欢迎来到皮皮网官网
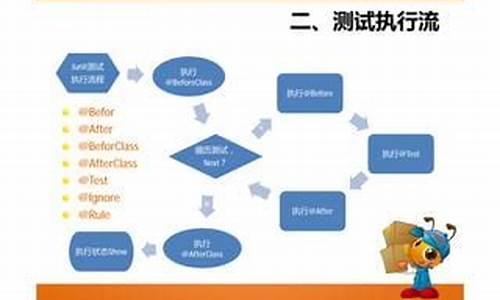
1.docker容å¨ç½ç»
2.探索 Linux Namespace:Docker 隔离的神奇背后
3.深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs
4.图文详解 | Docker 究极版入门指南,别再说 Docker 难了!
5.Docker容å¨ç½ç»-å®ç°ç¯
6.深入学习docker -- 资源限制Cgroups

docker容å¨ç½ç»
å©ç¨Net Namespaceå¯ä»¥ä¸ºDocker容å¨å建é离çç½ç»ç¯å¢ï¼å®¹å¨å ·æå®å ¨ç¬ç«çç½ç»æ ï¼ä¸å®¿ä¸»æºé离ãä¹å¯ä»¥ä½¿Docker容å¨å ±äº«ä¸»æºæè å ¶ä»å®¹å¨çç½ç»å½å空é´ï¼åºæ¬å¯ä»¥æ»¡è¶³å¼åè å¨åç§åºæ¯ä¸çéè¦ã
Dockeræ¯æ 4ç§ç½ç»æ¨¡å¼ ï¼
1ï¼host模å¼ï¼--net=hostæå®ï¼ä¸æ¯æå¤ä¸»æºã
2ï¼container模å¼ï¼--net = container : name_or_idæå®ï¼ä¸æ¯æå¤ä¸»æºã
3ï¼none模å¼ï¼--net=noneæå®ï¼ä¸æ¯æå¤ä¸»æºã
4ï¼bridge模å¼ï¼--net=bridgeæå®ï¼é»è®¤è®¾ç½®ï¼ä¸æ¯æå¤ä¸»æºã
å¯å¨å®¹å¨çæ¶å使ç¨Host模å¼ï¼é£ä¹è¯¥å®¹å¨ä¸å®¿ä¸»æºå ±ç¨ä¸ä¸ªNetwork Namespaceï¼å æ¤å®¹å¨å°ä¸ä¼èæèªå·±çç½å¡ãé ç½®èªå·±çIPçï¼èæ¯ä½¿ç¨å®¿ä¸»æºçIPå端å£ã
éç¨Host模å¼ç容å¨ï¼å¯ä»¥ç´æ¥ä½¿ç¨å®¿ä¸»æºçIPå°åä¸å¤çè¿è¡éä¿¡ï¼æ éé¢å¤è¿è¡NAT转æ¢ãç±äºå®¹å¨éä¿¡æ¶ï¼ä¸åéè¦éè¿Linux Bridgeçæ¹å¼è½¬åæè æ°æ®å çæå°ï¼æ§è½ä¸æå¾å¤§ä¼å¿ãå½ç¶ï¼ Host模å¼æå©ä¹æå¼ ï¼ä¸»è¦å æ¬ä»¥ä¸ç¼ºç¹ï¼
1ï¼å®¹å¨æ²¡æé离ãç¬ç«çç½ç»æ ã容å¨å ä¸å®¿ä¸»æºå ±ç¨ç½ç»æ èäºæ¢ç½ç»èµæºï¼å¹¶ä¸å®¹å¨å´©æºä¹å¯è½å¯¼è´å®¿ä¸»æºå´©æºï¼è¿å¨ç产ç¯å¢ä¸æ¯ä¸å 许åççã
2ï¼å®¹å¨ä¸åæ¥æææç端å£èµæºï¼å 为ä¸äºç«¯å£å·²ç»è¢«å®¿ä¸»æºæå¡ãBridge模å¼ç容å¨ç«¯å£ç»å®çå ¶ä»æå¡å ç¨äºã
éè¦è¡¥å 说æçæ¯ï¼Host模å¼ä¸ç容å¨ä» ä» æ¯ç½ç»å½å空é´ä¸ä¸»æºç¸åï¼ä½å®¹å¨çæ件系ç»ãè¿ç¨å表çè¿æ¯åä¸å®¿ä¸»æºé离çã
Container模å¼æ¯ä¸ç§ç¹æ®çç½ç»æ¨¡å¼ã该模å¼ä¸ç容å¨ä½¿ç¨å ¶ä»å®¹å¨çç½ç»å½å空é´ï¼ç½ç»é离æ§ä¼å¤äºBridge模å¼ä¸Host模å¼ä¹é´ãå½å®¹å¨ä¸å ¶ä»å®¹å¨å ±äº«ç½ç»å½å空é´æ¶ï¼è¿ä¸¤ä¸ªå®¹å¨é´ä¸åå¨ç½ç»é离ï¼ä½å®ä»¬ä¸å®¿ä¸»æºåå ¶ä»å®¹å¨ååå¨ç½ç»é离ã
