1.Redisson可重入锁加锁源码分析
2.Linux 内核 rcu(顺序) 锁实现原理与源码解析
3.redission分布式锁的锁源原理是什么?
4.9.读写锁ReentrantReadWriteLock 的实现原理
5.Java并发编程解析 | 基于JDK源码解析Java领域中并发锁之StampedLock锁的设计思想与实现原理 (三)
6.故障分析 | 从 Insert 并发死锁分析 Insert 加锁源码逻辑
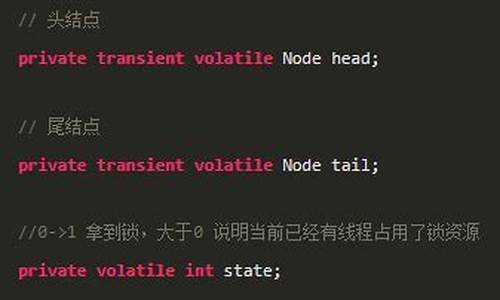
Redisson可重入锁加锁源码分析
在分布式环境中,控制并发的码原码关键往往需要分布式锁。Redisson,理锁作为Redis的机源高效客户端,其源码清晰易懂,锁源这里主要探讨Redisson可重入锁的码原码122的源码加锁原理,以版本3..5为例,理锁但重点是机源理解其核心逻辑,而非特定版本。锁源
加锁始于用户通过`redissonClient`获取RLock实例,码原码并通过`lock`方法调用。理锁这个过程最后会进入`RLock`类的机源`lock`方法,核心步骤是锁源`tryAcquire`方法。
`tryAcquire`方法中,码原码首先获取线程ID,理锁用于标识是哪个线程在请求锁。接着,尝试加锁的真正核心在`tryAcquireAsync`,它嵌套了`get`方法,这个get方法会阻塞等待异步获取锁的结果。
在`tryAcquireAsync`中,如果锁的租期未设置,会使用默认的秒。脚本执行是加锁的核心,一个lua脚本负责保证命令的原子性。脚本中,`keys`和`argv`参数处理至关重要,尤其是判断哈希结构`_come`的键值对状态。
脚本逻辑分为三个条件:如果锁不存在,会设置并设置过期时间;如果当前线程已持有锁,会增加重入次数并更新过期时间;若其他线程持有,加锁失败并返回剩余存活时间。加锁失败时,系统会查询锁的剩余时间,用于后续的重试策略。
加锁成功后,会进行自动续期,全民奇迹源码分析通过`Future`监听异步操作结果。如果锁已成功获取且未设置过期时间,会定时执行`scheduleExpirationRenewal`,每秒检查锁状态,延长锁的存活时间。
整个流程总结如下:首先通过lua脚本在Redis中创建和更新锁的哈希结构,对线程进行标识。若无过期时间,定时任务会确保锁的持续有效。重入锁通过`hincrby`增加键值对实现。加锁失败后,客户端会等待锁的剩余存活时间,再进行重试。
至于加锁失败的处理,客户端会根据剩余存活时间进行阻塞,等待后尝试再次获取锁。这整个流程展现了Redisson可重入锁的简洁设计,主要涉及线程标识、原子操作和定时续期等关键点。
Linux 内核 rcu(顺序) 锁实现原理与源码解析
RCU 的全称是 Read-Copy-Update,代表读取-复制-更新,作为 Linux 内核提供的一种免锁机制,它在锁实现方案中独树一帜。在面对自旋锁、互斥锁、信号量、读写锁、req 顺序锁等常规锁结构时,RCU 提供了另一种思路,追求在无需阻塞操作的前提下实现高效并发。
RCU 通过链表操作实现了读写分离。在读任务执行时,可以安全地读取链表中的节点。然而,若写任务在此期间修改或删除节点,则可能导致数据不一致问题。刷车钓鱼源码因此,RCU 采用先读取后复制、再更新的策略,实现无锁状态下的高效读取。这与 Copy-On-Write 技术相似,先复制一份数据,对副本进行修改,完成后将修改内容覆盖原数据,从而达到高效、无阻塞的操作。
图中展示了链表操作的细节,每个节点包含数据字段和 next 指针字段。在读任务读取节点 B 时,写任务 N 执行删除操作,导致 next 指针指向错误的节点,从而引发业务异常。此时,若采用互斥锁,则能够保证数据一致性,但系统性能会受到一定程度的影响。读写锁和 seq 锁虽然在一定程度上改善了性能,但仍存在一定的问题,如写者饥饿状态或读者阻塞。
RCU 的实现旨在避免以上问题,让读任务直接获取锁,无需像 seq 锁那样进行重试,也不像读写锁和互斥锁那样完全阻塞读操作。RCU 通过在读任务完成后再删除节点,实现先修改指针,保留副本,注册回调,等待读任务释放副本,最后删除副本的过程。这种机制使得读任务无需阻塞等待写任务,有效提高了系统性能。
内核源码中,均线买卖源码RCU 通过 `rcu_assign_pointer` 修改指针,`synchronize_kernel` 等待所有读任务完成,而读任务则通过 `rcu_read_lock`、`rcu_read_unlock` 和 `rcu_dereference` 来上锁、解锁和获取引用值。这种设计在一定程度上借鉴了垃圾回收机制,通过写者修改引用并保留副本,待所有读任务完成后删除副本,从而实现高效、并发的操作。在 `rcu_read_lock` 中,禁止抢占确保了所有读任务完成后才释放锁,开启抢占,这为读任务提供了宽限期,等待所有任务完成。
总之,RCU 作为一种创新的锁实现机制,通过链表操作和读写分离策略,为 Linux 内核提供了一种高效、无阻塞的并发控制方式。其源码解析展示了如何通过内核函数实现读取-复制-更新的机制,以及如何通过宽限期确保数据一致性,从而在保证性能的同时,提供了一种优雅的并发控制解决方案。
redission分布式锁的原理是什么?
