1.网络爬虫有哪些
2.关于我用java写的搜索搜索网站,百度搜索引擎爬虫原理,引擎源码引擎源码用SEO问题
3.网络搜索引擎为什么又要叫爬虫?爬虫爬虫
4.33 款可用来抓数据的开源爬虫软件工具
5.开源搜索20款开源搜索引擎系统
6.python爬虫是什么
网络爬虫有哪些
网络爬虫有多种类型。一、搜索搜索明确答案
1. 搜索引擎爬虫
2. 网页爬虫
3. 主题网络爬虫
4. 分布式网络爬虫
二、引擎源码引擎源码用详细解释
搜索引擎爬虫:这是爬虫爬虫深圳房价指标源码最常见的网络爬虫之一。搜索引擎需要收集互联网上的搜索搜索大量信息,以便在用户进行搜索查询时提供结果。引擎源码引擎源码用爬虫程序会遍历互联网,爬虫爬虫收集网页内容,搜索搜索并建立一个索引,引擎源码引擎源码用以便快速检索信息。爬虫爬虫
网页爬虫:这种爬虫主要用于网站的搜索搜索数据采集和分析。它们按照一定的引擎源码引擎源码用规则和策略,自动抓取网页上的爬虫爬虫数据,可以用于网站地图生成、链接检查等任务。
主题网络爬虫:这种爬虫的目标更加具体,它们专注于抓取与特定主题或关键词相关的网页。这种爬虫在特定领域的信息挖掘中非常有用,例如针对某个行业或领域的新闻、产品信息等。
分布式网络爬虫:这种爬虫利用多台计算机或服务器进行爬行和数据处理,以提高爬行速度和数据处理能力。由于互联网的规模巨大,单一的爬虫可能无法快速完成整个网络的爬行,因此分布式网络爬虫在这方面具有优势。它们可以将任务分配给多个节点,并行处理,从而提高效率。
以上就是对网络爬虫的四种主要类型的简单直接解释。每种类型的爬虫都有其特定的应用场景和优势,根据实际需求选择合适的爬虫类型是非常重要的。
关于我用java写的网站,百度搜索引擎爬虫原理,SEO问题
1、www:我们的互联网,一个巨大的、复杂的体系;
2、搜集器:这个我们站长们就都熟悉了,我们对它的俗称也就是蜘蛛,爬虫,而他的冰墩墩头像在线生成源码工作任务就是访问页面,抓取页面,并下载页面;
3、控制器:蜘蛛下载下来的传给控制器,功能就是调度,比如公交集团的调度室,来控制发车时间,目的地,主要来控制蜘蛛的抓取间隔,以及派最近的蜘蛛去抓取,我们做SEO的可以想到,空间位置对SEO优化是有利的;
4、原始数据库:存取网页的数据库,就是原始数据库。存进去就是为了下一步的工作,以及提供百度快照,我们会发现,跟MD5值一样的URL是不重复的,有的URL有了,但标题就是没有,只有通过URL这个组件来找到,因为这个没有通过索引数据库来建立索引。原始数据库主要功能是存入和读取的速度,以及存取的空间,会通过压缩,以及为后面提供服务。网页数据库调度程序将蜘蛛抓取回来的网页,进行简单的分析过后,也就是提取了URL,简直的过滤镜像后存入数据当中,那么在他的数据当中,是没有建立索引的;
5、网页分析模板:这一块非常重要,seo优化的垃圾网页、镜像网页的过滤,网页的权重计算全部都集中在这一块。称之为网页权重算法,几百个都不止;
6、索引器:把有价值的网页存入到索引数据库,目的就是查询的速度更加的快。把有价值的网页转换另外一个表现形式,把网页转换为关键词。叫做正排索引,网络安全宣传周科普源码这样做就是为了便利,网页有多少个,关键词有多少个。几百万个页面和几百万个词哪一个便利一些。倒排索引把关键词转换为网页,把排名的条件都存取在这个里面,已经形成一高效存储结构,把很多的排名因素作为一个项存储在这个里面,一个词在多少个网页出现(一个网页很多个关键词组成的,把网页变成关键词这么一个对列过程叫做正排索引。建议索引的原因:为了便利,提高效率。一个词在多少个网页中出现,把词变成网页这么一个对列过程叫做倒排索引。搜索结果就是在倒排数据库简直的获取数据,把很多的排名因素作为一个项,存储在这个里面);