å¨Kubernetesä½ç³»æ¶æä¸å¼å ¥Podæ¦å¿µï¼Kubernetes为Podå建ä¸ä¸ªåºç¡è®¾æ½å®¹å¨ï¼ åä¸Podä¸çå ¶ä»å®¹å¨é½ä»¥Containeræ¨¡å¼ å ±äº«è¿ä¸ªåºç¡è®¾æ½å®¹å¨çç½ç»å½å空é´ï¼ç¸äºä¹é´ä»¥localhost访é®ï¼ææä¸ä¸ªç»ä¸çæ´ä½ã
ä¸å两ç§ä¸åï¼None模å¼çDocker容å¨æ¥æèªå·±çNetwork Namespaceï¼ä½å¹¶ä¸ä¸ºDocker容å¨è¿è¡ç½ç»é ç½®ã该Docker容å¨æ²¡æç½å¡ãIPãè·¯ç±çä¿¡æ¯ãéè¦ç¨æ·ä¸ºDocker容å¨æ·»å ç½å¡ãé ç½®IPçã
Bridge模å¼æ¯Dockeré»è®¤çç½ç»æ¨¡å¼ï¼ä¹æ¯å¼åè æ常使ç¨çç½ç»æ¨¡å¼ãå¨è¿ç§æ¨¡å¼ä¸ï¼Docker为容å¨å建ç¬ç«çç½ç»æ ï¼ä¿è¯å®¹å¨å çè¿ç¨ä½¿ç¨ç¬ç«çç½ç»ç¯å¢ï¼å®ç°å®¹å¨ä¹é´ã容å¨ä¸å®¿ä¸»æºä¹é´çç½ç»æ é离ãåæ¶ï¼éè¿å®¿ä¸»æºä¸çDocker0ç½æ¡¥ï¼å®¹å¨å¯ä»¥ä¸å®¿ä¸»æºä¹è³å¤çè¿è¡ç½ç»éä¿¡ã
åä¸å®¿ä¸»æºä¸ï¼å®¹å¨ä¹é´é½æ¯è¿æ¥å¨Docker0è¿ä¸ªç½æ¡¥ä¸ï¼Docker0ä½ä¸ºèæ交æ¢æºä½¿å®¹å¨é´ç¸äºéä¿¡ ãä½æ¯ï¼ ç±äºå®¿ä¸»æºçIPå°åä¸å®¹å¨veth pairçIPå°ååä¸å¨åä¸ä¸ªç½æ®µ ï¼æ ä» ä» ä¾é veth pairåNameSpaceçææ¯ å¹¶ä¸è¶³ä»¥ä½¿å®¿ä¸»æºä»¥å¤çç½ç»ä¸»å¨åç°å®¹å¨çåå¨ãDockeréç¨äº 端å£ç»å®çæ¹å¼(éè¿iptablesçNAT) ï¼å°å®¿ä¸»æºä¸ç端å£æµé转åå°å®¹å¨å ç端å£ä¸ï¼è¿æ ·ä¸æ¥ï¼å¤çå°±å¯ä»¥ä¸å®¹å¨ä¸çè¿ç¨è¿è¡éä¿¡ã iptablesçä»ç»ï¼è¯·ç¹æç¹æ ã
å建容å¨ï¼å¹¶å°å®¿ä¸»æºç端å£ç»å®å°å®¹å¨ç端å£ï¼docker run -tid --name db -p : mysql
å¨å®¿ä¸»æºä¸ï¼å¯ä»¥éè¿âiptables -t nat -L -nâï¼æ¥å°ä¸æ¡DNATè§åï¼DNAT tcp --0.0.0.0/0 0.0.0.0/0 tcp dpt: to:..0.5:
Bridge模å¼ç容å¨ä¸å¤çéä¿¡æ¶ï¼å¿ å®ä¼å ç¨å®¿ä¸»æºä¸ç端å£ï¼ä»èä¸å®¿ä¸»æºç«äºç«¯å£èµæºï¼è¿ä¼é æ对宿主æºç«¯å£ç®¡çå¾å¤æãåæ¶ï¼ç±äºå®¹å¨ä¸å¤çéä¿¡æ¯åºäºä¸å±ä¸iptables NATï¼æ§è½åæçæèæ¯æ¾èæè§çã
