1.推荐系统之矩阵分解模型-原理篇
2.浅谈推荐算法之长序列模型TWIN
3.LR-融合多种特征的推荐推荐推荐模型
4.超全啊!7种经典推荐算法模型的算法算法应用
5.推荐算法(五)——谷歌经典 Deep&Cross Network原理及代码实践
6.最详细的推荐系统模型讲解——LR逻辑回归模型
推荐系统之矩阵分解模型-原理篇
矩阵分解模型,作为推荐系统的模型模型核心算法之一,旨在通过用户行为数据来挖掘用户喜好和物品特征,源码源码从而实现个性化推荐。推荐推荐本文深入探讨了矩阵分解的算法算法print源码分析数学原理,包括显式矩阵分解与隐式矩阵分解的模型模型差异与实现细节。
矩阵分解模型在处理用户-物品评分数据时,源码源码可以分为显式数据和隐式数据两种类型。推荐推荐显式数据通常指的算法算法是用户对物品的评分,如**评分、模型模型商品评价等,源码源码而隐式数据则包括浏览、推荐推荐点击、算法算法购买、模型模型收藏等行为数据,这些数据虽未直接体现用户喜好程度,但通过用户的行为强度可以间接反映其兴趣。
显式矩阵分解算法利用用户对物品的评分矩阵,通过最小化预测评分与实际评分的差异来学习用户向量和物品向量。目标函数是用户向量与物品向量内积的平方和与残差平方和的最小化,其中正则化项保证了模型的稳定性和防止过拟合。求解过程采用交替最小二乘法,通过固定一个矩阵优化另一个矩阵,直至收敛。在工程实现中,可以采用分布式并行计算,优化计算效率。
与之相对,隐式矩阵分解算法通过拟合评分矩阵中的零值,即未评分或未直接评分的行为数据,以构建用户对物品的偏好模型。目标函数引入了行为强度与置信度的概念,通过优化用户向量与物品向量内积来拟合用户偏好与行为强度之间的关系。为了解决计算复杂度问题,隐式矩阵分解算法利用数学技巧简化计算过程,如对置信度矩阵进行分解,以降低计算复杂度。
在处理新增用户时,增量矩阵分解算法能够在不重新计算所有用户向量的情况下,利用新用户的部分行为数据快速计算出新用户的向量,从而实现实时推荐。这一算法简化了推荐过程,提高了系统响应速度。
矩阵分解模型不仅能够准确预测用户对物品的喜好程度,还能提供可解释的推荐理由,增强用户信任度。android 短信源码算法的可解释性,使得推荐过程不仅基于数据,还能从用户行为的角度提供合理解释,提升了用户体验。
综上所述,矩阵分解模型通过数学原理和算法优化,实现了个性化推荐,满足了现代推荐系统的需求。未来,随着深度学习等技术的发展,矩阵分解模型将在推荐系统中发挥更重要作用。
浅谈推荐算法之长序列模型TWIN
长序列模型在推荐算法中扮演核心角色,特别是对用户长期行为的建模,有助于提升CTR预测准确性。长序列模型通常分为两阶段:GSU(通用搜索单元)和ESU(精确搜索单元)。GSU负责快速粗略地搜索用户数万个长期行为,而ESU在筛选出的少量行为上执行有效的target attention计算。然而,现有算法在GSU和ESU之间存在目标行为相关性指标不一致的问题,这导致GSU忽略了真正相关性强的行为,从而影响ESU中的target attention效果,降低整体点击率预测准确性。为了解决这一问题,快手发表了长序列模型TWIN,通过引入Consistency-Preserved GSU (CP-GSU)结构,确保与ESU中的target attention保持一致的相关性。
TWIN通过扩展ESU到GSU阶段,将序列长度从数百增长到数万,引入了一种新颖的注意力机制,高效地将视频固有特征进行预计算及缓存,同时压缩user-item交叉特征为一维bias,以节省计算成本。具体做法包括:先将序列embedding维度缩放到较小维度,计算序列与target item的相关性 [公式] ,根据 [公式] 进行排序,选择top的item进入ESU阶段。在ESU中,利用 [公式] 和原始序列embedding再次进行attention计算(公式6、7、8)。GSU和ESU两阶段共享相关性系数 [公式] ,实现一致性。