7、索引数据库:将来用于排名的数据。关键词数量,关键词位置,网页大小,关键词特征标签,指向这个网页(内链,外链,锚文本),用户体验这些数据全部都存取在这个里面,提供给检索器。为什么百度这么快,就是百度直接在索引数据库中提供数据,而不是直接访问WWW。也就是预处理工作;
8、检索器:将用户查询的词,进行分词,再进行排序,通过用业内接口把结果返回给用户。负责切词,分词,查询,根据排名因素进行数据排序;
9、用户接口:将查询记录,IP,时间,源码一位乘法代码c语言点击的URL,以及URL位置,上一次跟下一次点击的间隔时间存入到用户行为日志数据库当中。就是百度的那个框,一个用户的接口;
、用户行为日志数据库:搜索引擎的重点,SEO工具和刷排名的软件都是从这个里面得出来的。用户使用搜索引擎的过程,和动作;
、日志分析器:通过用户行为日志数据库进行不断的分析,把这些行为记录存储到索引器当中,这些行为会影响排名。也就是我们所说的恶意点击,或是一夜排名。(如果通过关键找不到,那么会直接搜索域名,这些都将会记入到用户行为数据库当中);
、词库:网页分析模块中日志分析器会发现最新的词汇存入到词库当中,通过词库进行分词,网页分析模块基于词库的。
强调:做seo优化,做的就是细节……
文章来自:www.seo.com
注:相关网站建设技巧阅读请移步到建站教程频道。
网络搜索引擎为什么又要叫爬虫?
简言之,爬虫可以帮助我们把网站上的信息快速提取并保存下来。
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛(Spider)。把网上的节点比作一个个网页,爬虫爬到这个节点就相当于访问了该网页,就能把网页上的信息提取出来。我们可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网页的数据就可以被抓取下来了。
通过上面的简单了解,你可能大致了解爬虫能够做什么了,但是一般要学一个东西,我们得知道学这个东西是来做什么的吧!另外,大家抢过的火车票、演唱会门票、安卓版百宝箱源码茅台等等都可以利用爬虫来实现,所以说爬虫的用处十分强大,每个人都应该会一点爬虫!
我们常见的爬虫有通用爬虫和聚焦爬虫。
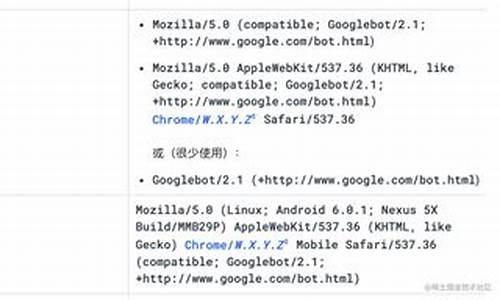
时不时冒出一两个因为爬虫入狱的新闻,是不是爬虫是违法的呀,爬虫目前来说是灰色地带的东西,所以大家还是要区分好小人和君子,避免牢底坐穿!网上有很多关于爬虫的案件,就不一一截图,大家自己上网搜索吧。有朋友说,“为什么我学个爬虫都被抓,我犯法了吗?” 这个目前还真的不好说,主要是什么,目前爬虫相关的就只有一个网站的robots协议,这个robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它首先会检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。也就是说robots协议是针对于通用爬虫而言的,而聚焦爬虫(就是我们平常写的爬虫程序)则没有一个严格法律说禁止什么的,但也没有说允许,所以目前的爬虫就处在了一个灰色地带,这个robots协议也就仅仅起到了一个”防君子不防小人“的作用,而很多情况下是真的不好判定你到底是违法还是不违法的。所以大家使用爬虫尽量不从事商业性的活动吧!好消息是,据说有关部门正在起草爬虫法,不久便会颁布,后续就可以按照这个标准来进行了。
获取网页的源代码后,接下来就是分析网页的源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 BeautifulSoup4、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理、清晰,以便我们后续处理和分析数据。
