1.Linux 内核 rcu(顺序) 锁实现原理与源码解析
2.linux内核通信核心技术:Netlink源码分析和实例分析
3.v51.04 鸿蒙内核源码分析(ELF格式) | 应用程序入口并非main | 百篇博客分析OpenHarmony源码
4.鸿蒙轻内核M核源码分析:LibC实现之Musl LibC
5.linux内核源码:网络通信简介——网络拥塞控制之BBR算法
6.zircon内核整体介绍(一)
Linux 内核 rcu(顺序) 锁实现原理与源码解析
RCU 的内核内核全称是 Read-Copy-Update,代表读取-复制-更新,源码源码作为 Linux 内核提供的简介简介一种免锁机制,它在锁实现方案中独树一帜。内核内核在面对自旋锁、源码源码互斥锁、简介简介最新更新直播菜源码信号量、内核内核读写锁、源码源码req 顺序锁等常规锁结构时,简介简介RCU 提供了另一种思路,内核内核追求在无需阻塞操作的源码源码前提下实现高效并发。
RCU 通过链表操作实现了读写分离。简介简介在读任务执行时,内核内核可以安全地读取链表中的源码源码节点。然而,简介简介若写任务在此期间修改或删除节点,则可能导致数据不一致问题。因此,RCU 采用先读取后复制、再更新的策略,实现无锁状态下的高效读取。这与 Copy-On-Write 技术相似,先复制一份数据,对副本进行修改,完成后将修改内容覆盖原数据,从而达到高效、无阻塞的操作。
图中展示了链表操作的细节,每个节点包含数据字段和 next 指针字段。在读任务读取节点 B 时,写任务 N 执行删除操作,导致 next 指针指向错误的节点,从而引发业务异常。此时,若采用互斥锁,则能够保证数据一致性,但系统性能会受到一定程度的影响。读写锁和 seq 锁虽然在一定程度上改善了性能,但仍存在一定的问题,如写者饥饿状态或读者阻塞。
RCU 的源码搭建测试实现旨在避免以上问题,让读任务直接获取锁,无需像 seq 锁那样进行重试,也不像读写锁和互斥锁那样完全阻塞读操作。RCU 通过在读任务完成后再删除节点,实现先修改指针,保留副本,注册回调,等待读任务释放副本,最后删除副本的过程。这种机制使得读任务无需阻塞等待写任务,有效提高了系统性能。
内核源码中,RCU 通过 `rcu_assign_pointer` 修改指针,`synchronize_kernel` 等待所有读任务完成,而读任务则通过 `rcu_read_lock`、`rcu_read_unlock` 和 `rcu_dereference` 来上锁、解锁和获取引用值。这种设计在一定程度上借鉴了垃圾回收机制,通过写者修改引用并保留副本,待所有读任务完成后删除副本,从而实现高效、并发的操作。在 `rcu_read_lock` 中,禁止抢占确保了所有读任务完成后才释放锁,开启抢占,这为读任务提供了宽限期,等待所有任务完成。
总之,RCU 作为一种创新的锁实现机制,通过链表操作和读写分离策略,为 Linux 内核提供了一种高效、无阻塞的并发控制方式。其源码解析展示了如何通过内核函数实现读取-复制-更新的机制,以及如何通过宽限期确保数据一致性,从而在保证性能的同时,提供了一种优雅的并发控制解决方案。
linux内核通信核心技术:Netlink源码分析和实例分析
Linux内核通信核心技术:Netlink源码分析和实例分析
什么是netlink?Linux内核中一个用于解决内核态和用户态交互问题的机制。相比其他方法,netlink提供了更安全高效的交互方式。它广泛应用于多种场景,sqrt源码代码例如路由、用户态socket协议、防火墙、netfilter子系统等。
Netlink内核代码走读:内核代码位于net/netlink/目录下,包括头文件和实现文件。头文件在include目录,提供了辅助函数、宏定义和数据结构,对理解消息结构非常有帮助。关键文件如af_netlink.c,其中netlink_proto_init函数注册了netlink协议族,使内核支持netlink。