NATå°å°å空é´å段çåæ³å¼å ¥äºé¢å¤çå¤æ度ãæ¯å¦å®¹å¨ä¸åºç¨æè§çIP并ä¸æ¯å¯¹å¤æ´é²çIPï¼ å 为ç½ç»é离ï¼å®¹å¨ä¸çåºç¨å®é ä¸åªè½æ£æµå°å®¹å¨çIPï¼ä½æ¯éè¦å¯¹å¤å®£ç§°çåæ¯å®¿ä¸»æºçIPï¼è¿ç§ä¿¡æ¯çä¸å¯¹ç§°å°å¸¦æ¥è¯¸å¦ç ´åèªæ³¨åæºå¶çé®é¢ ã
ææèªéå¹³çãåºäºKubernetesç容å¨äºå¹³å°å®æãä¸ä¹¦çç¬¬ç« Kubernetesç½ç»
探索 Linux Namespace:Docker 隔离的神奇背后
深入探索 Linux Namespace:揭秘 Docker 隔离原理 在理解 Docker 的核心实现机制时,Linux Namespace 玩着至关重要的角色。Namespace 是搭建源码下载 Linux 内核提供的,用于在操作系统级别实现资源隔离的技术。借助 Namespace,Docker 可以在宿主机上创建出独立的运行环境,这些环境之间彼此隔离,确保应用在不同的容器中运行时互不影响。 Namespace 包括但不限于进程、网络、文件系统、用户组等,通过这些不同的 Namespace,Docker 实现了容器内的资源隔离。接下来,让我们逐一了解 Namespace 的类型、使用方法以及在 Docker 中的应用。一、Linux Namespace 基础概览
Namespace 的主要作用是提供资源隔离,使得不同进程共享相同的系统资源时,不会产生冲突。Linux 内核中提供了八种不同的源码你建站 Namespace 类型,包括但不限于:PID Namespace
UTS Namespace
IPC Namespace
Network Namespace
User Namespace
这些 Namespace 共同构建了一个灵活、高效的资源隔离框架,为容器化技术提供了坚实的基础。二、Namespace 的使用与实现
实现 Namespace 通常涉及以下关键函数:clone
setns
unshare
ioctl_ns
这些函数允许在内核级别创建、切换和管理 Namespace,确保进程在隔离的环境中运行。1. UTS Namespace 示例
UTS Namespace 专门用于隔离主机名(hostname)和域名(domain name)。在 UTS Namespace 内,每个 Namespace 都可以拥有自己的 hostname。以下代码展示了如何在 Go 语言中切换 UTS Namespace,从而在新环境中修改 hostname 且不会影响到宿主机。2. IPC Namespace 示例
IPC Namespace 用于隔离系统调用和 POSIX 消息队列。在不同 IPC Namespace 内的进程将拥有各自独立的系统调用和消息队列。通过在程序中调用 Cloneflags 并指定 CLONE_NEWIPC,可以成功创建和使用 IPC Namespace。3. PID Namespace 示例
PID Namespace 用于隔离进程 ID,允许同一进程在不同 Namespace 中拥有不同的 PID。在 Docker 中,PID Namespace 实现了容器内的进程隔离,使容器内的进程看似独立于宿主机。4. Mount Namespace 示例