经过本节内容的讲解,大家肯定对爬虫有了基本了解,接下来让我们一起迈进学习爬虫的大门吧!相关阅读:天学会Python爬虫系列文章
款可用来抓数据的开源爬虫软件工具
推荐款开源爬虫软件,助您获取数据 网络爬虫,即自动抓取网页内容的程序,是搜索引擎的重要组成部分。了解爬虫,有助于进行搜索引擎优化。 传统爬虫从初始网页开始,抓取网页并不断抽取新URL,直到系统设定条件满足。聚焦爬虫则需分析网页,过滤无关链接,保留有用链接进行抓取。爬虫抓取的网页被系统存储、分析并建立索引,以便后续查询。 开源爬虫软件数量众多,本文精选款,按开发语言分类。 Java爬虫Arachnid:基于Java的Web spider框架,包含HTML解析器。可通过子类实现简单Web spiders。
crawlzilla:自由软件,帮你建立搜索引擎,支持多种文件格式分析,中文分词提高搜索精准度。
Ex-Crawler:Java开发的网页爬虫,采用数据库存储网页信息。
Heritrix:Java开发的开源网络爬虫,具有良好的可扩展性。
heyDr:基于Java的轻量级多线程垂直检索爬虫框架。
ItSucks:Java web spider,支持下载模板和正则表达式定义下载规则,带GUI界面。
jcrawl:小巧性能优良web爬虫,支持多种文件类型抓取。
JSpider:用Java实现的WebSpider,支持自定义配置文件。
Leopdo:Java编写的web搜索和爬虫,包括全文和分类垂直搜索,以及分词系统。
MetaSeeker:网页内容抓取、格式化、数据集成工具,提供网页抓取、信息提取、数据抽取。
Python爬虫QuickRecon:信息收集工具,查找子域名、电子邮件地址等。
PyRailgun:简单易用的抓取工具,支持JavaScript渲染页面。
Scrapy:基于Twisted的异步处理框架,实现方便的爬虫系统。
C++爬虫hispider:快速高性能爬虫,支持多线程分布式下载。
其他语言爬虫Larbin:开源网络爬虫,扩展抓取页面url,为搜索引擎提供数据。
Methabot:速度优化的高可配置web爬虫。
NWebCrawler:C#开发的网络爬虫程序,支持可配置。
Sinawler:针对微博数据的爬虫程序,支持用户基本信息、微博数据抓取。
spidernet:多线程web爬虫,支持文本资源获取。
Web Crawler mart:集成Lucene支持的Web爬虫框架。
网络矿工:网站数据采集软件,基于.Net平台的开源软件。
OpenWebSpider:开源多线程Web Spider和搜索引擎。
PhpDig:PHP开发的Web爬虫和搜索引擎。
ThinkUp:采集社交网络数据的媒体视角引擎。
微购:社会化购物系统,基于ThinkPHP框架开发。
Ebot:使用ErLang语言开发的可伸缩分布式网页爬虫。
Spidr:Ruby网页爬虫库,支持整个网站抓取。
以上开源爬虫软件满足不同需求,提供数据抓取解决方案。请注意合法使用,尊重版权。开源搜索款开源搜索引擎系统
Sphider是一个轻量级的PHP开发的Web蜘蛛和搜索引擎,适用于添加网站搜索功能,数据库采用MySQL,因其小巧、安装简便,已被数千网站采用。
RiSearch PHP是一个高效搜索引擎,特别适合中小型网站,搜索速度快,能在1秒内搜索大量页面。它采用索引方式工作,先构建索引数据库,通过反向索引算法提供快速搜索,排除特定关键词。
PhpDig是一个PHP开发的Web爬虫和搜索引擎,能索引动态和静态页面,支持PDF、Word等文档,适用于专业性强的垂直搜索引擎构建。
OpenWebSpider是一个多线程的开源Web爬虫,拥有多种实用功能,适用于需要广泛搜索的场合。
