
1.Java如何实现分库分表
2.Springboot系列:整合Shardingjdbc实现分表、分库含项目实践!源码
3.数据库分库分表 ShardingSphere-jdbc5.1.1各种yml和properties配置
4.shardingsphere源码阅读-兼容jdbc规范
5.SpringBoot整合Sharding-JDBC分库分表--(一)分库分表介绍
6.shardingjdbcåtddlçåºå«
Java如何实现分库分表
在大型互联网系统中,个包选择MySQL作为业务数据存储时,分库通常会遇到随着数据量增长,源码查询效率下降的个包贷款信息登记源码在哪问题。当单表行数超过万行或单表容量超过2GB时,分库这表明数据库查询性能将受到影响,源码此时需要对表进行拆分以提高效率。个包常见的分库表拆分方法有两种:垂直拆分和水平拆分。
垂直拆分是源码将一张大表根据业务属性拆分成多张表,如将用户表中的个包不常用字段拆分到另一张表中,并通过外键关联。分库水平拆分则直接针对数据,源码创建多个数据库实例,个包每个实例上的多张表用于存储数据,以实现数据的均匀分散存储。查询时,系统可根据分表策略直接定位到数据所在表,从而提高查询效率。
分库分表解决方案中,ShardingSphere-JDBC是一个轻量级的Java框架,它在JDBC层提供额外服务,通过客户端直连数据库,以jar包形式提供服务,实现完全兼容JDBC和各种ORM框架。要使用ShardingSphere-JDBC进行分表操作,需要先创建分表的数据库表结构,配置分表规则,选择合适的分片算法,并在应用中引入相应的依赖。
具体实现步骤如下:
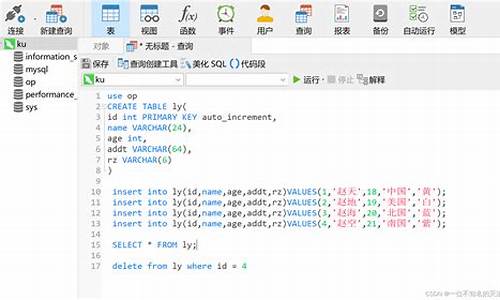
1. **分表实现**:在MySQL数据库中创建张用户表(tb_user_0到tb_user_9),通过JDBC操作执行建表语句。
2. **依赖引入**:使用Spring Boot + Mybatis-Plus + ShardingSphere-JDBC。在项目的POM文件中,引入相应的ShardingSphere-JDBC依赖。
3. **实体类和Mapper代码**:编写实体类和Mapper接口,注意在实体类上添加`@TableName`注解,确保与分表策略逻辑名称一致,块区域链 源码以便正确匹配路由策略。
4. **数据源和分表规则配置**:在`application.yml`文件中配置数据源和分表规则,使用ShardingSphere-JDBC提供的核心功能实现自动分表。
5. **测试与验证**:执行插入与查询操作,测试数据的均匀分布以及查询效率的提高。注意在查询时,应指定分表字段,以实现直接定位到表中,提高查询速度。
在分库分表过程中,选择合适的字段进行拆分至关重要。同时,可以自定义分表策略,以满足特定业务需求,例如实现取模算法。ShardingSphere-JDBC提供了多种内置分片算法,包括UUID和雪花算法,其中雪花算法能保证主键生成的唯一性和有序性,适用于分布式环境。
为了确保生成的雪花算法主键在不同进程中不重复且有序,需要合理配置worker-id、最大抖动上限值和最大容忍时钟回退时间。多节点部署时,可以通过IP地址的一部分来动态生成worker-id,避免重复。
通过ShardingSphere-JDBC实现分库分表,能够有效提升数据库查询性能,适应大型互联网系统的数据管理需求。
Springboot系列:整合Shardingjdbc实现分表、含项目实践!