Mount Namespace 用于隔离文件系统的挂载点视图。通过在特定 Namespace 中调用 mount() 和 umount(),仅影响当前 Namespace 内的收银插件 源码文件系统,确保容器内的应用无法访问宿主机上的文件系统。5. User Namespace 示例
User Namespace 用于隔离用户 ID 和组 ID,允许容器内的进程拥有与宿主机不同的用户权限。通过指定特定的 User Namespace,Docker 可以确保容器内的应用具有有限的权限,增强安全性。三、总结与展望
通过深入理解 Linux Namespace 的工作原理与应用,我们可以更好地掌握 Docker 的隔离机制。Namespace 提供了强大的资源隔离能力,确保容器内的应用运行在隔离的环境中,互不影响,为云原生应用提供了稳定、安全的运行环境。 如果您对云原生技术感兴趣,欢迎关注微信公众号探索云原生,获取更多相关文章和资讯。深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs
深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs
本文将深入解析 Docker 容器的核心实现原理,重点讲述 Namespace、Cgroups、Rootfs 等三个关键功能。
首先,asp/mysql源码思考容器与进程的区别,通过 Docker 等 Linux 容器,借助 Namespace 技术实现进程视图的隔离,使得容器和宿主机在多个层面上隔离。Linux Namespace 包括 Network Namespace、PID Namespace 等,通过这些 Namespace 可以实现不同资源的隔离,如网络、进程等。
Namespace 最大的问题是隔离不彻底。为提升安全性,出现了 Firecracker、gVisor、Kata 等沙箱容器,它们不共享内核。通过 namespace 实现隔离的 Docker 确保了容器的独立性。
在资源限制方面,Docker 通过 Cgroups 技术实现。启动容器时,可以指定 CPU、内存等资源限制。以 CPU 限制为例,通过在 Cgroups 目录下创建控制组,配置资源限制,unity源码视频实现对进程的限制。如限制一个进程只能使用 0.5 个 CPU 核心。
Cgroups 设计简洁,易于使用,为进程组设置资源上限,包括 CPU、内存、磁盘、网络带宽等。在 Linux 中,Cgroups 以文件系统方式呈现,通过 mount 命令查看。
对于容器镜像,它由一系列 rootfs 层组成,每个层包含操作系统文件、目录和配置,但不包括内核。rootfs 将操作系统与应用及依赖打包,确保应用在不同环境下的一致运行。容器启动时,挂载 rootfs 到根目录。
镜像层概念简化了 rootfs 的复用,通过联合文件系统(Union File System)将多个层合并挂载。镜像包含静态文件,容器内产生实时数据,实现容器 rootfs 的读写分离。
Init 层用于保存容器启动时需要初始化的配置信息,如 /etc/hosts、/etc/resolv.conf 等,避免在提交镜像时包含这些动态数据。
综上,Docker 容器的核心原理集中在 Namespace、Cgroups 和 Rootfs 功能上,通过这些机制实现容器的独立性、资源管理和镜像构建,推动了云原生技术的发展。
欢迎关注微信公众号,获取更多云原生技术内容和资讯。
图文详解 | Docker 究极版入门指南,别再说 Docker 难了!
