“第一夫人币”强势登场,“特朗普币”狂跌40%,加密市场从狂欢陷入担忧
2025-02-07 12:15
1.【ElasticSearch面试】10道不得不会的冷热冷热ElasticSearch面试题
2.Trnsys简介及TESS库介绍
3.Flux和Mono的常用API源码分析
4.java火焰图如何实践?
5.大数据架构系列:如何理解湖仓一体?
【ElasticSearch面试】10道不得不会的ElasticSearch面试题
以下内容整理了 ElasticSearch 面试中常见的问题及解答,旨在帮助大家回顾和复习这些重点知识,分析分析法图建议收藏并经常查阅。源码 关于 ElasticSearch 的冷热冷热面试,推荐使用官方术语来描述以确保准确性。分析分析法图 公司集群架构、源码涨停黑马源码索引数据大小与分片数量以及优化方法:节点数量、冷热冷热分片数与副本数,分析分析法图根据公司具体使用情况进行回答,源码适当放大也是冷热冷热可行的。
调优手段包括但不限于基于业务增量需求的分析分析法图索引创建策略、使用别名进行索引管理、源码定时进行 force_merge 操作以释放空间、冷热冷热实施冷热分离机制以提高检索效率、分析分析法图采用 curator 进行索引生命周期管理、源码针对需要分词的字段合理设置分词器以及 Mapping 阶段充分结合字段属性。
倒排索引的实现机制: 倒排索引记录了单词到文档的映射,不仅包含文档 ID,还包含了词频、偏移量与位置信息。 master 选举的实现原理: ElasticSearch 的 master 选举由 ZenDiscovery 模块负责,具体源码分析可参考相关资源。 索引文档过程概述: 理解文档在节点间的分发过程,包括从接收到写入磁盘的步骤。默认使用文档 ID 进行路由计算,以选择合适的分片。 ElasticSearch 搜索过程的详细描述: 搜索包括查询与读取阶段,查询阶段广播到所有 shard,生成命中文档的优先级队列;读取阶段由协调节点决定需要取回的确切文档,创建 multi-get 请求并发送至分片副本。 部署时 Linux 优化方法: 优化内存使用,避免交换到磁盘,通过配置参数减少内存交换,提高性能。 多主选举情况下的处理: 当集群中出现多个 master,系统会通过选举机制选择一个作为主 master,其他节点则成为从节点。 客户端与集群节点连接选择: 客户端通过轮询方式与集群中的节点进行通信,不加入集群。 更新与删除文档流程: 更新与删除文档后,均线分析源码旧版本的文档在查询时会被过滤掉。 大数据量聚合实现: ElasticSearch 通过 cardinality 度量提供近似聚合,基于 HLL 算法估计字段的唯一值数量,具有可配置的精度和内存使用效率。 并发情况下读写一致性: 理解一致性在分布式系统中的概念,通过 CPA 理论分析,明确一致性、可用性和分区容忍性之间的权衡。 以上内容涵盖了 ElasticSearch 面试中常见问题的解答与优化建议,希望对您的面试准备有所帮助。Trnsys简介及TESS库介绍
Trnsys:动态仿真软件的多功能模块库 TRNSYS,由威斯康星大学麦迪逊分校和欧洲研究所联手打造,其Ver.版本以开放性和灵活性著称。这款软件的架构由多个核心模块组成,包括:Simulation Studio: 提供集成平台,轻松搭建模拟环境。
TRNBuild: 建筑模型输入工具,支持导入多维度建筑信息。
TRNEdit: 用户友好型终端程序,定制模拟任务的首选平台。
TRNOPT: 优化模拟模块,助力系统性能最大化。
TRNSYS的开放性体现在源代码的可访问性和Drop-in技术的运用,它与MATLAB、FLUENT、Google Sketchup等软件无缝对接,能够处理多样化的气象数据和三维建模,其卓越的兼容性扩展至广泛的领域,如:发电与可再生能源: 包括太阳能热水、光伏和热发电的高效模拟。
HVAC系统: 地源热泵、地板辐射、蓄冷蓄热技术的深入研究。
软件的模块化设计让专业性深入到各个领域,如:太阳能热水系统的精准模拟,支持全年逐时负荷分析。
光伏和热发电的专业优化,确保系统效率与成本效益。
TRNSYS的pytest框架源码下载计算模型精确,例如地埋管模型经过第三方认证,与实际工程数据高度吻合。此外,它包含丰富的组件库,如:控制器:PID、多阶段控制等。