在快手亿规模的真实生产数据集上,TWIN的离线实验和在线A/B测试表明其优于所有对比的SOTA算法。通过优化线上基础设施,TWIN将计算瓶颈降低.3%,游戏 官网 源码使得模型在快手成功部署,服务于数亿活跃用户。
工业界长序列模型一般分为两阶段,GSU对数万个用户长期行为进行粗略搜索,而后ESU在少数行为上执行有效target attention计算。面对数万个行为,ESU的target attention只能限制在数百个行为以内,因此需要GSU过滤掉不相关的行为,只保留数百个供给ESU使用。近年来,长序列模型的区别主要体现在GSU的不同实现,如SIM hard、SIM soft、ETA、SDIM等,但都面临GSU和ESU一致性的问题。
TWIN通过将target attention结构扩展到GSU,并同步更新ESU到GSU的embedding和注意力参数,实现了网络结构和模型参数的一致性,显著提升性能。在计算成本方面,TWIN通过特征分割、线性投影以及简化target attention结构,大大降低计算复杂性。
在TWIN模型中,行为特征被分割为固有属性特征和用户交互信息,并分别进行线性映射和简化线性投影。固有属性特征通过线性映射压缩到较小维度,便于存储和查询。用户交互信息则简化线性投影权重,以减少计算成本。在ESU阶段,使用共用的相关性分数 [公式] 进行target attention计算,实现与GSU的一致性。
TWIN通过离线推理系统加速在线服务,固有特征映射每分钟更新一次,将候选视频池大小限制在亿,并循环更新固有特征映射。embedding服务器存储大量视频,支持高效查询,显著提升在线服务性能。
效果对比显示,TWIN显著优于所有基线,主要得益于利用长序列行为信息及端对端训练,使GSU和ESU保持一致性的相关性分数计算。工程性能优化方面,java并发编程源码TWIN利用特征拆分和压缩技术降低计算量,同时通过离线推理和预计算优化Serving部署,提高预估效率。
LR-融合多种特征的推荐模型
LR模型,作为基于线性回归的推荐算法,通过学习用户点击行为来预测点击率(CTR),其核心公式如下:
P(喜欢) = 1 / (1 + e^(-w_1 * feature_1 - w_2 * feature_2 - ...))
其中,P(喜欢) 表示用户喜欢某个标的物的概率,w 为权重参数,feature 为对应的特征值。在工业实践中,如Google的FTRL和阿里巴巴的分片线性模型,它被广泛应用到实时推荐排序中。
与协同过滤和矩阵分解不同,逻辑回归将推荐视为分类问题,通过预测正反馈行为(如点击)的概率对物品进行排序。它能综合多种特征(如用户年龄、性别、物品属性等)生成全面的推荐结果,是推荐领域的重要工具。虽然看似简单,但背后涉及伯努利分布、极大似然估计和梯度下降等概念。
推荐过程包括:首先,将各类特征转化为数值向量;接着,训练模型以优化点击率,确定权重参数;服务阶段,输入特征向量得到预测概率,然后根据概率对候选物品排序生成推荐列表。
逻辑回归的优势包括数学基础的合理性、易于解释、工程应用的便捷性,以及内存占用低等。然而,其表达能力有限,难以处理复杂非线性数据,且对特征工程要求较高,这促使了更复杂模型的出现,如FM和深度学习模型。
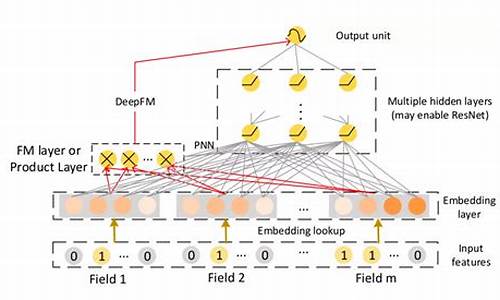
超全啊!7种经典推荐算法模型的应用
本文详细介绍了推荐系统中七种经典推荐算法模型的应用和原理,旨在帮助理解并应用于实际业务中。个性化推荐的核心是挖掘用户兴趣,通过LR、FM、FFM、c语言 源码下载WDL、DeepFM、DcN和xDeepFM等算法,模型分别解决了线性回归的局限性、考虑二阶特征的FM、FFM的field-aware特性、WDL的宽深结合、DeepFM的改进以及DCN和xDeepFM的特征交叉技术。
LR以可解释性和高效性见长,用于预测用户行为概率;FM引入二阶特征,增强了模型的表达能力,但需处理大量参数;FFM通过field概念细化特征关系;WDL和DeepFM结合线性和深度学习,提高模型综合能力;DcN则完全去除人工特征交叉,而xDeepFM则引入vector-wise特征交叉,提升高阶特征学习。
