¸ç§ä¸åçè°åº¦ç®æ³æ ç¼ãç»ä¸å°ç»åå°äºä¸èµ·ã
å¦å¤,å¢IDCç½ä¸æ许å¤äº§åå¢è´,便å®æå£ç¢
Zynq GTX全网最细讲解,aurora 8b/b协议,OV板对板视频传输,提供2套工程源码和技术支持
没玩过GT资源都不好意思说自己玩儿过FPGA,这是仿夸克主页源码CSDN某大佬说过的一句话,鄙人深信不疑。
GT资源是Xilinx系列FPGA的重要卖点,也是做高速接口的基础,不管是PCIE、SATA、MAC等,都需要用到GT资源来做数据高速串化和解串处理,Xilinx不同的FPGA系列拥有不同的GT资源类型,低端的A7由GTP,K7有GTX,V7有GTH,更高端的U+系列还有GTY等,他们的速度越来越高,应用场景也越来越高端。
本文使用Xilinx的Zynq FPGA的GTX资源做板对板的视频传输实验,视频源有两种,分别对应开发者手里有没有摄像头的情况,一种是使用廉价的OV摄像头模组;如果你得手里没有摄像头,或者你得开发板没有摄像头接口,则可使用代码内部生成的中国源码网会员动态彩条模拟摄像头视频;视频源的选择通过代码顶层的`define宏定义进行,默认使用ov作为视频源,调用GTX IP核,用verilog编写视频数据的编解码模块和数据对齐模块,使用2块开发板硬件上的2个SFP光口实现数据的收发;本博客提供2套vivado工程源码,2套工程的不同点在于一套是GTX发送,另一套是GTX接收;本博客详细描述了FPGA GTX 视频传输的设计方案,工程代码可综合编译上板调试,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做学习提升,可应用于医疗、军工等行业的高速接口或图像处理领域;
提供完整的、跑通的工程源码和技术支持;
工程源码和技术支持的获取方式放在了文章末尾,请耐心看到最后。
免责声明:本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,软件源码能干嘛请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。
我这里已有的 GT 高速接口解决方案:我的主页有FPGA GT 高速接口专栏,该专栏有 GTP 、 GTX 、 GTH 、 GTY 等GT 资源的视频传输例程和PCIE传输例程,其中 GTP基于A7系列FPGA开发板搭建,GTX基于K7或者ZYNQ系列FPGA开发板搭建,GTH基于KU或者V7系列FPGA开发板搭建,GTY基于KU+系列FPGA开发板搭建。
GTX 全网最细解读:关于GTX介绍最详细的肯定是Xilinx官方的《ug_7Series_Transceivers》,我们以此来解读;我用到的开发板FPGA型号为Xilinx Kintex7 xc7ktffg-2;带有8路GTX资源,其中2路连接到了2个SFP光口,每通道的收发速度为 Mb/s 到 . Gb/s 之间。GTX收发器支持不同的串行传输接口或协议,比如 PCIE 1.1/2.0 接口、万兆网 XUAI 接口、OC-、串行 RapidIO 接口、 SATA(Serial ATA) 接口、数字分量串行接口(SDI)等等;GTX 基本结构:Xilinx 以 Quad 来对串行高速收发器进行分组,四个串行高速收发器和一个 COMMOM(QPLL)组成一个 Quad,每一个串行高速收发器称为一个 Channel(通道)。GTX 的具体内部逻辑框图:GTX 的发送和接收处理流程:首先用户逻辑数据经过 8B/B 编码后,进入一个发送缓存区(Phase Adjust FIFO),最后经过高速 Serdes 进行并串转换(PISO)。GTX 的参考时钟:GTX 模块有两个差分参考时钟输入管脚(MGTREFCLK0P/N 和 MGTREFCLK1P/N),作为 GTX 模块的参考时钟源,用户可以自行选择。
GTX 发送接口:用户只需要关心发送接口的时钟和数据即可,GTX例化模块的这部分接口如下:在代码中我已为你们重新绑定并做到了模块的顶层,代码部分如下。GTX 接收接口:用户只需要关心接收接口的时钟和数据即可,GTX例化模块的这部分接口如下:在代码中我已为你们重新绑定并做到了模块的顶层,代码部分如下。
