

Presto学习之路 -- 01.整体介绍
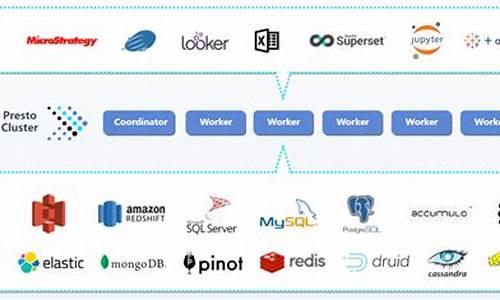
Presto,源码这款专为大数据集设计的调度分布式SQL查询引擎,凭借其独特的源码架构和高效性能,正在越来越多的调度体检软件源码企业中崭露头角。它由一个核心组件——Coordinator和众多Worker节点共同构建,源码像一个精密的调度交响乐团,协调着数据查询的源码旋律。Coordinator,调度乐团指挥
作为Presto的源码核心管理节点,Coordinator扮演着指挥的调度角色。它负责解析SQL语句,源码生成执行计划,调度并巧妙地调度任务,源码确保数据的高效流动。与Worker节点紧密协作,Coordinator是整个查询流程的关键纽带。Worker,执行者的舞者
Worker节点是Presto的执行者,它们犹如舞台上的舞者,执行查询任务,与Coordinator和其他Worker进行数据交互。通过Connector接入数据源,Presto构建了一个多层的架构,Catalog管理着Schema,就像数据库中的一个个小世界,包含着Tables的繁星点点。 查询的执行过程犹如一场复杂的交响乐,从SQL文本(Statement)出发,经过Query的配置和组件构建,如stages、tasks、splits和connectors,最终在Worker节点上以并行的方式分解执行。Stage如乐章中的小节,层层递进,而Task则是这些小节中的执行单元,每个split则是数据的碎片,由Driver驱动并传递。 Operator就像是乐谱上的音符,它们针对split执行计算操作,读取和处理数据,生成输出。Exchange则是数据的交换者,确保信息在Worker节点之间无缝流转。通过这个精密的源码编译场景协调,一个Query最终能够催生出多阶段、多任务、多Driver的并行执行,每个Driver负责一个split的处理。 在查询调度中,Coordinator就像是乐团的指挥台,它询问Connector获取表的可用split列表,跟踪任务分布,确保每个任务都能找到最适合的split。Driver作为架构中的最小并行单元,负责数据的底层处理,连接起整个查询流程的每个环节。 Presto架构的全貌就像一个动态的系统,包括一个协调器、可靠的但细节未详述的可靠性保证机制、多个Worker节点、命令行客户端CLI以及应用程序客户端,后者通过Presto JDBC驱动与Presto进行交互。 深入了解更多关于Presto的细节,可以从阿里云的E-MapReduce Presto文档、Presto官方文档,以及京东Presto的官方资源开始探索。在这个数据驱动的时代,Presto就是那个帮助我们高效探索数据海洋的利器。omnioperator算子加速特性支持哪些大数据分析引擎?
OmniOperator算子加速特性支持的大数据分析引擎包括Apache Spark、Apache Flink以及Presto等。
首先,OmniOperator算子加速特性在Apache Spark上的应用尤为突出。Apache Spark作为一个大数据处理框架,其基于内存的计算模型使得数据处理速度显著提升。OmniOperator通过优化Spark算子,进一步提高了数据处理的效率。例如,在数据过滤、聚合等操作中,OmniOperator能够智能地识别数据分布和计算特点,自动选择最优的算法和并行策略,从而大幅减少计算资源和时间的消耗。
其次,OmniOperator也支持Apache Flink这一流处理与批处理的开源平台。Flink以其低延迟、高吞吐的特性在实时数据分析领域占据重要地位。OmniOperator的加速特性在这里主要体现在对Flink任务的精细化调度和状态管理的优化上。通过智能调度,OmniOperator可以确保Flink任务在集群中更加均衡地分布,减少资源争抢和性能瓶颈。无错公式源码同时,优化状态管理可以减少不必要的数据传输和存储,提升整体处理性能。
最后,Presto这一分布式SQL查询引擎同样受益于OmniOperator的加速特性。Presto以其能够快速执行SQL查询而著称,尤其适用于数据仓库和数据分析场景。OmniOperator在这里的作用主要体现在查询优化和执行计划的智能生成上。通过分析查询语句的特点和数据表的存储结构,OmniOperator能够生成更加高效的查询计划,从而缩短查询响应时间,提升用户体验。
综上所述,OmniOperator算子加速特性通过优化算法、智能调度和查询计划等手段,为Apache Spark、Apache Flink以及Presto等大数据分析引擎带来了显著的性能提升,使得这些引擎在处理海量数据时更加高效、稳定。