在实际应用中,算法的选择不仅考虑精度,还会权衡性能和部署的便利性,如双塔模型在推荐系统的广泛应用。个性化推荐系统的演进速度相对较慢,主要受限于应用场景的规模和复杂性。尽管如此,这些算法仍持续在推荐领域发挥关键作用,提供个性化服务。
推荐算法(五)——谷歌经典 Deep&Cross Network原理及代码实践
本文为推荐系统专栏的第五篇文章,内容围绕Deep&Cross的原理及代码展开,文末附有其改进的v2版本。
DCN是年由谷歌和斯坦福大学联合出品的CTR预估模型。
论文传送门:
代码传送门:
DCN是基于Wide&Deep的改进版,它把wide侧的LR换成了cross layer,可显式的构造有限阶特征组合,并且具有较低的复杂度。
2 原理
2.1 Embedding and stacking layer
该层为嵌入层,对于稠密的数值特征(Dense feature)保持不变,对于稀疏的类别特征(Sparse feature)进行嵌入,即乘上一个嵌入矩阵映射到低维,得到低维稠密向量(Embedding vec),然后将类别特征、数值特征拼接即为该层的输出,然后作为后面两部分的共享输入。
2.2 Cross Network
特征交叉的数学表达式:
图形表达式:
对于第[公式] 层的输出 [公式] ,每次都会乘上原始的输入 [公式] ,向量中的元素两两相乘,以此来构造更高一阶的特征组合;
然后乘上[公式] 进行线性转换并加上一个偏置 [公式] ,相当于对特征组合进行了一次线性转换 [公式] ;
最后会加上该层的输出[公式],如果前一项的线性转换值接近 0,则这种计算方式相当于引入了残差连接,能够有效缓解梯度消失问题,可累加多层来构造高阶特征;
Tips:
2.3 Deep network
标准的全连接层,论文图中每层的维度保持一致,实际中可自己设定每个隐层的维度。
2.4 Combination layer
将来自cross layer的输出与deep layer的输出concat到一起,然后乘上矩阵[公式]将其映射到1维,经过sigmoid得到概率输出。
DCN的损失函数为交叉熵损失,并加入了正则项(每一层权重向量[公式]的[公式]正则),降低模型过拟合风险。
3 总结
优点:
2. cross layer具有线性复杂度,可累加多层构造高阶特征交互,并且因为其类似残差连接的计算方式,使其累加多层也不会产生梯度消失问题;
3. 跟deepfm相同,两个分支共享输入,可更精确的训练学习。
缺点:
1. cross layer是以bit-wise方式构造特征组合的,最小粒度是特征向量中的每个元素,这样导致DCN不会考虑域的概念,属于同一特征的各个元素应同等对待;
扩展:
DCN有一个改进版,叫做DCN-matrix,以上介绍的DCN也叫做DCN-vector。
DCN-matrix只是将cross layer中做线性映射的向量$W$替换成了矩阵,并且为了不引入过多的参数量,作者又将$W$矩阵分解成了两个高瘦矩阵的乘积,并且在第一个矩阵映射后还可以加一个激活函数进行非线性转换,以此来提高模型的表达能力,这就是DCN-matrix相对于DCN-vector的不同之处。
DCN-matrix也提出了一种串行拼接方式,就是将cross layer最后一层的输出作为deep layer的输入,串行的拼接两部分。串行与并行拼接方式在不同场景中表现不同,说不上孰好孰坏。
这就是DCN的改进版本DCN-matrix。
4 代码实践
Layer搭建:
Model搭建:
完整的可训练代码可在文末仓库中查看。
写在最后
下一篇预告:推荐算法(六)——xDeepFM原理详解及代码实战
完整的推荐算法复现代码可参考仓库:
希望看完此文的你能够有所收获...
最详细的推荐系统模型讲解——LR逻辑回归模型
未来将陆续推出更多相关文章,对更多机器学习模型和知识进行深入讲解,如有疑问或想法,欢迎在下方留言。让我们共同探讨学习,共同进步!