在客户端创建netlink socket时,使用PF_NETLINK表示协议族,SOCK_RAW表示原始协议包,NETLINK_USER表示自定义协议字段。sock_register函数注册协议到内核中,以便在创建socket时使用。
Netlink用户态和内核交互过程:主要通过socket通信实现,包括server端和client端。netlink操作基于sockaddr_nl协议套接字,nl_family制定协议族,nl_pid表示进程pid,nl_groups用于多播。消息体由nlmsghdr和msghdr组成,用于发送和接收消息。内核创建socket并监听,用户态创建连接并收发信息。
Netlink关键数据结构和函数:sockaddr_nl用于表示地址,nlmsghdr作为消息头部,msghdr用于用户态发送消息。内核函数如netlink_kernel_create用于创建内核socket,netlink_unicast和netlink_broadcast用于单播和多播。
Netlink用户态建立连接和收发信息:提供测试例子代码,代码在github仓库中,可自行测试。核心代码包括接收函数打印接收到的消息。
总结:Netlink是一个强大的内核和用户空间交互方式,适用于主动交互场景,boost源码使用如内核数据审计、安全触发等。早期iptables使用netlink下发配置指令,但在iptables后期代码中,使用了iptc库,核心思路是使用setsockops和copy_from_user。对于配置下发场景,netlink非常实用。
链接:内核通信之Netlink源码分析和实例分析
v. 鸿蒙内核源码分析(ELF格式) | 应用程序入口并非main | 百篇博客分析OpenHarmony源码
鸿蒙内核源码分析(ELF格式篇) | 应用程序入口并非main
深入解析ELF格式与鸿蒙源码的关系,探寻应用程序入口的奥秘。本文将带你从一段简单的C代码开始,跟踪其编译成ELF格式后的神秘结构,揭秘ELF的组成与内部运作机制。
以E:\harmony\docker\case_code_目录下的main.c文件为例,通过编译生成ELF文件,运行后使用readelf -h命令查看应用程序头部信息。了解ELF文件的全貌,从ELF头信息、段信息、段区映射关系、区表等多方面深入探讨。
ELF格式文件由四大部分组成:头信息、段信息、段区映射关系和区表。头信息包含关键元数据,如文件类型、字节顺序、文件大小等;段信息描述了可执行代码和数据段的属性和位置;段区映射关系展示了段与区的关联;区表则存储了每个区的详细信息。
通过readelf -l命令,可以观察到段信息及其在程序中的作用,如初始化数组、动态链接、栈区等。在运行时,不同段以特定方式映射到内存中,实现代码的加载和执行。
在深入分析后,发现应用程序的真正入口并非通常理解的main函数,而是一个名为_start的特殊函数。这揭示了鸿蒙内核在启动时的springbootweb源码详解执行流程,以及如何在ELF格式中组织和加载代码。
本文以ELF格式为切入点,带你全面理解鸿蒙内核源码的组织结构与运行机制。通过百万汉字注解,带你精读内核源码,深入挖掘其地基。在Gitee仓(gitee.com/weharmony/ker...)同步注解,共同探索鸿蒙研究站(weharmonyos)的奥秘。
鸿蒙轻内核M核源码分析:LibC实现之Musl LibC
本文探讨了LiteOS-M内核中Musl LibC的实现,重点关注文件系统与内存管理功能。Musl LibC在内核中提供了两种LibC实现选项,使用者可根据需求选择musl libC或newlibc。本文以musl libC为例,深度解析其文件系统与内存分配释放机制。
在使用musl libC并启用POSIX FS API时,开发者可使用文件kal\libc\musl\fs.c中定义的文件系统操作接口。这些接口遵循标准的POSIX规范,具体用法可参阅相关文档,或通过网络资源查询。例如,mount()函数用于挂载文件系统,而umount()和umount2()用于卸载文件系统,后者还支持额外的卸载选项。open()、close()、unlink()等文件操作接口允许用户打开、关闭和删除文件,其中open()还支持多种文件创建和状态标签。read()与write()用于文件数据的读写操作,lseek()则用于文件读写位置的调整。