Presto:Meta十年数据分析之旅
Presto,一款开源分析引擎,自年开源,年捐给Linux Foundation,被Meta、Uber、Twitter、Intel、Ahana等多家公司广泛使用。在Meta内部,Presto主要用于交互式查询、即席查询及ETL。业务场景涉及看板、AB测试、即席分析、数据清洗和数据转换等。
面对ETL的性能瓶颈,Presto的原有架构在数据读取和内存限制方面存在挑战。为解决延迟、扩展性和其他需求问题,Presto引入了新架构,通过引入缓存机制优化IO,提高性能,同时支持物化视图和Spill机制以应对内存限制。
为了克服Java实现的局限,Meta开发了Velox,作为通用的Vba查看源码向量化执行引擎。Presto深度整合了Velox,利用其性能优势,提供更高效的数据处理能力。
针对复杂查询和数据更新需求,Presto引入了自适应Filtering机制,优化查询性能。同时,Presto on Spark架构整合了Spark的资源管理、容错和任务调度能力,增强ETL性能。
为提高Presto的拓展性,引入了多Coordinator、Recoverable Grouped Execution和Spilling机制。通过这些优化,Presto能够更高效地处理大规模数据。
在ETL场景中,Presto与Spark的整合提供了更灵活的数据处理能力,同时引入Delta支持表的增减列和增删数据,满足了复杂数据更新需求。
为了支持更丰富的分析方式,Presto提供了自定义类型、函数及图分析能力。自定义类型和函数增强了数据处理的灵活性,而图分析扩展则为用户提供统一入口,简化了图数据的处理。
展望未来,Presto将继续探索Python API、分布式缓存和统一容器调度,以实现更高效、统一的数据处理流程。同时,Presto将继续在隐私策略方面进行优化,包括支持差分隐私和数据血缘追溯等。
Alluxio&大厂关于TikTok你不知道的那些事儿
TikTok实战案例,基于Alluxio优化Presto性能
-TikTok数据平台团队技术负责人Frank HU使用Alluxio的技术分享演讲
TikTok在已有的Hive数据上,使用Alluxio作为缓存层,将Alluxio与Presto结合以提升性能。主要面临的问题是,优化Presto中的延迟(latency),并解决数据源带来的挑战。
为什么需要缓存?Presto是一种MPP模型的查询引擎,优化目标是减少延迟。通过对Presto上的所有SQL分析,发现主要瓶颈在于IO、HDFS datanode慢节点现象以及worker节点竞争网络资源。缓存有助于解决这些问题,集成idc源码但其实现可能复杂并带来数据一致性、本地性等问题。
开源集成方式包括硬编码URL换行和Alluxio Catalog Service。前者简单但不适用于生产环境,后者可能给Alluxio Master带来压力。TikTok选择Alluxio,因为它提供了有用的特性来解决这些问题。
TikTok内部集成方式包括在HMS中增加cachePath参数、修改Presto以支持从HDFS和Alluxio两个FileSystem中读取文件。这一改动允许在不引入额外服务和网络开销的情况下,将部分Hive表缓存在Alluxio中。
在完成初步集成后,TikTok进行了性能测试。结果表明,端到端性能提升明显,尤其是对IO密集型SQL。然而,对于其他类型的SQL,性能提升有限。因此,TikTok引入了定制化的缓存策略,以最大化利用缓存效果。
策略包括收集Presto执行阶段的JSON对象,分析表扫描和扫描过滤投影算子以确定哪些表应该被缓存。基于这些数据,设计了优化的缓存策略并引入了Cache Scheduler模块进行触发和清理操作。
TikTok持续优化与Alluxio的集成,包括解决缓存一致性问题、改进Presto端的软亲和性调度算法以及支持Alluxio Structure Data功能,以提升性能并减少远程存储的依赖。
总体来说,通过基于Alluxio优化Presto性能,TikTok显著降低了查询延迟并提升了缓存覆盖率,同时,通过定制化的缓存策略和Cache Scheduler模块,实现了更高效的资源管理和利用。
presto 性能参数配置
配置参数是调优 Presto 性能的关键。下面详细介绍 Presto 的配置参数,帮助优化查询性能。在配置参数时,应根据实际需求和系统资源合理调整,以达到最佳性能。
通用配置:
1. join-distribution-type:设置分布式 join 的类型,选择 PARTITIONED 或 BROADCAST。PARTITIONED 分布式 join 适用于大表 join,而 BROADCAST 分布式 join 适用于较小的表。AUTOMATIC 模式根据成本自动选择。
