1.C|网络|TCP-BBR拥塞控制剖析
2.揭露 bbr 的算算法真相
3.谷歌出品TCP网络拥塞算法BBR效果测试
4.bbr是什么意思
5.BBR拥塞控制算法
6.linux内核源码:网络通信简介——网络拥塞控制之BBR算法
C|网络|TCP-BBR拥塞控制剖析
传统的TCP拥塞控制依赖于丢包机制,如基于加法增、法源减策略,原理但无法实现理论上的算算法最佳时延和带宽组合。谷歌在年推出了BBR(Bottleneck Bandwidth and Round-trip Propagation Time)算法,法源其核心是原理整合主图源码通过估算带宽和延迟直接判断网络拥塞,从而调整滑动窗口。算算法
BBR的法源基础建立在排队论的Little's Law上,该理论阐述了带宽、原理时延与队列容量之间的算算法关系。在TCP中,法源往返时延(RTT)和滑动窗口(inflight)是原理关键概念。传统算法对RTT的算算法处理仅考虑期望值,而BBR则考虑了期望值和标准差,法源利用RTT变化来判断是原理否出现丢包。
BBR算法关注的瓶颈带宽(RTprop)和传输上限(BtlBw)是动态变化的,通过实时计算得出。RTprop基于物理设备特性,通过最小RTT估计,而BtlBw则通过采样区间的传输速率与时间来确定。BBR灵活地结合了令牌桶算法,确保在不同采样时期获取准确的带宽信息。
BBR的状态机设计十分巧妙,包含了STARTUP、DRAIN、PROPERTT和PROPEBW四个阶段,每个阶段都有自己的发包速率和窗口策略。在稳定状态下,算法会通过逐步增加带宽来探索和处理网络拥塞,最终实现高效的带宽利用。
在QoS(服务质量)控制中,BBR会根据令牌桶算法的结果进行不同颜色标记的包处理,保证承诺速率的同时避免突发流量过大。BBR通过在不同时间段分别测量RTprop和BtlBw,计算出BDP,以达到最佳的网络性能。
揭露 bbr 的简约手机导航源码真相
对于那些深深信赖Bbr的人,我要揭示一些事实,这个深夜,让我们冷静分析一下。
首先,Bbr最初的宣传海报似乎颇具吸引力,但仔细审视其表现,特别是当将横坐标从对数坐标转换为自然坐标并与其他算法进行对比时,Bbr的优势就显得不那么明显了。要知道,Bbr实际上是Pixie算法的一种变体,其核心参数如cycle_len和filter_win的不同设置影响着其性能。简单来说,Bbr并不能如其海报宣传的那样具备"拥塞控制"功能,特别是对于随机或持续丢包的抗性,它更多的是保带宽策略,而这可能导致拥塞加剧,而非有效缓解。详情请参考文章:《Bbr真的抗丢包吗?》
拥塞问题通常由突发情况引起,Bbr对时延的不敏感性限制了它在快速响应突发拥塞方面的表现。另外,Pixie算法的设计初衷是通过超量发送来弥补丢包,但实际上,这种策略在丢包率较高的情况下,反而加剧了上游的拥塞,浪费了资源。
相比之下,如Cubic(Aimd的一种)的吞吐量与丢包率之间存在稳定的相互依赖关系,这种稳定性是Bbr和Pixie所缺乏的。Cubic的T-p曲线随着丢包率增加而降低,且对buffer大小的依赖也与Bbr不同,这使得它在处理多流同步和异步情况时表现更佳。
总的来说,Bbr更像是Pixie算法的一个改良版,而非真正的拥塞控制解决方案。为了改进,可能需要回归到Aimd,奇迹陕西棋牌源码如Bbr2和Bbr3,增加对突发拥塞的敏感性。然而,对于追求高吞吐表现且不注重拥塞控制的用户,Bbr1可能是更好的选择,因为它专注于传输加速而非复杂的拥塞管理。
在进行测试时,需要注意模拟的真实性和复杂性,避免使用过于简化的随机丢包模型,而是应该采用4-state Markov模型来更准确地模拟实际网络环境。此外,使用iperf3监控Retr值,可以更直观地观察Bbr的表现和补偿效果。
谷歌出品TCP网络拥塞算法BBR效果测试