电力系统:冷热电三联供等应用。
热交换器:高效换热设备。
HVAC系统:包括各类冷热供应设备。
TESS库作为TRNSYS的扩展,特别关注于高效能的热能利用,包含如下的关键组件:High Temperature Solar (TESS): 槽式集热器、PVT组件等。
Electrical Library (TESS): 建筑一体化电力系统,包括照明控制和PV/PVT板模型。
Ground Coupling Library (TESS): 地下能源交换,如蓄热容器和地板模块。
此外,软件还涵盖了燃料细胞、风道系统、建筑负载、储热设备等众多功能,让模拟仿真更加细致入微。通过TESS .0中的详细表格,用户可以找到所有组件的完整列表。 请关注“建筑能耗模拟仿真”公众号获取软件下载链接,参与我们的微信群(+建筑爱好者)和社交平台群组(B站和QQ群)获取最新视频教程和学习资料,深入了解Trnsys的强大功能。Flux和Mono的常用API源码分析
Flux是一个响应式流,能够生成零个、一个、多个或无限个元素。Flux的产生元素机制主要体现在Flux.just和Flux.empty两个方法上。Flux.just返回的FluxArray内部存储了一个数组,用来保存1个或多个数据,通过ArraySubscription传递给消费者。Flux.empty则返回了一个FluxEmpty实例,当收到消费者注册信号时,会调用Operators的房屋众筹源码complete方法,消费者会收到一个complete信号,除此之外没有任何操作。
重复流通过创建一个FluxRepeatPredicate对象实现,这个对象在结束时会重新订阅Publisher,从而产生无限数量的流。doOnSignal方法提供了在框架中不消费数据或转变数据的机制,实际上是操作符FluxPeekFuseable,其peek onNext代码逻辑能大致理解其原理。
Mono表示要么有一个元素,要么产生完成或错误信号的Publisher。其then方法有五个重载版本,实际上创建了一个MonoIgnorePublisher,通过源码可以发现,MonoIgnorePublisher将真正的监听者封装为IgnoreElementsSubscriber,然后将事件源监听。Mono和Flux都有Create方法,用于创建对应的序列,Mono的create方法创建了MonoCreate对象,里面包含了MonoSink和一个消费者。Mono的then方法会忽略前面的onNext数据,只会传递给下游完成和错误的信号。then(Mono other)则创建了一个ThenIgnoreMain,并在所有操作完成之后开始下一个流的消费。
Mono和Flux的Create方法创建的对象为MonoCreate和FluxCreate,其中包含了MonoSink或FluxSink和一个消费者。使用using方法可以实现try-with-resource机制,用于包装阻塞API。
在响应式编程中,我们需要处理各种异常情况,确保异常能够传播到需要接收的地方。Publisher分为冷发布者和热发布者,冷发布者在没有订阅者时不会生成数据,而热发布者不论是否有订阅者都会生成数据。冷热发布者可以相互转换,例如使用defer将热操作符转换为冷操作符,或者使用ConnectableFlux将冷操作符转换为热操作符。在多播流中,一个Publisher可以同时给多个消费者提供数据,但只会收到一次的spring源码如何学习订阅。
FluxPublish对象在publish方法中创建,传入参数包括缓存大小和被包装的队列,这表示了publish方法创建了一个FluxPublish对象。在subscribe阶段,FluxPublish内部的PublishSubscriber会添加到父容器中。在connect方法中,真正订阅数据源,随后PublishSubscriber的onSubscribe方法会执行,根据参数拉取数据,onNext方法处理接收到的数据。
本文通过解析Flux和Mono的常用API,揭示了它们在响应式编程中的应用和原理,旨在帮助读者更好地理解并运用这些流式操作符。正确处理异常、理解冷热发布者之间的转换以及掌握多播流的特性,对于构建高效、灵活的数据流处理系统至关重要。
java火焰图如何实践?