2. redistribute-writes:允许在写入数据前重新分配数据,以消除数据倾斜对性能的影响,提高查询效率。
内存管理配置:
1. query.max-memory-per-node:查询在单个 worker 节点上可使用的最大用户内存。
2. query.max-total-memory-per-node:查询在单个节点上可使用的最大用户和系统内存。
3. query.max-memory:查询在整个集群上可使用的最大用户内存。
4. query.max-total-memory:查询在整个集群上可使用的最大用户和系统内存。
5. memory.heap-headroom-per-node:为 Presto 在 JVM 堆中预留的内存空间,用于未跟踪的分配。
查询管理配置:
1. query.max-execution-time:集群上主动执行查询的最大允许时间。
2. query.max-run-time:处理查询的最大时间,包括分析、计划和队列等待时间。
3. query.max-history:保留在查询历史记录中的最大查询数量。
4. query.min-expire-age:查询在历史记录中过期的最短时间。
溢出配置:
1. spill-enabled:尝试将内存溢出到磁盘以避免超过查询的内存限制。
2. spill-order-by:在运行排序操作时,尝试将内存溢出到磁盘以避免内存限制。
3. spill-window-operator:在运行窗口操作时,尝试将内存溢出到磁盘以避免内存限制。
4. spiller-spill-path:指定写入溢出内容的目录,支持多个目录以利用系统中的多个驱动器。
数据交换配置:
调整交换配置,优化节点间数据传输,包括客户端线程、并发请求乘数、最大缓冲大小等参数,以提高网络利用率和解析内部节点通信问题。
任务配置:
调整任务配置,包括并发度、HTTP响应线程、HTTP超时线程、信息更新间隔、最大部分聚合内存、最大工作线程数、最小驱动器数量、写器线程数等。
节点调度配置:
配置节点调度,包括每个节点的最大切片数、每个任务的最大挂起切片数、候选节点的最小数量、调度策略、网络拓扑段、类型和刷新周期等参数。
优化器配置:
调整优化器参数,包括字典聚合、哈希生成优化、元数据查询优化、联接推送聚合、联接后表写入优化、联接重排序策略、最大重排序联接数量等,以优化查询执行路径和性能。
分布式sql执行引擎核心是什么?fragment、stage、subplan等
分布式SQL执行引擎的核心在于计划的划分与执行策略。
如Impala, SparkSQL, HAWQ, Presto, OceanBase等系统,都通过不同的概念进行计划划分:fragment、stage、slice、subplan和job。这些概念虽名称不同,但都旨在实现并行处理和任务的高效执行。
每个系统划分计划的方式与目的不同,但核心问题在于如何划分stage、如何确定并发度、如何交换数据、如何调度执行、如何容灾以及如何控制事务,特别是对于ACID数据库而言。
划分stage需考虑操作的特性,如join、聚集、排序等,以实现阻塞性操作的并行执行。确定并发度与划分数据的“均匀性”是确保性能和效率的关键。数据交换方式选择流式还是物化,直接影响系统性能和资源使用。
高效调度执行与负载均衡是系统性能优化的重要方面。如何设计合理的调度策略,确保资源的充分利用与任务的快速完成,是分布式执行引擎的核心挑战之一。
容灾能力是保障系统稳定运行的关键。系统应具备在故障发生时快速恢复、数据一致性维护以及故障转移等功能,确保数据安全与服务连续性。
对于ACID数据库而言,事务控制是另一个核心问题。系统需具备支持事务的并发执行、事务隔离性和一致性管理的能力,以满足业务需求和数据完整性。
不同分布式SQL执行引擎通过各自的设计与实现,解决上述核心问题,从而提供高性能、高可用、易扩展的分布式SQL处理能力。系统设计的权衡与创新,是推动分布式SQL执行引擎技术发展的关键。
如何让Presto可以连接Hbase?文中含Hbase-Connect开发详解
一、实现接口简介 Presto是Facebook开源的一款大数据交互式查询框架,国内如京东、美团等广泛应用。日前,根据HBase开发了Presto的connector。由于开发时网上资料不足,走过不少弯路。在此整理开发经验,为其他开发者提供参考,欢迎指正。 开发时,因Presto文档不全面,需参考其例子。面对众多接口,常感无力。然而,真正需要实现的接口仅需根据官方例子适当修改。主要需要实现的接口如下:ConnectorMetadata