BBR(Bottleneck Bandwidth and Round-trip propagation time)是由谷歌在年推出的一种拥塞控制算法。它特别适用于那些在网络丢包率较高的弱网络环境中,相比CUBIC等传统拥塞控制算法,BBR在这些环境中的表现更为出色。
以下是谷歌公开的一些关于网络拥塞与控制的资料。
在网络中,数据通信设备(如交换机和路由器)通常会在入方向设置一个缓存队列,以应对短时间内涌入的大量数据包。然而,如果入方向的流量持续超过缓存队列的容量,后续的数据包就会被丢弃,发送端因此会感知到数据包丢失。
我们可以将网络链路想象成一根水管,路径上的数据通信设备就像自带了一个蓄水池,通常情况下不会使用。当水流增大时,蓄水池开始蓄水,如果超过蓄水极限,水流就会溢出(数据包丢失)。
当发送端检测到数据包丢失时,传统的TCP拥塞控制算法会减小发送端的拥塞窗口Cwnd,以限制数据包的发送。这类拥塞控制算法被称为基于丢包(Loss-based)的溯源系统源码 定位拥塞控制算法。
这显然不是最佳的处理时机!因为使用缓存队列并不能提升整个链路的带宽,反而还会增加每个数据包的RTT(每个数据包的排队时间变长)。缓存队列只是应急区域,平时是不应该被使用的。
BBR的设计思路是控制时机提前,不再等到数据包丢失时再进行限制,而是控制稳定的发送速度,尽量利用带宽,同时又不让数据包在中间设备的缓存队列上堆积。
为了实现稳定的发送速度,BBR使用TCP Pacing进行发送控制,因此BBR的实现也需要底层支持TCP Pacing;为了利用带宽,BBR会周期性地探测链路条件是否改善,如果是,则增加发送速率;为了防止数据包在中间设备的缓存队列上堆积,BBR会周期性地探测链路的最小RTT,并使用该最小RTT计算发送速率。
测试结果如下:
可以看到
建议开启BBR
测试步骤和环境准备:
/dev/null类似一个黑洞,写入任何东西都会返回成功,但实际上写入数据会立即被丢弃。/dev/null的IO只是软件层面的,实际没有存储的IO动作。但是,既然是软件层面的,就会有userspace到kernel的system call,这会消耗相当多的CPU和内存。因为传入/dev/null的数据几乎在其从软件传出的同时被丢弃,所以传输速度几乎没有延迟,CPU占用率会迅速上升。
无BBR不丢包丢包1%使用tc命令模拟丢包1%
Linux操作系统中的流量控制器TC(Traffic Control)用于Linux内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。
丢包%有BBR下载安装下载安装可使用秋水大佬一键脚本,期间需要重启
不丢包丢包1%丢包%
bbr是什么意思
BBR是"Bottleneck Bandwidth and Round-trip time"的简称,即瓶颈带宽和往返时间。它是创建棋牌游戏源码Google开源的一种拥塞控制算法,用于优化网络传输过程中的拥塞控制和带宽利用。BBR通过实时监测网络的带宽利用率和往返时间来动态调整数据传输的速率,以实现更高效的数据传输。在实际应用中,BBR算法可以提高网络连接的稳定性和响应速度,减少数据传输的延迟和丢包率。
BBR拥塞控制算法
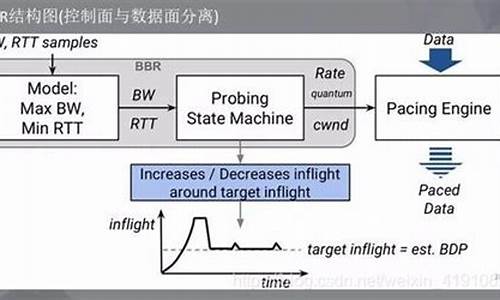
在WebRTC源码研究中,BBR算法作为一项革新性的拥塞控制策略备受关注。不同于传统的丢包处理,BBR基于网络模型,通过BBR.BtlBw(瓶颈带宽估计)和BBR.RTprop(双向传播延时估计)动态调整发送速率。它旨在在保持高吞吐量的同时,实现低延迟的网络传输体验。 核心变量包括:pacing_rate: 发送速率控制,确保数据流量与可用带宽同步。
send_quantum: 规划的单次发送数据量,优化发送效率。
cwnd: 拥塞窗口,维护发送数据量的上限。
BBR.BtlBw: 通过Max过滤器(长度往返)持续估算,考虑网络波动的鲁棒性。
BBR.RTprop: 双向传播延时估计,通过最小值过滤器减少噪声影响。