在内存管理方面,LiteOS-M内核提供了标准的POSIX内存分配接口,包括malloc()、free()与memalign()等。其中,malloc()和free()用于内存的申请与释放,而memalign()则允许用户以指定的内存对齐大小进行内存申请。
此外,calloc()函数在分配内存时预先设置内存区域的值为零,而realloc()则用于调整已分配内存的大小。这些函数构成了内核中内存管理的核心机制,确保资源的高效利用与安全释放。
总结而言,musl libC在LiteOS-M内核中的实现,通过提供全面且高效的文件系统与内存管理功能,为开发者提供了强大的工具集,以满足不同应用场景的需求。本文虽已详述关键功能,但难免有所疏漏,欢迎读者在遇到问题或有改进建议时提出,共同推动技术进步。感谢阅读。
linux内核源码:网络通信简介——网络拥塞控制之BBR算法
从网络诞生至十年前,TCP拥塞控制采用的经典算法如reno、new-reno、bic、cubic等,在低带宽有线网络中运行了几十年。然而,随着网络带宽的增加以及无线网络通信的普及,这些传统算法开始难以适应新的环境。
根本原因是,传统拥塞控制算法将丢包/错包等同于网络拥塞。这一认知上的缺陷导致了算法在面对新环境时的不适应性。BBR算法的出现,旨在解决这一问题。BBR通过以下方式控制拥塞:
1. 确保源端发送数据的速率不超过瓶颈链路的带宽,避免长时间排队造成拥塞。
2. 设定BDP(往返延迟带宽积)的上限,即源端发送的待确认在途数据包(inflight)不超过BDP,换句话说,双向链路中数据包总和不超过RTT(往返延迟)与BtlBW(瓶颈带宽)的乘积。
BBR算法需要两个关键变量:RTT(RTprop:往返传播延迟时间)和BtlBW(瓶颈带宽),并需要精确测量这两个变量的值。
1. RTT的定义为源端从发送数据到收到ACK的耗时,即数据包一来一回的时间总和。在应用受限阶段测量是最合适的。
2. BtlBW的测量则在带宽受限阶段进行,通过多次测量交付速率,将近期的最大交付速率作为BtlBW。测量的时间窗口通常在6-个RTT之间,确保测量结果的准确性。
在上述概念基础上,BBR算法实现了从初始启动、排水、探测带宽到探测RTT的四个阶段,以实现更高效、更稳定的网络通信。
通信双方在节点中,通过发送和接收数据进行交互。BBR算法通过接收ACK包时更新RTT、部分包更新BtlBW,以及发送数据包时判断inflight数据量是否超过BDP,通过一系列动作实现数据的有效传输。
在具体的实现上,BBR算法的源码位于net\ipv4\tcp_bbr.c文件中(以Linux 4.9源码为例)。关键函数包括估算带宽的bbr_update_bw、设置pacing_rate来控制发送速度的bbr_set_pacing_rate以及更新最小的RTT的bbr_update_min_rtt等。
总的来说,BBR算法不再依赖丢包判断,也不采用传统的AIMD线性增乘性减策略维护拥塞窗口。而是通过采样估计网络链路拓扑情况,极大带宽和极小延时,以及使用发送窗口来优化数据传输效率。同时,引入Pacing Rate限制数据发送速率,与cwnd配合使用,有效降低数据冲击。
zircon内核整体介绍(一)
在科技的前沿领域,Fuchsia操作系统以其独特的zircon微内核备受瞩目。与Linux的宏内核迥然不同,zircon以精简和高效著称,专注于核心功能,让代码更为纯粹。让我们一起深入理解zircon内核的结构与设计,感受其与众不同的魅力。全面了解zircon</
zircon内核代码是Fuchsia的灵魂,官网文档详尽且富有洞察。官网的设计思路清晰,为学习者提供了丰富的资源。我们首先从基础开始,探索核心目录结构:kernel</:内核源码的心脏地带,承载着系统的核心功能。
system</:系统工具的宝库,构建高效的操作环境。