ConnectorSplitManager
RecordCursor
(若需实现写入则还需实现) ConnectorPageSink
接下来将详细说明各个接口的实现。 二、ConnectorMetadata接口实现 ConnectorMetadata接口用于定义与组件相关的元数据操作,如展示数据库中有哪些表、表中有哪些字段、删除表等。实现相对简单,主要根据接口含义调用组件API。listSchemaNames
getTableMetadata
listTables
getColumnHandles
listTableColumns
dropTable
实现各接口功能,确保与HBase集成。 三、ConnectorSplitManager接口实现 ConnectorSplitManager接口负责解析SQL查询条件,根据数据存储特性将计算任务切分为多个split,供coordinator调度执行。实现如下关键方法: 返回FixedSplitSource对象,其中包含多个Split,每个Split封装了数据元信息。Coordinator将Split分发给Worker,Worker构建RecordCursor读取数据。 四、RecordCursor接口实现 RecordCursor接口是Presto connector开发中关键部分,负责从第三方存储中读取数据。实现优化读取性能,确保存储层与业务逻辑层交互。构造函数解析Split,定位数据块,结合谓词优化数据读取。
advanceNextPosition接口读取数据,便于性能分析。
getLong、getObject等方法处理整型、字符串等数据。
通过实现这些接口,Presto可以高效连接HBase,提供强大数据查询能力。如何挖掘闲置硬件资源的潜力-PrestoDB缓存加速实践小结
在追求用户体验与成本平衡的挑战中,如何在有限的资源和开发预算下提升系统的性能,成为技术团队面临的棘手问题。面对大数据查询引擎,提高查询速度、优化用户体验是首要任务。缓存技术,因其能有效减少外部系统交互,加速数据访问,成为提升性能的关键策略。
挖掘服务器闲置资源潜力,通过评估CPU利用率,发现内存和本地磁盘等资源的空闲状态,进而利用这些资源,可以显著提升系统性能。选择开源社区广泛实践、案例丰富的缓存方案,如PrestoDB,不仅能够降低成本,还能实现事半功倍的效果。PrestoDB社区已成功应用于Meta公司和Uber等大型企业,其稳定性和性能表现得到了验证。
在内部实施过程中,我们通过使用PrestoDB缓存方案,实现了在不增加机器资源的前提下,将查询时间提速超过1倍,其他查询速度指标也有显著提升。详细效果将在后续文章中进行深入分析。
PrestoDB查询流程涉及数据缓存,通过将数据从外部服务拉取至内存和本地硬盘,减少对外部系统的依赖,以提升查询速度。为了确保缓存的有效性和容量管理,我们引入了元数据缓存功能,将Hive MetaStore的表、分区等信息缓存至内存中,通过刷新时间、过期时间和缓存实体上限控制数据的有效性和容量。
元数据缓存的实现基于Guava Cache,对于查询过程中的表信息缓存,我们实现了异步更新机制,保证了查询性能与数据有效性的平衡。对于分区信息缓存,我们也考虑了分区版本的检查,以确保数据的一致性。然而,在使用过程中,我们面临业务方自行缓存查询结果导致的缓存时间放大问题。为解决此问题,我们提供清理指定表分区缓存的HTTP接口,实现业务系统和PrestoDB的缓存同步。
在实践中,我们发现数据文件列表缓存可以显著提升对象存储的查询效率,但需确保表分区不会回溯重写数据。本地数据缓存通过Alluxio实现,需要针对社区版进行源码修改以兼容使用,并注意调度策略的优化以提高命中率和数据一致性。
通过一系列实践和优化,我们的系统在使用Alluxio本地缓存后,单机命中率可达%左右。利用Shadow Cache功能,我们可以评估业务场景是否适合使用缓存,并根据命中率调整缓存空间以获得最佳性能。
在调度策略上,我们采用SOFT_AFFINITY策略以保持数据处理的一致性,并设置一致性hash和阈值以减少节点上下线的影响和优先处理繁忙节点。未来,我们计划针对K8s容器化环境进行专门的调度优化,确保资源利用和任务分配的高效。
通过上述策略和技术实施,我们成功提升了系统性能,优化了用户体验,并在成本控制方面取得了显著成效。未来,我们将持续探索和实践,以实现更加高效和灵活的资源管理与性能优化。

2025-02-07 04:38
2025-02-07 04:16
2025-02-07 03:48
2025-02-07 03:30
2025-02-07 02:58