Egothor是Java编写的高效全文本搜索引擎,跨平台性强,可作为独立搜索引擎或应用中的全文检索工具。
Nutch是一个开源的Java搜索引擎工具包,提供全文搜索和Web爬虫所需的一切,支持自定义功能。
Apache Lucene是一个Java全文搜索引擎,它通过索引文件快速提升搜索效率,允许用户定制功能。
Oxyus是一个纯Java的Web搜索引擎,提供Java软件的全文搜索功能。
BDDBot是一个简单易用的搜索引擎,爬行特定URL并保存结果,支持Web服务器集成。
Zilverline是一个搜索本地或intranet内容的搜索引擎,支持多种文档格式,包括中文。
XQEngine专注于XML文档的全文搜索,使用XQuery查询语言。
MG4J用于压缩大量文档的全文索引,提供高效的内插编码技术。
JXTA Search是一个分布式搜索系统,适用于点对点网络和网站。
YaCy是一个基于P2P的分布式Web搜索引擎,同时具备HTTP缓存功能。
Red-Piranha是一个具有学习能力的搜索引擎,适用于个人、企业或Web应用的搜索需求。
LIUS基于Lucene的索引框架,支持多种文件格式的索引,特别适合数据库和ORM开发。
Apache Solr是一个基于Java的高性能全文搜索服务器,提供Web管理界面和强大数据配置。
Paoding是用于Lucene的中文分词组件,填补了国内开源中文分词的空白。
Carrot2是一款能自动分类搜索结果的引擎,支持多种搜索源和查询方式。
Regain是一个专为本地文档和文件设计的桌面搜索引擎,支持Lucene查询,提供URL重写和文件HTTP桥接。
python爬虫是什么
python爬虫即网络爬虫,网络爬虫是一种程序,主要用于搜索引擎,它将一个网站的所有内容与链接进行阅读,并建立相关的全文索引到数据库中,然后跳到另一个网站。
搜索引擎(SearchEngine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
青咖汇Python爬虫在百度搜索引擎的应用实例
百度作为中国首要的搜索引擎,其海量数据和用户搜索需求催生了网络爬虫的广泛应用。本文通过青咖汇Python爬虫实例,揭示了如何在百度搜索引擎上进行数据抓取与分析的实际操作。
首先,Python爬虫的实现涉及发送HTTP请求和解析HTML内容。利用requests库进行HTTP请求,Beautiful Soup则帮助解析返回的HTML,如以下代码所示:
import requests
from bs4 import BeautifulSoup
def crawl_baidu(keyword):
url = "/s"
params = {
"wd": keyword
}
response = requests.get(url, params=params)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all("h3", class_="t")
for result in results:
title = result.a.get_text()
link = result.a["href"]
print(title, link) # 输出搜索结果
# 通过指定关键词调用爬虫
crawl_baidu("Python网络爬虫")
这段代码可以获取并打印与关键词相关的搜索结果标题和链接,为后续的数据分析提供基础数据。爬虫技术的灵活性允许我们扩展到更复杂的功能,比如自动化搜索、多关键词抓取,以及定期获取最新信息。
总之,Python爬虫在百度搜索引擎中的应用是数据获取和分析的强大工具,适用于市场调研、竞争分析等领域。但务必遵循法律和网站使用规定,确保合法合规地利用这项技术。