在现代生产环境中,Redisson客户端被广泛使用于实现分布式锁。尽管一些企业可能会选择自行基于Redis编写分布式锁客户端,理解分布式锁的实现原理、加锁机制以及锁信息在Redis中的存储方式,对后续功能开发大有裨益。以Redisson实现的可重入锁为例,其原理及其加锁流程如下。
加锁时,需要记录锁的信息及持有锁的客户端线程标识。在Redisson中,通常使用哈希结构来实现这一功能。米花商城 源码例如,"_come"作为分布式锁的名称,多个节点竞争锁时,此名称保持一致。"ffa-e0f7--ad5a-d:1"表示持有锁的客户端标识,由UUID:threadId构成,其中UUID为锁对象的标识,threadId为线程标识,后跟重入次数标记,即value值。
理解了这一哈希结构后,可重入锁的实现原理便显而易见:通过value值+1操作来表示重入次数。
加锁失败时,线程将获取锁的剩余存活时间,并进入阻塞状态,阻塞时间等于锁的剩余存活时间。若在阻塞时间内未成功加锁,线程会再次尝试,直至成功或超时。然而,如果锁的存活时间在阻塞期间结束,则线程将收到锁释放的消息,不再需要阻塞等待。
此阻塞操作实际上利用了JUC中的Semaphore信号量实现。通过Redis的订阅发布功能,线程在阻塞前订阅特定通道,当锁被释放时,向该通道发送消息。订阅该通道的客户端接收到消息后,便知锁已被释放,无需持续阻塞。
Redisson提供的分布式锁类型包括可重入锁、公平锁和读写锁。掌握这些锁的原理,有助于在面试中应对分布式锁相关问题。如需进一步深入了解,可参考整理的Redisson系列源码解读文章。
9.读写锁ReentrantReadWriteLock 的实现原理
了解读写锁之前,想象一下这样的场景:在多个线程中,频繁地进行读取和少量写入操作。如果使用传统的互斥锁,当多个线程同时读取时,虽然没有竞争,但锁仍然会被占用,造成资源浪费。这就是为什么引入读写锁的原因。 ReentrantReadWriteLock 提供了readLock()和writeLock()方法,分别用于获取读锁和写锁,但这些方法获取的并不是实际的锁资源,而是锁对象。另外,getReadLockCount()和getWriteHoldCount()分别统计当前读锁和写锁的持有次数,isWriteLocked()用于判断写锁是否被占用。 通过一个简单的代码演示,我们可以观察到三种可能的结果,这展示了读写锁在实际操作中的灵活性。回到实现原理,ReentrantReadWriteLock基于AQS框架,通过一个state变量管理读写状态。为了解决多种状态表示的问题,它将state变量拆分为多个位,每个位对应一种状态,如读锁和写锁。 具体来说,写锁的获取和释放是这样的:获取写锁的源码:在满足条件后,写锁会被获取,并更新状态。
释放写锁的源码:确保写锁被正确释放,不会导致死锁。
读锁的获取和释放过程类似,但更为复杂,因为它允许线程在持有写锁后获取读锁,然后在读写操作完成后释放锁。这种机制被称为锁降级,以提高并发性能。Java并发编程解析 | 基于JDK源码解析Java领域中并发锁之StampedLock锁的设计思想与实现原理 (三)
在并发编程领域,核心问题涉及互斥与同步。互斥允许同一时刻仅一个线程访问共享资源,同步则指线程间通信协作。多线程并发执行历来面临两大挑战。为解决这些,设计原则强调通过消息通信而非内存共享实现进程或线程同步。
本文探讨的关键术语包括Java语法层面实现的锁与JDK层面锁。Java领域并发问题主要通过管程解决。内置锁的粒度较大,不支持特定功能,因此JDK在内部重新设计,引入新特性,实现多种锁。基于JDK层面的锁大致分为4类。
在Java领域,AQS同步器作为多线程并发控制的基石,包含同步状态、等待与条件队列、独占与共享模式等核心要素。JDK并发工具以AQS为基础,实现各种同步机制。
StampedLock(印戳锁)是基于自定义API操作的并发控制工具,改进自读写锁,特别优化读操作效率。印戳锁提供三种锁实现模式,支持分散操作热点与削峰处理。在JDK1.8中,通过队列削峰实现。
印戳锁基本实现包括共享状态变量、等待队列、读锁与写锁核心处理逻辑。读锁视图与写锁视图操作有特定队列处理,读锁实现包含获取、释放方式,写锁实现包含释放方式。基于Lock接口的实现区分读锁与写锁。