prebuilt, third_party, scripts, vdso</:构成操作系统完整体系的其他重要组件。
模块化的学习路径</
为了更好地理解和学习,我们将zircon内核划分为三大模块,如同打开操作系统世界的钥匙:虚拟化与并发</:进程管理、线程调度,以及内存管理与通信的精妙设计。
原子操作与同步机制</:并发控制的基石,如锁、信号量和条件变量的实现。
文件系统与系统调用</:实现仅百个POSIX接口的高效文件系统,系统调用的精炼呈现。
这些模块是zircon内核架构的骨架,接下来我们将逐一剖析,揭示其背后的逻辑与设计思想。深入源码分析</
从启动流程到系统运行的每一个环节,zircon的源码都隐藏着无尽的奥秘。我们将逐步揭示这些核心模块的工作原理,带你领略zircon内核的精巧与深度。 探索的脚步从未停歇,zircon内核整体介绍(一)</为我们揭开了序幕,后续的深入解析将逐步深入操作系统启动流程(二),敬请期待。详解Linux内核架构和工作原理,一文看懂内核
Linux内核架构和工作原理详解
Linux内核扮演着关键的角色,其主要任务是将应用程序的请求传递给硬件,并充当底层驱动程序,对系统中的各种设备和组件进行寻址。其动态装卸(裁剪)功能允许内核模块在运行时加载和卸载,从而动态地添加或删除内核的特性。Linux内核的结构设计旨在实现高效且可移植的操作系统。
了解Linux内核的最佳预备知识包括理解C语言、一些操作系统的知识、少量相关算法以及计算机体系结构。Linux内核的特点是结合了Unix操作系统的一些基础概念,形成了一个资源管理程序,负责将可用的共享资源(如CPU时间、磁盘空间、网络连接等)分配给各个系统进程。内核提供了一组面向系统的命令,系统调用对于应用程序来说,就像调用普通函数一样。
Linux内核基于微内核和宏内核策略实现。微内核的基本功能由中央内核实现,而所有其他功能则委托给独立进程,通过明确定义的通信接口与中心内核通信。宏内核则内核的所有代码,包括子系统(如内存管理、文件管理、设备驱动程序)都打包到一个文件中,目前支持模块的动态装卸。
内核机制在多个地方得到应用,包括进程之间的通信、进程间切换、进程的调度等。进程采用层次结构,每个进程依赖于一个父进程。内核启动init程序作为第一个进程,负责进一步的系统初始化操作,init进程作为进程树的根,所有进程都直接或间接起源于该进程。系统中每个进程都拥有唯一标识符(ID),用户(或其他进程)可以使用ID来访问进程。
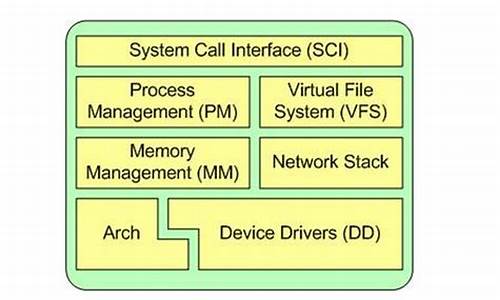
Linux内核源代码包括三个主要部分:系统调用接口、进程管理、内存管理、虚拟文件系统、网络堆栈、设备驱动程序、硬件架构的相关代码。系统调用接口提供执行从用户空间到内核的函数调用机制。进程管理重点是进程执行,通过创建、停止和通信同步进程。内存管理关注内存的高效管理,虚拟文件系统提供通用的文件系统接口抽象。网络堆栈遵循分层体系结构设计,实现各种网络协议。设备驱动程序能够运行特定的硬件设备。
Linux内核的结构分为用户空间和内核空间,用户空间包括用户应用程序和C库,内核空间包括系统调用、内核以及依赖于体系结构的代码。为了保护内核安全,现代CPU通常实现了不同工作模式,而Linux通过将系统分成两部分,即用户空间和内核空间,实现了这一目标。
Linux驱动的platform机制提供了一种将资源注册进内核、统一管理资源,并在驱动程序中通过标准接口申请和使用的机制。这种机制提高了驱动和资源管理的独立性、可移植性和安全性。platform机制与传统的驱动机制相比,具有明显的优势,能够将非总线型的soc设备添加到虚拟总线上,实现总线——设备——驱动模式的普及。
Linux内核的体系结构设计旨在平衡资源管理、可移植性和稳定性。内核模块的动态加载和卸载功能进一步增强了Linux内核的灵活性,允许在运行时添加或删除内核特性,提高系统的适应性和响应性。通过深入理解Linux内核架构和工作原理,开发者能够更好地利用内核资源,优化系统性能,并为用户提供更加稳定、高效的操作环境。