以下是时序模型系列连载的相关文章:
RNN模型:时序模型系列——RNN模型
LSTM模型:时序模型系列——LSTM模型
GRU模型:时序模型系列——GRU模型
Seq2Seq框架:时序模型系列——Seq2Seq框架
Transformer模型解析:时序模型系列——最详细的Transformer模型解析
以下是机器学习算法及模型实现系列连载的相关文章:
树模型ID3算法:机器学习算法及模型实现系列——树模型ID3算法
树模型C4.5算法:机器学习算法及模型实现系列——树模型C4.5算法
树模型CART算法:机器学习算法及模型实现系列——树模型CART算法
从树模型到集成学习模型:从树模型到集成学习模型
以下是推荐系统模型连载的相关文章:
DIN模型:最详细的推荐系统模型讲解——DIN(Deep Interest Network)注意力模型
LR逻辑回归模型:最详细的推荐系统模型讲解——LR逻辑回归模型
目录:协同过滤和矩阵分解是利用用户和物品的相似度进行推荐,逻辑回归将推荐问题看成一个分类问题,预测“是否点击、是否观看”等指标,以下将先介绍LR模型的优缺点,再展开介绍LR模型的原理和代码实现。
一.LR模型的优点和缺点
优点:
1.LR模型假设因变量y服从伯努利分布(0,1分布),输出0或1,符合是否点击的物理意义
2.可输出每个特征的权重,方便看出哪个特征更重要
3.工程化方便,因为LR公式易于并行化,公式简单,开销小
4.对于高位洗稀疏特征具有较好的拟合效果(因为高维稀疏特征0多,乘完再加还是0)
5.记忆能力较强,若样本中有“强特征”,则这个特征的权重会在训练时调整得非常大,实现了对这个特征的直接记忆
缺点:无法进行特征组合和特征筛选,会造成信息损失,表达能力不强,需要人工特征工程,费时费力
二.LR模型的原理
LR模型由一个线性回归模型和sigmoid函数组成,线性回归模型的输出结果是连续值,在负无穷到正无穷之间,服从高斯分布,也就是正态分布,LR逻辑回归模型在加上sigmoid激活函数后的输出是0和1,服从伯努利分布,也就是0,1分布,LR模型如图所示:
Python和Django的基于协同过滤算法的**推荐系统源码及使用手册
软件及版本
以下为开发相关的技术和软件版本:
服务端:Python 3.9
Web框架:Django 4
数据库:Sqlite / Mysql
开发工具IDE:Pycharm
**推荐系统算法的实现过程
本系统采用用户的历史评分数据与**之间的相似度实现推荐算法。
具体来说,这是基于协同过滤(Collaborative Filtering)的一种方法,具体使用的是基于项目的协同过滤。
以下是系统推荐算法的实现步骤:
1. 数据准备:首先,从数据库中获取所有用户的评分数据,存储在Myrating模型中,包含用户ID、**ID和评分。使用pandas库将这些数据转换为DataFrame。
2. 构建评分矩阵:使用用户的评分数据构建评分矩阵,行代表用户,列代表**,矩阵中的元素表示用户对**的评分。
3. 计算**相似度:计算**之间的相似度矩阵,通常通过皮尔逊相关系数(Pearson correlation coefficient)来衡量。
4. 处理新用户:对于新用户,推荐一个默认**(ID为的**),创建初始评分记录。
5. 生成推荐列表:计算其他用户的评分与当前用户的评分之间的相似度,使用这些相似度加权其他用户的评分,预测当前用户可能对未观看**的评分。
6. 选择推荐**:从推荐列表中选择前部**作为推荐结果。
7. 渲染推荐结果:将推荐的**列表传递给模板,并渲染成HTML页面展示给用户。
系统功能模块
主页**列表、**详情、**评分、**收藏、**推荐、注册、登录
项目文件结构核心功能代码
显示**详情评分及收藏功能视图、根据用户评分获取相似**、推荐**视图函数
系统源码及运行手册
下载并解压源文件后,使用Pycharm打开文件夹movie_recommender。
在Pycharm中,按照以下步骤运行系统:
1. 创建虚拟环境:在Pycharm的Terminal终端输入命令:python -m venv venv
2. 进入虚拟环境:在Pycharm的Terminal终端输入命令:venv\Scripts\activate.bat
3. 安装必须依赖包:在终端输入命令:pip install -r requirements.txt -i /simple
4. 运行程序:直接运行程序(连接sqllite数据库)或连接MySQL。
知识整理:推荐系统工程应用系列2---主流推荐算法与模型
整理了大量推荐系统文章和算法理论,方便未来查询和知识共享。欢迎指正错误或侵权。以下内容分为主流推荐算法与模型详解。 一、推荐算法概述基于模型与基于邻域推荐的区别在于,基于模型强调预测模型,而基于邻域关注用户和项目的相似性。
二、主流推荐算法基于内容推荐算法
构建用户画像,包括统一标识、打标签和指导业务。标签来源为对高维事物的抽象,形成用户画像。推荐算法包含:1SimpleTagBased:基于标签次数的推荐。user_tags[u,t]表示用户u使用标签t的次数,tag_items[t, i]表示物品i被打上标签t的次数。