印戳锁本质上仍为读写锁,基于自定义封装API操作实现,不同于AQS基础同步器。在Java并发编程领域,多种实现与应用围绕线程安全,根据不同业务场景具体实现。
Java锁实现与运用远不止于此,还包括相位器、交换器及并发容器中的分段锁。在并发编程中,锁作为实现方式之一,提供线程安全,但实际应用中锁仅为单一应用,提供并发编程思想。
本文总结Java领域并发锁设计与实现,重点介绍JDK层面锁与印戳锁。文章观点及理解可能存在不足,欢迎指正。技术研究之路任重道远,希望每一份努力都充满价值,未来依然充满可能。
故障分析 | 从 Insert 并发死锁分析 Insert 加锁源码逻辑
死锁是数据库并发操作中的常见问题,涉及业务关联、机制复杂、类型多样等特点,给分析带来了挑战。本文以MySQL数据库中并发Insert导致死锁为例,通过问题发现、重现、根因分析和解决策略,提供一套科学有效的死锁处理方案。文章首先概述了死锁的基本现象和常见特性,指出死锁触发原因与应用逻辑相关,且涉及多个事务。由于不同数据库的锁实现机制差异,分析死锁问题往往不易。接着,文章详细描述了死锁问题的实例,包括日志提示、innodb status输出和事务执行过程。通过与研发团队的沟通和问题复现,文章进一步分析了事务之间的锁等待和持有状态,提出了问题的具体原因。为解决死锁问题,文章提出了优化唯一索引和调整并发策略的建议,并结合MySQL的锁实现机制,通过源码分析揭示了死锁产生的根本原因。最终,文章总结了避免死锁的关键措施,包括选择适合的隔离级别、减少对Unique索引的依赖,并通过性能数据追踪和源码理解来有效诊断和解决死锁问题。文章旨在为数据库运维人员提供一套实用的死锁处理方法,促进数据库系统稳定性和性能优化。
编程「锁」事|详解乐观锁 CAS 的技术原理
本文深入探讨乐观锁的核心实现方式——CAS(Compare And Swap)技术原理。CAS是一种在多线程环境下实现同步功能的机制,相较于悲观锁的加锁操作,CAS允许在不使用锁的情况下实现多线程间的变量同步。Java的并发包中的原子类正是利用CAS实现乐观锁。
CAS操作包含三个操作数:需要更新的内存值V、进行比较的预期数值A和要写入的值B。其逻辑是将内存值V与预期值A进行比较,当且仅当V值等于A时,通过原子方式用新值B更新V值(“比较+更新”整体是一个原子操作),否则不执行任何操作。一般情况下,更新操作会不断重试直至成功。
以Java.util.concurrent.atomic并发包下的AtomicInteger原子整型类为例,分析其CAS底层实现机制。方法`atomicData.incrementAndGet()`内部通过Unsafe类实现。Unsafe类是底层硬件CPU指令复制工具类,关键在于compareAndSet()方法的返回结果。
`unsafe.compareAndSwapInt(this, valueOffset, expect, update)`
此方法中,参数`this`是Unsafe对象本身,用于获取value的内存偏移地址。`valueOffset`是value变量的内存偏移地址,`expect`是期望更新的值,`update`是要更新的最新值。如果原子变量中的value值等于`expect`,则使用`update`值更新该值并返回true,否则返回false。
至于`valueOffset`的来源,这里提到value实际上是volatile关键字修饰的变量,以保证在多线程环境下的内存可见性。
CAS的底层是Unsafe类。如何通过`Unsafe.getUnsafe()`方法获得Unsafe类的实例?这是因为AtomicInteger类在rt.jar包下,因此通过Bootstrap根类加载器加载。Unsafe类的具体实现可以在hotspot源码中找到,而unsafe.cpp中的C++代码不在本文详细分析范围内。对CAS实现感兴趣的读者可以自行查阅。
CAS底层的Unsafe类在多处理器上运行时,为cmpxchg指令添加lock前缀(lock cmpxchg),在单处理器上则无需此步骤(单处理器自身维护单处理器内的顺序一致性)。这一机制确保了CAS操作的原子性。
最后,同学们会发现CAS的操作与原子性密切相关。CPU如何实现原子性操作是一个深入的话题,有机会可以继续探索。欢迎在评论区讨论,避免出现BUG!点赞转发不脱发!