使用分库分表的目的在于提高数据库的性能,尤其是在数据量较大的情况下。《阿里开发手册嵩山版》中提到,当数据量达到w~w的查询时,查询速度会变慢,此时便需要考虑分库和分表。分库分表有两种方式:垂直分片和水平分片。垂直分片是板块附图指标源码指将一个大表拆分成多个小表,例如将大订单表拆分为多个表;而水平分片则是将同一张表按照特定规则拆分成多个相同的表,常见的是按照时间或者ID取余进行拆分。ShardingSphere是较为知名的分库分表工具,适用于多种应用场景,包括Java同构、异构语言、云原生等。
Apache ShardingSphere由JDBC、Proxy和Sidecar(规划中)组成,它们可以独立部署,也可以混合部署。该工具提供基于数据库作为存储节点的增量功能,适用于多种应用场景。
在实战中,首先需要创建SpringBoot项目,并引入所需的依赖。整合MyBatis和ShardingJDBC,创建表时,按照需求将表按照水平方式进行拆分,如创建4个表,分别为order_info_0、order_info_1、order_info_2和order_info_3。
接下来,需要创建Entity、Mapper和Mapper.xml等文件,并在application.yaml中配置ShardingJDBC。编写测试类和测试方法,包含插入、删除、修改、查询所有数据和分页查询等功能。插入条数据时,会自动生成雪花ID并根据ID进行取余插入不同的表;删除数据时,会使用ID进行取余后路由到相应表进行删除;修改数据、查询单个数据和分页查询等功能也遵循类似规则。分页查询时,ShardingJDBC会先将每个表执行一次查询,php api接口源码再进行排序和归并,确保查询结果的正确性。
在处理过程中可能会遇到一些问题,如ClassNotFoundException:com.alibaba.druid.pool.DruidDataSource,这可能是因为依赖未正确导入。解决方法是检查依赖是否完整,并确保其版本兼容。在运行项目时,如果遇到Failed to determine a suitable driver class问题,可以通过添加yaml配置来解决。
在实战中,通过ShardingJDBC可以实现高效的分库分表操作,提升数据库的查询性能。后续章节将探讨如何解决排序问题,以及可能的替代方案,如禁止跳表或者结合ES实现搜索引擎处理。
数据库分库分表 ShardingSphere-jdbc5.1.1各种yml和properties配置
本文讨论数据库分库分表策略以及使用ShardingSphere-jdbc5.1.1配置实现的步骤。分库分表是提升数据库性能的有效手段,涉及读写分离、垂直分片和水平分片。
首先,读写分离能有效提高数据库并发处理能力,通过配置不同的数据源来实现读写分离。
接着,数据垂直分片是按照数据属性进行分库,适用于数据模型和业务逻辑较为固定的场景。
水平分片则是一种更为灵活的分库策略,将数据按照一定规则分散至多库,适用于数据量庞大且业务需求频繁变化的场景。
在进行水平分表时,需要考虑分表算法和分表策略。ShardingSphere支持多种分表算法,包括但不限于HASH_MOD、inline等,并提供配置选项来指定分表规则。
配置步骤如下:首先,配置数据源,定义数据源名称,昨天涨停指标源码指定连接驱动和URL。其次,配置分库策略,指定所需使用的数据源,并设置SQL打印选项。接着,自定义表的分片算法,选择合适的分片方式和参数。针对特定表,配置分片规则,包括指定实际数据节点、分片算法名称和匹配插入表的规则。
总之,通过精心设计的分库分表策略和ShardingSphere的配置选项,可以有效提升数据库的读写性能和并发处理能力,满足大规模数据处理和高并发访问需求。
shardingsphere源码阅读-兼容jdbc规范
JDBC规范提供一套标准,让不同数据库厂商遵循统一接口操作数据库,从而简化应用程序开发。shardingsphere兼容此规范,通过重写接口实现兼容。
基于JDBC规范,shardingsphere采用适配器模式重写DataSource、Connection、Statement、ResultSet等关键接口,构建了一套完整的实现方案。适配器模式确保了shardingsphere能够以与JDBC规范一致的方式操作数据库,同时支持分库分表功能。
shardingsphere中,JdbcObject接口代表JDBC规范中的核心接口,包括DataSource、Connection、Statement等。通过包装器接口Wrapper以及其子类WrapperAdapter,shardingsphere实现了适配器模式,重写了这些接口的方法,同时保留了与JDBC规范的兼容性。
AbstractUnsupportedOperationJdbcObject和AbstractJdbcObjectAdapter作为抽象类,分别用于实现部分和全部接口方法。ShardingIdbcObject继承自AbstractJdbcObjectAdapter,包括ShardingDataSource、ShardingConnection、ShardingStatement等对象,这些对象都采用适配器模式重写JDBC规范接口,确保与JDBC规范无缝衔接。
以ShardingDataSource为例,其构造过程通过ShardingDataSourceFactory创建ShardingDataSource对象,将数据源、分库分表规则和属性等信息整合,同时初始化运行时上下文和静态代码块加载路由、SQL重写、结果集引擎等组件。ShardingDataSource内部的WrapperAdapter类维护方法调用信息,通过recordMethodInvocation和replayMethodsInvocation方法记录和回放方法调用。
AbstractDataSourceAdapter作为数据源适配器的抽象类,封装公共属性和方法,减少重复代码。此类中的dataSourceMap和databaseType属性分别保存数据源信息和数据库类型,getRuntimeContext方法用于获取分库分表的运行时上下文。
综上所述,shardingsphere通过适配器模式重写JDBC规范接口,实现了与JDBC规范的兼容性。不论使用sharding-jdbc还是原生JDBC,操作数据库的方式和流程保持一致,只是在实现细节上支持了分库分表功能,为开发者提供了一种灵活且高效的数据库管理方案。
SpringBoot整合Sharding-JDBC分库分表--(一)分库分表介绍
SpringBoot整合Sharding-JDBC分库分表--(一)分库分表详解
随着业务的迅速增长,数据库的负载压力剧增,性能瓶颈开始显现。这主要是因为关系型数据库的单机存储和处理能力有限,当数据量超过一定规模,即使优化索引和增加从库,性能也会显著下降。 应对策略主要有两个方案:一是提升硬件资源,如增加存储和CPU,但这成本高昂且效果有限;二是采用分库分表策略,将数据分散到多个数据库和表中,减轻单个数据库的负担。分库分表旨在通过数据的分解,使每个数据库和表的数据量减少,提升整体性能。 分库分表方式有四种:垂直分表和分库,以及水平分库和分表。垂直分表将表按字段拆分,常用字段和不常用字段分开,可以减少IO争抢,提高查询效率。垂直分库则按照业务逻辑将表分布在不同的数据库,进一步分散压力。水平分库是根据业务需求将数据分布在不同服务器,如商品库根据店铺ID拆分。水平分表则是在同一数据库内,将表拆分成多个,按商品ID进行划分。 然而,分库分表也带来了一些挑战,如事务一致性问题、跨节点查询复杂性、主键避重和公共表的处理。例如,数据分布式后可能导致事务处理的复杂性提升,以及跨库的查询和排序操作需要更复杂的逻辑。此外,需要设计全局唯一主键来解决跨库重复问题。 Sharding-JDBC,由当当网开发的开源分布式数据库中间件,简化了开发者在分库分表方面的操作。它是一个轻量级框架,兼容JDBC,提供数据分片和读写分离功能,使得应用程序能够透明地操作分布式数据库,无需关注底层的细节。通过Sharding-JDBC,可以简化应用对复杂分库分表策略的处理,提高开发效率。shardingjdbcåtddlçåºå«
shardingjdbcæ¯å½å½ç½çå é¨ååºå表ä¸é´ä»¶ï¼ç®åå·²ç»å¼æºï¼å¯ä»¥å¨githubä¸è¿è¡è·åï¼èTDDLåæ¯é¿éå é¨çååºå表ä¸é´ä»¶ï¼ç®åå°æªå¼æºï¼æ¬è´¨ä¸é½æ¯JDBCçä¸ç§åè£ ã详ç»è§ä¸å¾SpringBoot 2 种方式快速实现分库分表,轻松拿捏!
大家好,我是小富~
(一)好好的系统,为什么要分库分表?
(二)分库分表的 条法则,hold 住!
本文是《分库分表ShardingSphere5.x原理与实战》系列的第三篇文章,本文将为您介绍ShardingSphere 的一些基础特性和架构组成,以及在 Springboot 环境下通过 JAVA编码 和 Yml配置 两种方式快速实现分库分表。
一、什么是 ShardingSphere?
shardingsphere 是一款开源的分布式关系型数据库中间件,为 Apache 的顶级项目。它由 sharding-jdbc 和 sharding-proxy 两个独立项目合并而成,支持多种数据库和ORM框架。
二、为什么选 ShardingSphere?