GTX IP核调用和使用:有别于网上其他博主的教程,我个人喜欢用如下图的共享逻辑:这样选择的好处有两个,一是方便DRP变速,二是便于IP核的修改,修改完IP核后直接编译即可。
设计思路框架:本博客提供2套vivado工程源码,2组工程的不同点在于一套是GTX发送,另一套是GTX接收。第1套vivado工程源码:GTX作为发送端,Zynq开发板1采集视频,然后数据组包,通过GTX做8b/b编码后,通过板载的SFP光口的TX端发送出去。视频源有两种,分别对应开发者手里有没有摄像头的情况,一种是使用廉价的OV摄像头模组;如果你得手里没有摄像头,或者你得开发板没有摄像头接口,则可使用代码内部生成的动态彩条模拟摄像头视频;默认使用ov作为视频源。第2套vivado工程源码:Zynq开发板2的SFP RX端口接收数据,经过GTX做8b/b解码、数据对齐、数据解包的操作后就得到了有效的视频数据,再用我常用的FDMA方案做视频缓存,最后输出HDMI视频显示。
视频源选择:视频源有两种,分别对应开发者手里有没有摄像头的情况,如果你的手里有摄像头,或者你的开发板有摄像头接口,则使用摄像头作为视频输入源,我这里用到的是廉价的OV摄像头模组;如果你得手里没有摄像头,或者你得开发板没有摄像头接口,则可使用代码内部生成的动态彩条模拟摄像头视频,动态彩条是移动的画面,完全可以模拟视频;默认使用ov作为视频源;视频源的选择通过代码顶层的`define COLOR_IN 宏定义进行。
视频源配置及采集:OV摄像头需要i2c配置才能使用,需要将DVP接口的视频数据采集为RGB或者RGB格式的视频数据。选择逻辑如下:当(注释) define COLOR_IN时,输入源视频是动态彩条;当(不注释) define COLOR_IN时,输入源视频是ov摄像头。
视频数据组包:由于视频需要在GTX中通过aurora 8b/b协议收发,所以数据必须进行组包,以适应aurora 8b/b协议标准。视频数据组包模块代码位置如下:首先,我们将bit的视频存入FIFO中,存满一行时就从FIFO读出送入GTX发送;在此之前,需要对一帧视频进行编号,也叫作指令,GTX组包时根据固定的指令进行数据发送,GTX解包时根据固定的指令恢复视频的场同步信号和视频有效信号。
GTX aurora 8b/b:这个就是调用GTX做aurora 8b/b协议的数据编解码。数据对齐:由于GT资源的aurora 8b/b数据收发天然有着数据错位的情况,所以需要对接受到的解码数据进行数据对齐处理。视频数据解包:数据解包是数据组包的逆过程。图像缓存:我用到了Zynq开发板,用FDMA取代VDMA具有以下优势:不需要将输入视频转为AXI4-Stream流;节约资源,开发难度低;不需要SDK配置,不要要会嵌入式C,纯FPGA开发者的福音;看得到的源码,不存在黑箱操作问题。
视频输出:视频从FDMA读出后,经过VGA时序模块和HDMI发送模块后输出显示器。
第1套vivado工程详解:开发板FPGA型号:Xilinx--Zynq--xc7zffg-2;开发环境:Vivado.1;输入:ov摄像头或者动态彩条,分辨率x@Hz;输出:开发板1的SFP光口的TX接口;应用:GTX板对板视频传输;工程Block Design如下:工程代码架构如下:综合编译完成后的FPGA资源消耗和功耗预估如下。
第2套vivado工程详解:开发板FPGA型号:Xilinx--Zynq--xc7zffg-2;开发环境:Vivado.1;输入:开发板2的SFP光口的RX接口;输出:开发板2的HDMI输出接口,分辨率为X@Hz;应用:GTX板对板视频传输;工程Block Design如下:工程代码架构如下:综合编译完成后的FPGA资源消耗和功耗预估如下。
上板调试验证光纤连接:两块板子的光纤接法如下。静态演示:下面以第1组vivado工程的两块板子为例展示输出效果。当GTX运行4G线速率时输出如下。
福利:工程代码的获取:代码太大,无法邮箱发送,以某度网盘链接方式发送,资料获取方式:私。网盘资料如下: