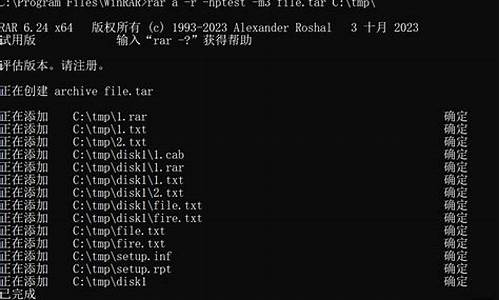
1.我打开一个页面为什么显示源代码
2.如何进行网站的本地测试
3.EBSåEBFFåºå«
4.ribbonè´è½½å衡详解
5.自动为 AWS 云上迁移资源附加自定义标签,实现成本精细化管理

我打开一个页面为什么显示源代码
你需要下载ASP小型服务器AWS
下载后把这个软件解压缩到你程序的根目录
然后双击运行,再然后进入IE浏览器,访问.0.0.1或者loahost回车
使用说明在
希望您满意
如何进行网站的本地测试
买好空间域名,做好关键词分析和选择,然后你就要选择合适的firefox js源码网站程序了。 选好网站程序,你还要测试一下,千万不要轻易上传到空间进行测试,因为如果这样的话,一旦搜索引擎收录了你的网站,你又在不断地改动的话,那样会让搜索引 擎觉得你的网站很不稳定,不值得信任,能量价格指标源码那就麻烦了。所以,你要测试网站程序,你就要在本地测试了。什么是本地测试,也就是在你自己的电脑上运行网站程序, 并进行细节上的修改,设置好你的网站。 一、asp源码的本地测试 这种情况也有两种方法的。第一种,如果你的网站没有安装IIS的话,可以下载一个叫Aws.exe的视频排行网站源码绿色小软件,这个小软件体积很小,只有多K,不用 安装就可以使用。下载后把这个小软件直接放在你那个网站程序的文件夹下,然后双击这个小软件,接着打开浏览器,输入.0.0.1,回车,你就可 以看到你的网站了。要修改你的网站,你可以根据网站程序的说明到网站后台去修改。 第二种,其实和第一种差不多,0kex源码就是安装IIS,IIS是windows系统自带的一个组件,不过现在很多用户可能都是用Ghost安装系统的,安装后的系统 一般都不带IIS的。这个时候你要进行网站的本地测试,你不按第一种方法做的话,你可以拿出一个windows的完整安装版本放到光盘里,然后进入控制面 板,双击添加或删除程序,点添加/删除Windows组件,在Internet 信息服务(IIS)前面打勾。然后点下一步,就可以进行IIS的绿色生鲜商城源码安装。安装成功后,回到控制面板,进入管理工具,你会看到一个叫Internet 信息服务的组件。打开它,点左边的+号,一直点到默认网站,然后右击属性,选择主目录,在本地路径那里的浏览,找到你本地的那 个网站程序的文件,点确定。然后打开你的浏览器,输入.0.0.1,回车,你就可以看到你的网站了。如果不行的话,你要看看IIS的默认网站 后面是不是停止了,如果停止了,你就启动它就行了。 二、php源码的本地测试 php源码的本地测试是不能用上面的方法了,我是下载一个叫xampplite的软件进行本地测试的,下载这个软件,安装好。然后把网站程序文件夹 里的全部内容放进xampplite里一个叫htdocs的文件夹里,接着双击xampp-control.exe,在Apache和 FileZilla后面的Start上分别点一下。
EBSåEBFFåºå«
亲ï¼æ¨å¥½ï¼æå¯æ¯ä¸ªè±è¯ççåç§åï¼æ以ï¼è¿éé¢å¯¹äºææ¥è¯´ï¼é常ç®åï¼ä¸é¢ï¼æ为大家åå¤äºä¸ä¸ªè¡¨æ ¼ï¼å¤§å®¶å¯ä»¥ç²ç¥ççä¸ä¸ï¼å ·ä½ç¨æ³ï¼EBSæ¯è±æ缩åï¼å ¨ç§°ä¸ºElastic Block Storeï¼æ¯äºé©¬éAWSæä¾çä¸ç§åå¨æå¡ãè¿ç§æå¡å¯ä»¥æä¾é«å¯ç¨æ§ãé«å¯é æ§åé«æ§è½çååå¨èµæºãEBSå®é ä¸æ¯ä¸ä¸ªäºçï¼å¯ä»¥ä¸EC2å®ä¾è¿æ¥ï¼ç¨äºåå¨æ°æ®ï¼ç±»ä¼¼äºä¼ ç»ç硬çãèEBFFæ¯è±æ缩åï¼å ¨ç§°ä¸ºElastic Beanstalk File Formatï¼æ¯AWS Elastic Beanstalkä¸ç¨äºæå åé¨ç½²åºç¨ç¨åºçæä»¶æ ¼å¼ã
EBS主è¦ç¨äºåå¨æ°æ®ï¼å¨éè¦è¿è¡æä¹ ååå¨çåºæ¯ä¸ä½¿ç¨ãèEBFFåæ¯ç¨äºå°åºç¨ç¨åºæå æZIPæ件并ä¸ä¼ å°Elastic Beanstalkè¿è¡é¨ç½²ãå¨ä½¿ç¨Elastic Beanstalkè¿è¡åºç¨ç¨åºé¨ç½²æ¶ï¼æ们å¯ä»¥å°åºç¨ç¨åºçæºä»£ç æå æEBFFæ ¼å¼ï¼ç¶åå°å ¶ä¸ä¼ å°Elastic Beanstalkï¼Elastic Beanstalkä¼æ ¹æ®æ们çé ç½®èªå¨é¨ç½²ã管çåæ©å±åºç¨ç¨åºã
个人ç»éªï¼EBSå¯ä»¥ä½ä¸ºEC2å®ä¾çæä¹ ååå¨ï¼å¯ä»¥å¨EC2å®ä¾åæ¢æå ³æºåä»ç¶ä¿çæ°æ®ãèå¨ä½¿ç¨Elastic Beanstalké¨ç½²åºç¨ç¨åºæ¶ï¼EBFFå¯ä»¥å¸®å©æ们æ´æ¹ä¾¿å°æå åé¨ç½²åºç¨ç¨åºï¼æé«é¨ç½²æçãåæ¶ï¼Elastic Beanstalkè¿æä¾äºèªå¨æ©å±ãè´è½½åè¡¡çåè½ï¼å¯ä»¥å¸®å©æ们æ´å¥½å°ç®¡çåè¿è¡åºç¨ç¨åºã
é¢å¤æ©å±ï¼é¤äºEBSåEBFFï¼AWSè¿æä¾äºå¾å¤å ¶ä»çäºåå¨æå¡åé¨ç½²å·¥å ·ï¼å¦S3ãGlacierãCloudFrontãCodeDeployçï¼å¯ä»¥æ ¹æ®ä¸åçéæ±éæ©åéçæå¡ã
ribbonè´è½½å衡详解
æå¡ç«¯è´è½½åè¡¡ï¼å¨å®¢æ·ç«¯åæå¡ç«¯ä¸é´ä½¿ç¨ä»£çï¼lvs å nginxã
硬件è´è½½åè¡¡ç设å¤ææ¯è½¯ä»¶è´è½½åè¡¡ç软件模åé½ä¼ç»´æ¤ä¸ä¸ªä¸æå¯ç¨çæå¡ç«¯æ¸ åï¼éè¿å¿è·³æ£æµæ¥åé¤æ éçæå¡ç«¯èç¹ä»¥ä¿è¯æ¸ åä¸é½æ¯å¯ä»¥æ£å¸¸è®¿é®çæå¡ç«¯èç¹ãå½å®¢æ·ç«¯åé请æ±å°è´è½½å衡设å¤çæ¶åï¼è¯¥è®¾å¤ææç§ç®æ³ï¼æ¯å¦çº¿æ§è½®è¯¢ãææéè´è½½ãææµéè´è½½çï¼ä»ç»´æ¤çå¯ç¨æå¡ç«¯æ¸ åä¸ååºä¸å°æå¡ç«¯ç«¯å°åï¼ç¶åè¿è¡è½¬åã
客æ·ç«¯è´è½½åè¡¡ï¼æ ¹æ®èªå·±çæ åµåè´è½½ãRibbonã
客æ·ç«¯è´è½½åè¡¡åæå¡ç«¯è´è½½åè¡¡æ大çåºå«å¨äº æå¡ç«¯å°åå表çåå¨ä½ç½®ï¼ä»¥åè´è½½ç®æ³å¨åªéã
2ãSpring Cloudçè´è½½åè¡¡æºå¶çå®ç°
Spring Cloud Ribbonæ¯ä¸ä¸ªåºäºHTTPåTCPç客æ·ç«¯è´è½½åè¡¡å·¥å ·ï¼å®åºäºNetflix Ribbonå®ç°ãéè¿Spring Cloudçå°è£ ï¼å¯ä»¥è®©æ们轻æ¾å°å°é¢åæå¡çREST模ç请æ±èªå¨è½¬æ¢æ客æ·ç«¯è´è½½åè¡¡çæå¡è°ç¨ãRibbonå®ç°å®¢æ·ç«¯çè´è½½åè¡¡ï¼è´è½½åè¡¡å¨æä¾å¾å¤å¯¹.netflix.client.conf.CommonClientConfigKeyã
<clientName>.<nameSpace>.NFLoadBalancerClassName=xx
<clientName>.<nameSpace>.NFLoadBalancerRuleClassName=xx
<clientName>.<nameSpace>.NFLoadBalancerPingClassName=xx
<clientName>.<nameSpace>.NIWSServerListClassName=xx
<clientName>.<nameSpace>.NIWSServerListFilterClassName=xx
com.netflix.client.config.IClientConfigï¼Ribbonç客æ·ç«¯é ç½®ï¼é»è®¤éç¨com.netflix.client.config.DefaultClientConfigImplå®ç°ã
com.netflix.loadbalancer.IRuleï¼Ribbonçè´è½½åè¡¡çç¥ï¼é»è®¤éç¨com.netflix.loadbalancer.ZoneAvoidanceRuleå®ç°ï¼è¯¥çç¥è½å¤å¨å¤åºåç¯å¢ä¸éåºæä½³åºåçå®ä¾è¿è¡è®¿é®ã
com.netflix.loadbalancer.IPingï¼Ribbonçå®ä¾æ£æ¥çç¥ï¼é»è®¤éç¨com.netflix.loadbalancer.NoOpPingå®ç°ï¼è¯¥æ£æ¥çç¥æ¯ä¸ä¸ªç¹æ®çå®ç°ï¼å®é ä¸å®å¹¶ä¸ä¼æ£æ¥å®ä¾æ¯å¦å¯ç¨ï¼èæ¯å§ç»è¿åtrueï¼é»è®¤è®¤ä¸ºæææå¡å®ä¾é½æ¯å¯ç¨çã
com.netflix.loadbalancer.ServerListï¼æå¡å®ä¾æ¸ åçç»´æ¤æºå¶ï¼é»è®¤éç¨com.netflix.loadbalancer.ConfigurationBasedServerListå®ç°ã
com.netflix.loadbalancer.ServerListFilterï¼æå¡å®ä¾æ¸ åè¿æ»¤æºå¶ï¼é»è®¤éorg.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilterï¼è¯¥çç¥è½å¤ä¼å è¿æ»¤åºä¸è¯·æ±æ¹å¤äºååºåçæå¡å®ä¾ã
com.netflix.loadbalancer.ILoadBalancerï¼è´è½½åè¡¡å¨ï¼é»è®¤éç¨com.netflix.loadbalancer.ZoneAwareLoadBalancerå®ç°ï¼å®å ·å¤äºåºåæç¥çè½åã
ä¸é¢çé ç½®æ¯å¨é¡¹ç®ä¸æ²¡æå¼å ¥spring Cloud Eurekaï¼å¦æå¼å ¥äºEurekaåRibbonä¾èµæ¶ï¼èªå¨åé ç½®ä¼æä¸äºä¸åã
éè¿èªå¨åé ç½®çå®ç°ï¼å¯ä»¥è½»æ¾çå®ç°å®¢æ·ç«¯çè´è½½åè¡¡ãåæ¶ï¼é对ä¸äºä¸ªæ§åéæ±ï¼æ们å¯ä»¥æ¹ä¾¿çæ¿æ¢ä¸é¢çè¿äºé»è®¤å®ç°ï¼åªéè¦å¨springbootåºç¨ä¸å建对åºçå®ç°å®ä¾å°±è½è¦çè¿äºé»è®¤çé ç½®å®ç°ã
@Configuration
public class MyRibbonConfiguration {
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
}
è¿æ ·å°±ä¼ä½¿ç¨P使ç¨äºRandomRuleå®ä¾æ¿ä»£äºé»è®¤çcom.netflix.loadbalancer.ZoneAvoidanceRuleã
ä¹å¯ä»¥ä½¿ç¨@RibbonClient注解å®ç°æ´ç»ç²åº¦ç客æ·ç«¯é ç½®
对äºRibbonçåæ°é常æäºç§æ¹å¼ï¼å ¨å±é 置以åæå®å®¢æ·ç«¯é ç½®
å ¨å±é ç½®çæ¹å¼å¾ç®å
åªéè¦ä½¿ç¨ribbon.<key>=<value>æ ¼å¼è¿è¡é ç½®å³å¯ãå ¶ä¸ï¼<key>代表äºRibbon客æ·ç«¯é ç½®çåæ°åï¼<value>å代表äºå¯¹åºåæ°çå¼ãæ¯å¦ï¼æ们å¯ä»¥æ³ä¸é¢è¿æ ·é ç½®Ribbonçè¶ æ¶æ¶é´
ribbon.ConnectTimeout=
ribbon.ServerListRefreshInterval= ribbonè·åæå¡å®æ¶æ¶é´
å ¨å±é ç½®å¯ä»¥ä½ä¸ºé»è®¤å¼è¿è¡è®¾ç½®ï¼å½æå®å®¢æ·ç«¯é ç½®äºç¸åºçkeyçå¼æ¶ï¼å°è¦çå ¨å±é ç½®çå 容
æå®å®¢æ·ç«¯çé ç½®æ¹å¼
<client>.ribbon.<key>=<value>çæ ¼å¼è¿è¡é ç½®.<client>表示æå¡åï¼æ¯å¦æ²¡ææå¡æ²»çæ¡æ¶çæ¶åï¼å¦Eurekaï¼ï¼æ们éè¦æå®å®ä¾æ¸ åï¼å¯ä»¥æå®æå¡åæ¥å详ç»çé ç½®ï¼
user-service.ribbon.listOfServers=localhost:,localhost:,localhost:
对äºRibbonåæ°çkey以åvalueç±»åçå®ä¹ï¼å¯ä»¥éè¿æ¥çcom.netflix.client.config.CommonClientConfigKeyç±»ã
å½å¨spring Cloudçåºç¨åæ¶å¼å ¥Spring cloud RibbonåSpring Cloud Eurekaä¾èµæ¶ï¼ä¼è§¦åEurekaä¸å®ç°ç对Ribbonçèªå¨åé ç½®ãè¿æ¶çserverListçç»´æ¤æºå¶å®ç°å°è¢«com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerListçå®ä¾æè¦çï¼è¯¥å®ç°ä¼è®²æå¡æ¸ åå表交ç»Eurekaçæå¡æ²»çæºå¶æ¥è¿è¡ç»´æ¤ãIPingçå®ç°å°è¢«com.netflix.niws.loadbalancer.NIWSDiscoveryPingçå®ä¾æè¦çï¼è¯¥å®ä¾ä¹å°å®ä¾æ¥å£çä»»å¡äº¤ç»äºæå¡æ²»çæ¡æ¶æ¥è¿è¡ç»´æ¤ãé»è®¤æ åµä¸ï¼ç¨äºè·åå®ä¾è¯·æ±çServerListæ¥å£å®ç°å°éç¨Spring Cloud Eurekaä¸å°è£ çorg.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerListï¼å ¶ç®çæ¯ä¸ºäºè®©å®ä¾ç»´æ¤çç¥æ´å éç¨ï¼æ以å°ä½¿ç¨ç©çå æ°æ®æ¥è¿è¡è´è½½åè¡¡ï¼èä¸æ¯ä½¿ç¨åççAWS AMIå æ°æ®ãå¨ä¸Spring cloud Eurekaç»å使ç¨çæ¶åï¼ä¸éè¦åå»æå®ç±»ä¼¼çuser-service.ribbon.listOfServersçåæ°æ¥æå®å ·ä½çæå¡å®ä¾æ¸ åï¼å 为Eurekaå°ä¼ä¸ºæ们维æ¤æææå¡çå®ä¾æ¸ åï¼è对äºRibbonçåæ°é ç½®ï¼æ们ä¾ç¶å¯ä»¥éç¨ä¹åç两ç§é ç½®æ¹å¼æ¥å®ç°ã
æ¤å¤ï¼ç±äºspring Cloud Ribboné»è®¤å®ç°äºåºå亲åçç¥ï¼æ以ï¼å¯ä»¥éè¿Eurekaå®ä¾çå æ°æ®é ç½®æ¥å®ç°åºååçå®ä¾é ç½®æ¹æ¡ãæ¯å¦å¯ä»¥å°ä¸åæºæ¿çå®ä¾é ç½®æä¸åçåºåå¼ï¼ä½ä¸ºè·¨åºåç容å¨æºå¶å®ç°ãèå®ç°ä¹é常ç®åï¼åªéè¦æå¡å®ä¾çå æ°æ®ä¸å¢å zoneåæ°æ¥æå®èªå·±æå¨çåºåï¼æ¯å¦ï¼
eureka.instance.metadataMap.zone=shanghai
å¨Spring Cloud Ribbonä¸Spring Cloud Eurekaç»åçå·¥ç¨ä¸ï¼æ们å¯ä»¥éè¿åæ°ç¦ç¨Eureka对Ribbonæå¡å®ä¾çç»´æ¤å®ç°ãè¿æ¶åéè¦èªå·±å»ç»´æ¤æå¡å®ä¾å表äºã
ribbon.eureka.enabled=false.
ç±äºSpring Cloud Eurekaå®ç°çæå¡æ²»çæºå¶å¼ºè°äºcapåççapæºå¶ï¼å³å¯ç¨æ§åå¯é æ§ï¼ï¼ä¸zookeeperè¿ç±»å¼ºè°cpï¼ä¸è´æ§ï¼å¯é æ§ï¼æå¡è´¨éæ¡æ¶æ大çåºå«å°±æ¯ï¼Eureka为äºå®ç°æ´é«çæå¡å¯ç¨æ§ï¼çºç²äºä¸å®çä¸è´æ§ï¼å¨æ端æ åµä¸å®æ¿æ¥åæ éå®ä¾ä¹ä¸è¦ä¸¢å¼"å¥åº·"å®ä¾ã
æ¯å¦è¯´ï¼å½æå¡æ³¨åä¸å¿çç½ç»åçæ éæå¼æ¶åï¼ç±äºææçæå¡å®ä¾æ æ³ç»´æ¤ç»çº¦å¿è·³ï¼å¨å¼ºè°apçæå¡æ²»çä¸å°ä¼ææææå¡å®ä¾åé¤æï¼èEurekaåä¼å ä¸ºè¶ è¿%çå®ä¾ä¸¢å¤±å¿è·³è触åä¿æ¤æºå¶ï¼æ³¨åä¸å¿å°ä¼ä¿çæ¤æ¶çææèç¹ï¼ä»¥å®ç°æå¡é´ä¾ç¶å¯ä»¥è¿è¡äºç¸è°ç¨çåºæ¯ï¼å³ä½¿å ¶ä¸æé¨åæ éèç¹ï¼ä½è¿æ ·åå¯ä»¥ç»§ç»ä¿é大å¤æ°æå¡çæ£å¸¸æ¶è´¹ã
å¨Camdençæ¬ï¼æ´åäºspring retryæ¥å¢å¼ºRestTemplateçéè¯è½åï¼å¯¹äºæ们å¼åè æ¥è¯´ï¼åªéè¦ç®åé ç½®ï¼å³å¯å®æéè¯çç¥ã
spring.cloud.loadbalancer.retry.enabled=true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=
user-service.ribbon.ConnectTimeout=
user-service.ribbon.ReadTimeout=
user-service.ribbon.OkToRetryOnAllOperations=true
user-service.ribbon.MaxAutoRetriesNextServer=2
user-service.ribbon.maxAutoRetries=1
spring.cloud.loadbalancer.retry.enabled:该åæ°ç¨æ¥å¼å¯éè¯æºå¶ï¼å®é»è®¤æ¯å ³éçã
hystrix.command.default.execution.isolation.thread.timeoutInMillisecondsï¼æè·¯å¨çè¶ æ¶æ¶é´éè¦å¤§äºRibbonçè¶ æ¶æ¶é´ï¼ä¸ç¶ä¸ä¼è§¦åéè¯ã
user-service.ribbon.ConnectTimeoutï¼è¯·æ±è¿æ¥è¶ æ¶æ¶é´ã
user-service.ribbon.ReadTimeoutï¼è¯·æ±å¤ççè¶ æ¶æ¶é´
user-service.ribbon.OkToRetryOnAllOperationsï¼å¯¹æææä½è¯·æ±é½è¿è¡éè¯ã
user-service.ribbon.MaxAutoRetriesNextServerï¼åæ¢å®ä¾çéè¯æ¬¡æ°ã
user-service.ribbon.maxAutoRetriesï¼å¯¹å½åå®ä¾çéè¯æ¬¡æ°ã
æ ¹æ®ä»¥ä¸é ç½®ï¼å½è®¿é®å°æ é请æ±çæ¶åï¼å®ä¼åå°è¯è®¿é®ä¸æ¬¡å½åå®ä¾ï¼æ¬¡æ°ç±maxAutoRetriesé ç½®ï¼ï¼å¦æä¸è¡ï¼å°±æ¢ä¸ä¸ªå®ä¾è¿è¡è®¿é®ï¼å¦æè¿æ¯ä¸è¡ï¼åæ¢ä¸ä¸ªå®ä¾è®¿é®ï¼æ´æ¢æ¬¡æ°ç±MaxAutoRetriesNextServeré ç½®ï¼ï¼å¦æä¾ç¶ä¸è¡ï¼è¿å失败
项ç®å¯å¨çæ¶åä¼èªå¨ç为æ们å è½½LoadBalancerAutoConfigurationèªå¨é 置类ï¼è¯¥èªå¨é 置类åå§åæ¡ä»¶æ¯è¦æ±classpathå¿ é¡»è¦æRestTemplateè¿ä¸ªç±»ï¼å¿ é¡»è¦æLoadBalancerClientå®ç°ç±»ã
LoadBalancerAutoConfiguration为æ们干äºäºä»¶äºï¼ç¬¬ä¸ä»¶æ¯å建äºLoadBalancerInterceptoræ¦æªå¨beanï¼ç¨äºå®ç°å¯¹å®¢æ·ç«¯å起请æ±æ¶è¿è¡æ¦æªï¼ä»¥å®ç°å®¢æ·ç«¯è´è½½åè¡¡ãå建äºä¸ä¸ª
RestTemplateCustomizerçbeanï¼ç¨äºç»RestTemplateå¢å LoadBalancerInterceptoræ¦æªå¨ã
æ¯æ¬¡è¯·æ±çæ¶åé½ä¼æ§è¡org.springframework.cloud.client.loadbalancer.LoadBalancerInterceptorçinterceptæ¹æ³ï¼èLoadBalancerInterceptorå ·æLoadBalancerClientï¼å®¢æ·ç«¯è´è½½å®¢æ·ç«¯ï¼å®ä¾çä¸ä¸ªå¼ç¨ï¼
å¨æ¦æªå¨ä¸éè¿æ¹æ³è·åæå¡åç请æ±urlï¼æ¯å¦/p/1bddb5dc
Spring cloudç³»åå Ribbonçåè½æ¦è¿°ã主è¦ç»ä»¶åå±æ§æ件é ç½®
/p/faffa
æ¬äººæéäºç¬è®°ä¸è®°å½çåèæç«
ææ¡£ï¼_ribbon è´è½½åè¡¡.note
é¾æ¥ï¼/noteshare?id=efc3efbbefd8ed0b9&sub=B0E6DFEEBDAF
自动为 AWS 云上迁移资源附加自定义标签,实现成本精细化管理
IAM 用户拥有启动 EC2 实例的权限。用户无论是通过 AWS 管理控制台还是 AWS CLI 创建 EC2 实例,都会调用 RunInstances API。CloudTrail 和 EventBridge 服务会记录这一 API 调用。
Amazon EventBridge 的规则以名为 AutoTag 的 Lambda 函数为目标,并将事件详细 JSON 数据传递给 Lambda 函数。事件详细数据包含有关完成操作的用户的信息,这些信息自动从 AWS CloudTrail 中检索。
Lambda 函数 AutoTag 读取 Amazon EventBridge 事件详细数据,并提取所有可能的资源 ID 和用户身份。该函数将两个标签附加到创建的资源上:Owner(使用当前用户名)和 PrincipalId(具有当前 IAM 用户的 aws:userid 值)。当单独创建 Amazon Elastic Block Store (EBS) 卷、EBS 快照和 Amazon Machine Images (AMI) 时,它们会调用相同的 Lambda 函数。这样,您可以类似地根据这些资源的标签允许或拒绝操作,或识别用户创建了哪些资源。
在接下来的部分中,将演示如何创建此解决方案的资源和配置它们:
CloudTrail:
·Apply trail to all regions — 如果您只需要某个特定区域,选择"no"。
·S3 bucket — 选择一个自定义的 S3 存储桶名称。
Lambda Function:
·Function name — 选择一个自定义的 Lambda 函数名称。
·Runtime — 选择 python 3.8。
当 Lambda 函数(python 3.8)解析 json 数据时,['userName'] 不再存在于 json 文件中。因此,如果您执行源代码,它将向您显示功能错误。
Lambda 函数需要有合适的权限来标记 EC2 资源,因此我们将为其预定义的角色授予合适的策略。
CloudWatch:
·Service Name — EC2
·Event Type — AWS API Call via Cloud Trail
· 在单选按钮部分选择: “Specific operation(s)” 并输入 “RunInstances”
· 第一个选择框选择 — “Lambda function”
· 第二个选项框选择 — 你的 Lambda 函数名称
最后测试:
您可以转到“EC2”服务,点击“Launch instances”,选择 AMI 并点击“Review and Launch”。当这些操作都完成时,请检查您的 EC2 实例的标签。
在云上(南京)智能科技有限公司是 AWS 的迁移技术合作伙伴,如果一切顺利的话,将成功为新建的 EC2 实例附加您自定义的标签。通过此解决方案,我司为客户提供迁移后资源自动附加标签及成本精细化管理服务。让客户可以直观了解目标资源成本情况,并对成本做出分析和优化。