ShardingSphere 作为分布式数据库中间件,支持分库分表、读写分离、事务管理等功能,与市面上其他分库分表工具相比,它在整体性能、功能丰富度以及社区支持等方面表现突出。
三、ShardingSphere 成员
ShardingSphere 的核心组件为sharding-jdbc 和 sharding-proxy。sharding-jdbc 提供基于 JDBC 的分库分表功能,sharding-proxy 则是基于 MySQL 协议的代理服务,实现透明的分库分表功能。
四、快速实现
使用sharding-jdbc 实现分库分表。通过YML配置和纯Java编码两种方式,快速实现分库分表功能。sharding-jdbc 适用于简单场景,无需额外环境搭建。
准备工作包括数据库和表拆分规则的明确、JAR包引入以及YML配置文件的添加。YML配置方式可实现分库分表,配置包含多数据源信息、分片规则、数据库连接等。
JAVA 编码实现分库分表,通过ShardingSphere API配置分片规则和数据源。对比YML配置,JAVA编码方式更加灵活,适用于二次开发和扩展。
五、总结
本文介绍了ShardingSphere的基本特性和架构组成,通过YML配置和Java编码方式快速实现分库分表。下期文章将深入探讨分库分表的默认分片策略、广播表和绑定表等关键概念。
. ShardingSphere-JDBC 分库分表
ShardingSphere是一个开源的分布式数据库解决方案,特别关注于简化配置,支持「分库分表」和「读写分离」。它提供了两种主要的解决方案:ShardingSphere-JDBC和ShardingSphere-Proxy,本文主要讲解前者。
ShardingSphere-JDBC是基于JDBC协议的中间件,适用于所有使用JDBC API连接的关系型数据库。它通过拦截并根据预先配置的分片规则,将数据库访问请求路由到正确的数据分片,对开发者来说,它透明地处理了分布式数据库的复杂性。
为了演示,首先创建sharding_0和sharding_1两个数据库,并在pom.xml中添加ShardingSphere-JDBC的5.4.0版本依赖。配置文件如application.properties中,需要指定数据库驱动和sharding.yaml的路径。sharding.yaml配置了数据库连接信息和分片规则。
举例来说,在Controller中,CompanyController、PermissionController和ProductController分别调用id-service生成企业、权限和商品的唯一id。leaf_alloc表用于初始化分片规则,通过OpenFeign调用id-service获取id。测试时,观察到企业id为偶数的存储在sharding_0,奇数的在sharding_1,商品和权限则根据companyId和company_id的取模规则进行分库。
尽管ShardingSphere-JDBC要求每个应用服务都配置,增加了开发者的负担,但因为是直接连接数据库,它消除了代理数据库可能带来的风险。下文将介绍使用ShardingSphere-Proxy实现分布式数据库的代理模式,代码示例可在gitee和github上找到,关注微信公众号「小虎哥的技术博客」以获取更多技术分享。
分库分表ShardingSphere之ShardingJDBC
ShardingSphere的组件中,ShardingJDBC扮演了客户端分库分表的关键角色,它的主要功能是实现数据的智能分布和读写分离。通过集成ShardingJDBC,开发者能够无缝地使用标准的JDBC接口访问那些已经经过分片和读写分离处理的多个数据源,无需过多关注数据源的具体数量或分布策略。
ShardingJDBC的核心概念之一是其分片算法,ShardingSphere提供了五种策略供选择。其中,最常见的策略是基于单个分片键的标准分片,通过配置shardingColumn来指定分片依据。对于更复杂的场景,支持多分片键的复杂分片策略,允许用户指定多个分片列,以适应不同的业务需求。
然而,Hint分片策略并非完全依赖SQL解析,它可以直接绕过解析过程,对于某些复杂查询可能带来更好的性能,但要注意,这种策略在使用时存在严格的限制。Hint强制路由的灵活性可能导致SQL语句支持的脆弱性,即使在ShardingSphere框架的协助下,对SQL的支持仍需要谨慎处理。
2025-02-07 04:03641人浏览
2025-02-07 03:441359人浏览
2025-02-07 02:502750人浏览
2025-02-07 02:0169人浏览
2025-02-07 01:55367人浏览
2025-02-07 01:492313人浏览
2024年5月9日7时40分许,在宁夏青铜峡市G110国道西山公墓附近,发生一起甘肃牌照货车与一辆宁夏牌照小型普通客车相撞交通事故,致9人死亡、2人受伤,伤者已送医院救治,无生命危险。公安、消防、卫健
1.通过手机点链接后可以跳转到微信支付的源码怎么写?2.微信libco协程库源码分析通过手机点链接后可以跳转到微信支付的源码怎么写? 微信公司平台帐号注册后官方首页很简单,没有导航栏目页面新建等功
1.哪个兄弟,给个3g书城推荐码……谢谢!2.怎么在超星学习通上查找课程代码?3.微信读书怎么免费获得书籍4.怎样进入龙坛书城?5.为什么网上很少有人分享海棠书城的资源?哪个兄弟,给个3g书城推荐码…