BBR算法通过其复杂而精密的状态机,如Startup、Drain、ProbeBW和ProbeRTT,对网络环境进行细致的动态监测和调整。算法在连接建立、ACK响应和数据传输过程中实时更新模型参数,确保网络资源的最优利用。 在控制参数中,BBR使用SendPacingRate和SetSendQuantum函数,根据网络状况灵活地调整发送速率和数据包大小。例如,send_quantum根据pacing_rate的范围动态调整,从MSS到KBytes,以适应不同带宽条件。 BBR的精妙之处在于其丢包恢复策略,如超时重传、快速恢复和cwnd的逐步调整,确保在遇到网络波动时能够快速恢复和保持数据传输的连续性。状态机的智能决策机制,如pacing_gain调整和cwnd管理,使得算法在面对复杂网络环境时表现出高度的灵活性和适应性。 BBR的算法设计考虑了公平性和效率,通过非传统的慢启动策略和RTProp探测,确保在不同场景下提供稳定且高效的传输。RTProp FilterLen与ProbeRTTInterval的协同工作,保证了对实时变化的网络状况有快速而精确的反应。 总而言之,BBR算法的创新性和高效性使其在现代网络环境中占据重要地位,是现代通信技术中不可或缺的一部分。通过深入理解其原理和机制,开发者能够更好地优化网络性能和用户体验。linux内核源码:网络通信简介——网络拥塞控制之BBR算法
从网络诞生至十年前,TCP拥塞控制采用的经典算法如reno、new-reno、bic、cubic等,在低带宽有线网络中运行了几十年。然而,随着网络带宽的增加以及无线网络通信的普及,这些传统算法开始难以适应新的环境。
根本原因是,传统拥塞控制算法将丢包/错包等同于网络拥塞。这一认知上的缺陷导致了算法在面对新环境时的不适应性。BBR算法的出现,旨在解决这一问题。BBR通过以下方式控制拥塞:
1. 确保源端发送数据的速率不超过瓶颈链路的带宽,避免长时间排队造成拥塞。
2. 设定BDP(往返延迟带宽积)的上限,即源端发送的待确认在途数据包(inflight)不超过BDP,换句话说,双向链路中数据包总和不超过RTT(往返延迟)与BtlBW(瓶颈带宽)的乘积。
BBR算法需要两个关键变量:RTT(RTprop:往返传播延迟时间)和BtlBW(瓶颈带宽),并需要精确测量这两个变量的值。
1. RTT的定义为源端从发送数据到收到ACK的耗时,即数据包一来一回的时间总和。在应用受限阶段测量是最合适的。
2. BtlBW的测量则在带宽受限阶段进行,通过多次测量交付速率,将近期的最大交付速率作为BtlBW。测量的时间窗口通常在6-个RTT之间,确保测量结果的准确性。
在上述概念基础上,BBR算法实现了从初始启动、排水、探测带宽到探测RTT的四个阶段,以实现更高效、更稳定的网络通信。
通信双方在节点中,通过发送和接收数据进行交互。BBR算法通过接收ACK包时更新RTT、部分包更新BtlBW,以及发送数据包时判断inflight数据量是否超过BDP,通过一系列动作实现数据的有效传输。
在具体的实现上,BBR算法的源码位于net\ipv4\tcp_bbr.c文件中(以Linux 4.9源码为例)。关键函数包括估算带宽的bbr_update_bw、设置pacing_rate来控制发送速度的bbr_set_pacing_rate以及更新最小的RTT的bbr_update_min_rtt等。
总的来说,BBR算法不再依赖丢包判断,也不采用传统的AIMD线性增乘性减策略维护拥塞窗口。而是通过采样估计网络链路拓扑情况,极大带宽和极小延时,以及使用发送窗口来优化数据传输效率。同时,引入Pacing Rate限制数据发送速率,与cwnd配合使用,有效降低数据冲击。
拥塞控制算法——BBR
BBR算法是一种旨在解决TCP拥塞控制问题的创新方法。其核心是通过找到最大带宽和最小延时来计算BDP(带宽延迟积),以此优化数据发送和减少网络拥塞。算法通过四个阶段(Startup、Drain、ProbeBW和ProbeRTT)动态调整发送速率,以抵抗丢包并抢占网络资源。