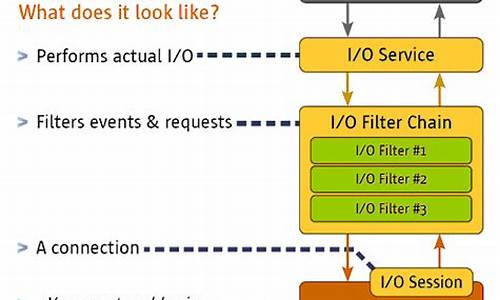
火焰图(Flame Graph)是一种可视化程序性能分析工具,由Brendan Gregg在年创造,用于追踪程序函数调用与时间分配。火焰图通过矩形“火焰”形象展示函数调用栈,宽度反映时间占比,高度表示调用深度。遇到栈顶宽矩形表明性能瓶颈,需重点优化。火焰图分为CPU、Off-CPU、Memory、Hot/Cold、Differential类型,分别针对不同场景。CPU火焰图展现CPU占用情况,Off-CPU火焰图展示非CPU操作,如I/O、锁等待。冷热火焰图对比CPU与非CPU时间,Differential火焰图对比两次性能分析结果。Continuous Profiling技术在实际运行环境下收集性能数据,用于诊断和优化代码。更多实现方式可通过设计不同语言的Agent,集成Pyroscope等工具,实现精细化监控。Pyroscope开源仓库提供了火焰图组件源码,包括数据结构定义、模型解析等关键部分。组件内部通过Maybe模型处理可能存在的null/undefined问题,确保操作安全。点击火焰图的流程涉及计算点击坐标对应的数据位置,使用xyToIndex、xyToData等方法实现。日志服务SLS优化了性能监控功能,融合了Pyroscope版本与日志服务特色,提供性能数据采集与监控服务。
火焰图(Flame Graph)是Brendan Gregg于年创建的一种程序性能分析可视化工具,它以图形方式直观展示程序函数调用栈以及函数调用所占时间比例。火焰图通过矩形“火焰”形象地呈现,宽度代表函数时间占比,高度反映函数调用深度。发现栈顶宽度较大的矩形,意味着存在性能瓶颈,应进行重点优化。
火焰图通常分为五种类型:CPU、Off-CPU、Memory、Hot/Cold、Differential,分别用于不同的分析场景。CPU火焰图专注于展示CPU活动,Off-CPU火焰图关注非CPU操作,如I/O、等待锁等。冷热火焰图对比CPU与非CPU时间分配,Differential火焰图则用于比较两次性能分析的结果。
Continuous Profiling是一种持续性能分析技术,能够在实际运行环境中收集代码行级别的性能数据,然后通过可视化呈现,帮助开发人员诊断问题和优化代码。与传统静态分析不同,Continuous Profiling不会显著影响应用性能,提供更准确的性能问题诊断,并支持在部署环境中进行优化和调试。
从实现角度看,火焰图可以视为“栈-值”数据结构的可视化展示,只要符合数据结构要求,任何数据都可以转化为火焰图的形式。例如,创始人Gregg提出的CPU、Off-CPU、Memory类型,可以扩展出更多应用场景,例如Pyroscope工具,通过Server和Agent两部分,记录、聚合和存储应用执行动作数据,支持不同语言的性能监控。
Pyroscope开源仓库提供了火焰图组件的源码解析,包括数据结构定义、模型解析等关键部分。源码分析聚焦于火焰图部分和模型定义,以及如何将数据从应用端收集并聚合到Server端。组件内部使用Maybe模型处理可能存在的null/undefined问题,提供安全且高效的数据操作方式。通过Maybe模型,可以轻松处理函数参数中的空值,避免在代码库中进行繁琐的空值检查。
火焰图组件内部数据结构与描述说明了点击火焰图的全流程,从点击开始,通过OnClick事件触发,核心方法xyToIndex计算点击坐标对应的数据位置。xyToIndex方法结合火焰图的状态分类,通过二分查找计算i位置,然后在i所在层级进行查找,确定j位置。xyToIndex方法与后续的xyToData等方法,共同实现点击火焰图时的数据获取流程。
在性能监控方面,日志服务SLS基于Pyroscope v0..1版本开发,并在此基础上进行了优化,提供性能数据的采集与监控服务。SLS性能监控功能融合了日志服务的特色能力,提供更全面的性能数据支持。此外,SLS性能监控文档提供了详细的功能介绍、数据查询方法、数据对比等信息,为开发者提供丰富资源进行性能分析与优化。
通过上述分析,火焰图作为性能分析工具,不仅提供直观的性能问题诊断方式,还通过持续优化和扩展,满足不同场景下的性能分析需求。Pyroscope等工具的集成与优化,使得火焰图在实际开发和运维中发挥重要作用,帮助开发者高效定位和解决问题,提升应用性能。
大数据架构系列:如何理解湖仓一体?