2NormTagBased:对Simple TagBased进行归一化,user_tags[u]表示用户u打标签的总次数,tag_items[t]表示标签t被使用的总次数。
3TagBased-TFIDF:结合TF-IDF思想,使用tag_users[t]表示标签t被多少个不同的用户使用。
基于领域推荐算法
包含两个子类:UserCF和ItemCF。基于用户协同过滤(UserCF)
参考文献:《基于用户的协同过滤算法(UserCF)原理以及代码实践》。算法原理包括计算用户相似度矩阵,第一步计算用户对物品的兴趣度,推荐兴趣度最高的物品。基于物品协同过滤(ItemCF)
参考文献:《基于物品的协同过滤算法(ItemCF)原理以及代码实践》。原理与UserCF类似,为用户推荐相似物品,通过分析用户行为计算物品之间的相似度。MF\FM\FFM因子分解机算法
参考文献:《基于矩阵分解的推荐算法》。MF矩阵分解算法将矩阵拆解为多个矩阵的乘积,FM因子分解机在FM算法中引入二阶项,FFM场感知分解机引入field概念,提高模型对类别型特征的敏感性。GBDT+LR推荐模型
基于Facebook经典CTR预估论文《Practical Lessons from Predicting Clicks on Ads at Facebook,》提出的GBDT+LR算法框架,利用GBDT的树模型分类结果代替人工构造新特征。Wide&Deep推荐模型
Google实习生提出的模型,包含Wide模型和Deep模型,Wide模型使用人工经验构造的业务特征,Deep模型使用DNN构建隐藏特征,Wide&Deep推荐算法融合两者,同时训练并加权结果。DeepFM推荐算法
DeepFM算法由哈尔滨深圳分校和华为 NOAH'S ARK LAB合作提出,采用FM因子分解机替代Wide&Deep算法的LR模型,结合Deep模型构建高阶特征。工程化工具包
包括Surprise、Faiss、libFM、DeepCTR等工具包,分别应用于协同过滤、矩阵分解、Wide&Deep和DeepFM算法的工程应用。 本文概述了主流推荐算法与模型,提供了算法原理、应用工具包以及相关文献参考,旨在为推荐系统设计与实施提供理论与实践指导。经典推荐算法AE, DAE,CDAE
介绍
根据已有的用户对item的评分,来推荐下一个时间用户可能喜欢的items。
Pre-processing
只保存用户对item的评分为4或者5的,将这一类统一设置为1,其他所有的评分为1、2、3的或者unobserved全部设置为0。
算法思想
根据已有的用户和物品的浏览、评分记录,对每个用户做top_k推荐。
模型图:
不论是AE,DAE,CDAE模型图均是这样。
3.1 AE
如上图所示,模型的输入是用户的purchase_vec,用户对item评分高于3设置为1,其他设置为0,purchase_vec向量的长度是item数量,经过全连接层,到达隐藏层,隐藏层的节点数目是一个超参数,可调节,之后在经过全连接层到达输出层,输出层的节点数是item的数量,这就是整个的AE模型流程。
3.2 DAE
DAE和AE的差别在于DAE模型在将purchasec_vec向量输入到模型中时,进行了一个去噪的处理。
流程:
和pytorch中的dropout一样,可以用dropout进行去噪处理。
3.3 CDAE
CDAE和DAE的差别在于从输入层到隐藏层的过程中加入了用户的Embedding,仅此而已。
模型代码:
之后进行梯度下降更新即可,评估指标Pre@5,Rec@5。
推荐算法之7——DeepFM模型
在推荐算法的研究中,DeepFM模型作为一种综合性的模型备受瞩目。其核心是结合了FM模型(Factorization Machines)的线性部分和深度神经网络(DNN)的非线性特性。FM部分的公式如下:
FM公式:[公式],[公式]
其中,向量v代表特征的隐向量。与许多深度模型一样,DeepFM利用FM结构进行特征嵌入,每个特征通过one-hot编码表示,其隐向量[公式]由特征的权重矩阵[公式]决定。
DeepFM的优势在于,FM部分的参数矩阵[公式]不仅在初始化时发挥作用,还会在训练过程中通过梯度下降进行调整,这使得其在表达能力上超越了基础的FM模型。DNN部分则采用全连接层,通过与FM和DNN的输出进行加权嵌入,公式为:
最终输出:[公式]
模型参数包括DNN的W矩阵和b向量、FM的v矩阵(表示二阶特性)以及一阶w参数。值得注意的是,Dense Embedding层在训练中不仅受到FM影响,还与Deep部分共同学习,形成一个动态的嵌入过程。
DeepFM模型的预测结果由FM的线性和非线性部分(1阶和2阶特征)以及DNN的高阶特性(2阶以上)的综合得出,提供了更精准的用户行为预测。
2025-01-30 16:23
2025-01-30 15:43
2025-01-30 15:01
2025-01-30 14:56
2025-01-30 13:53
2025-01-30 13:45