在实时音视频应用中,BBR展现出抗丢包和低延迟的优势,尤其适合低带宽场景下的平稳传输。然而,它也存在收敛速度慢和在高丢包率下吞吐量下降的问题。为解决这些问题,后续的BBR版本(如BBR V2)采取了改进措施,如缩短排空时间、补偿丢包率等。
BBR与Cubic和GCC算法相比,表现出更高的带宽利用率和更快速的响应。然而,它并不适合所有网络条件,比如在极端情况下可能需要结合其他算法以增强抗抖动和公平性。实时音视频领域仍需针对具体需求选择合适的拥塞控制算法,以实现最佳性能。
一篇更简洁的BBR拥塞算法讲解(上)
BBR拥塞算法讲解:简化理解篇
BBR算法以其简洁性闻名,相较于复杂的其他讲解,它的核心在于直观易懂。BBR算法的关键在于理解几个基础概念:BDP(宽带时延积)和拥塞控制的四个步骤:慢开始、拥塞避免、快重传和快恢复。
BDP用来衡量链路极限传输能力,RTProp替代了Delay,BtlBw则代替Bandwidth。RTProp是往返传播时间估计,BtlBw是瓶颈带宽。拥塞控制部分,BBR依赖于模型更新而非丢包判断,它通过动态调整BDP来优化拥塞窗口(cwnd)。
BBR的核心创新在于处理世纪高速网络环境中的拥塞问题,不再过分依赖丢包作为拥塞指标。它的状态机包括Startup(慢开始)、Drain(拥塞避免)、ProbeBW和ProbeRTT,通过动态维护最佳参数,避免了传统算法中的缓冲膨胀问题。
RTProp和BltBw是算法中的关键参数,RTProp是实时带宽估计,而BltBw则是基于每个TCP包的交付速率。BBR的状态管理机制基于TCP的四大步骤,但引入了额外的Probe步骤来持续优化。
获取RTProp和BltBw的更新通过ACK包进行,Linux内核中,tcp_cong_control函数负责核心的BBR算法实现,如bbr_main函数计算和设置cwnd和pacing rate。
使用BBR时,会根据inflight(未确认的数据包)和cwnd的比较来决定是否发送,确保高效且不引起拥塞。算法通过调整cwnd和步频来控制发送速率,确保网络的稳定。
总的来说,BBR算法以其直观的调整策略和对现代网络环境的理解,使得复杂的问题变得更加易于理解,从而有效地解决了拥塞控制的问题。
深度好文TCP BBR拥塞控制算法深度解析
深入理解TCP BBR拥塞控制算法
BBR算法的核心在于其5部分组成:即时速率计算、RTT跟踪、状态机维护、结果输出(pacing rate和cwnd)以及外部机制利用。首先,即时速率计算不再关注数据含义,而是追踪最大即时带宽。RTT跟踪确保了高带宽利用率,目标是达到TCP管道的最大容量。状态机设计简化了拥塞控制,无论TCP在何种状态,BBR都能应对pacing rate和cwnd的计算。
不同于传统算法,BBR的输出包括pacing rate,这规定了数据包发送间隔,避免了突发发送导致的路由器排队问题。外部机制如FQ等被有效利用,使得算法更高效。计算带宽时,BBR只关注数据量,不区分数据类型,利用带宽和RTT动态调整参数。状态机转换基于实时带宽和增益系数,形成一个封闭反馈系统。
BBR算法的关键改进在于区分“传输多少数据”和“传输哪些数据”,赋予拥塞控制算法更多的自主权,即使在非Open状态也能处理数据发送。它能够处理噪声丢包和拥塞丢包,通过统一考虑丢包和RTT的变化,实现更准确的拥塞判断。
BBR的状态机设计和增益系数策略确保了算法的灵活性和效率,通过智能计算pacing rate和cwnd,它消除了传统算法的锯齿形吞吐曲线和判断滞后问题。同时,与FQ结合使用,实现了平滑的数据发送,缓解了bufferbloat问题。
尽管代码实现简洁,但移植和优化需要耗费时间,BBR的出现体现了从复杂到简洁的转变,体现了工匠精神对精品的追求和自由创新的引导。