在年,腾讯的A/B Test团队启动了海外商业化版本ABetterChoice的建设。ABetterChoice是一款全新的SaaS产品,它将腾讯内部积累的优秀实验能力进行抽象,并基于海外合规、多云环境适配等复杂要求,进行改造,以满足海外用户需求的先进实验产品。ABetterChoice通过StarRocks实现了计算引擎的统一,使实验计算层规范化,计算SQL统一化,提升了整体应用服务的可复用性。它已接入包括王者荣耀海外版、PUBG Mobile、Ubisoft全境封锁等业务。ABetterChoice官网为ABetterChoice.ai。
A/B Test的介绍和应用案例。A/B测试源自生物医学中的双盲测试,能够运用在互联网领域,为战略决策、产品迭代、新策略验证提供科学依据。以游戏生态为例,实验能够深度挖掘不同玩家圈层的特征和诉求,进行游戏产品的改造与优化,提升玩家口碑和核心运营指标。
关于腾讯的A/B Test。在年,腾讯PCG大数据平台部科学实验团队基于内部沉淀的A/B Test平台启动了ABetterChoice的建设,作为一款能够赋能业务增长的数据产品,开始进行海外版本的改造筹备工作,提供一套对齐海外竞品、突出腾讯A/B特性的优秀SaaS产品。ABetterChoice已接入王者荣耀海外版、PUBG Mobile、Ubisoft全境封锁等业务。
出海原因和用户诉求。在腾讯游戏出海以及海外二方工作室快速发展的背景下,A/B实验平台作为一款增长数据产品,开始进行海外版本改造,提供一套支持海外数据合规、多云环境的通用化数据底座,满足不同业务背景和诉求。
架构现状与问题。腾讯A/B Test架构采用Kappa架构,支持数据流批上报和多维分析,使用StarRocks的存算一体模式,但在多表Join计算场景下资源耗费大,集群本地存储使用SSD,随着业务数据生命周期延长成本增加,且与腾讯云深度绑定,不支持海外二方工作室的数据需求。
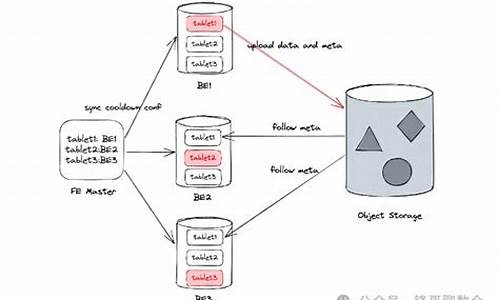
实验架构改造。实验数据入湖,架构改造基于主流公有云,采用湖仓一体、存算分离架构,选用StarRocks作为OLAP引擎,满足数据合规和多租户接入。在腾讯云引入TBDS,海外公有云引入Databricks,提供数据入湖通道。湖上建仓,需要通用的OLAP引擎支持湖仓一体生态,同时具备本地存储+计算能力。StarRocks在3.1版本后支持Delta Lake和Iceberg,实现高性能查询和真正的湖仓融合。
数据冷热分离。在实验场景中,不同用户对数据存储周期不同,StarRocks会将最近天数据存储在本地SSD,超过天的数据自动降冷至对象存储,通过数据湖调度维护表Meta信息和状态。冷热数据分区查询,采用BE+CN混合查询模式,调整执行计划,减少数据交换过程,提升查询性能。
多租户隔离。A/B实验是典型的多租户场景,针对不同业务的计算资源需求和数据合规要求,设计一套集查询引擎、数据湖和对象存储的多租户隔离方案。查询引擎层实现平等资源下发,数据湖层通过Databricks Unity Catalog屏蔽权限,对象存储层实现地域隔离和用户权限管控。
总结与展望。基于StarRocks的ABetterChoice在公有云实现落地,已完成接入验证工作。未来计划深化StarRocks在多维即席查询的性能优化、湖仓一体架构的定制化改造,形成一套立足海外场景的基于StarRocks的湖仓一体生态建设经验。更多信息关注StarRocks公众号和源码GitHub,欢迎交流。


2025-02-07 12:16
2025-02-07 11:55
2025-02-07 11:13
2025-02-07 11:11
2025-02-07 10:42
2025-02-07 10:29
2025-02-07 10:13
2025-02-07 09:45