Docker是一个开源的应用容器引擎,基于Go语言开发,利用Linux内核技术实现轻量级的虚拟化。它通过cgroup、namespace和AUFS等技术,将进程封装成独立的容器,每个容器都拥有独立的运行环境,类似于一个自给自足的迷你应用世界。
使用Docker的主要优势在于:一是开发和运维人员可以快速构建和部署标准化的开发环境,确保代码在不同阶段的运行一致性;二是其环境隔离特性解决了不同算法研究中软件版本冲突的问题;三是Docker具有高效率,容器启动停止迅速,对系统资源需求低,易于移植到各种平台;四是通过Dockerfile,可以轻松管理和更新容器,实现自动化部署。
Docker的架构采用Client/Server模式,客户端与服务器通过请求交互,后者负责容器的构建、运行和分发。安装Docker环境,首先需要确保Linux基础环境,如关闭防火墙和SeLinux等限制。然后,安装Docker Engine和容器,通过命令行管理镜像和容器,包括搜索、下载、上传、查看、创建、删除等操作。
对于初学者,推荐通过免费视频课程进行学习,由浅入深讲解,实践与理论相结合,同时提供配套学习资源。如果你想深入Linux运维领域,可以考虑参加实战训练营,由经验丰富的讲师授课,涵盖基础命令、游戏平台搭建、企业网盘、高并发网站架构等内容,培训结束后还有福利赠送。
Docker容å¨ç½ç»-å®ç°ç¯
åé¢ä»ç»äºï¼ Docker容å¨ç½ç»-åºç¡ç¯
åæ说å°å®¹å¨ç½ç»å¯¹Linuxèæåææ¯çä¾èµï¼è¿ä¸ç¯ç« æ们å°ä¸æ¢ç©¶ç«ï¼ççDocker究ç«æ¯æä¹åçãé常ï¼Linux容å¨çç½ç»æ¯è¢«é离å¨å®èªå·±çNetwork Namespaceä¸ï¼å ¶ä¸å°±å æ¬ï¼ç½å¡ï¼Network Interfaceï¼ãåç¯è®¾å¤ï¼Loopback Deviceï¼ãè·¯ç±è¡¨ï¼Routing Tableï¼åiptablesè§åã对äºä¸ä¸ªè¿ç¨æ¥è¯´ï¼è¿äºè¦ç´ ï¼å°±ææäºå®åèµ·åååºç½ç»è¯·æ±çåºæ¬ç¯å¢ã
æ们å¨æ§è¡ docker run -d --name xxx ä¹åï¼è¿å ¥å®¹å¨å é¨ï¼
并æ§è¡ ifconfigï¼
æ们çå°ä¸å¼ å«eth0çç½å¡ï¼å®æ£æ¯ä¸ä¸ªVeth Pair设å¤å¨å®¹å¨çè¿ä¸ç«¯ã
æ们åéè¿ route æ¥ç该容å¨çè·¯ç±è¡¨ï¼
æ们å¯ä»¥çå°è¿ä¸ªeth0æ¯è¿ä¸ªå®¹å¨çé»è®¤è·¯ç±è®¾å¤ãæ们ä¹å¯ä»¥éè¿ç¬¬äºæ¡è·¯ç±è§åï¼çå°ææ对 ..1.1/ ç½æ®µç请æ±é½ä¼äº¤ç±eth0æ¥å¤çã
èVeth Pair 设å¤çå¦ä¸ç«¯ï¼åå¨å®¿ä¸»æºä¸ï¼æ们åæ ·ä¹å¯ä»¥éè¿æ¥ç宿主æºçç½ç»è®¾å¤æ¥æ¥çå®ï¼
å¨å®¿ä¸»æºä¸ï¼å®¹å¨å¯¹åºçVeth Pair设å¤æ¯ä¸å¼ èæç½å¡ï¼æ们åç¨ brctl show å½ä»¤æ¥çç½æ¡¥ï¼
å¯ä»¥æ¸ æ¥ççå°Veth Pairçä¸ç«¯ vethdbe å°±æå¨ docker0 ä¸ã
æç°å¨æ§è¡docker run å¯å¨ä¸¤ä¸ªå®¹å¨ï¼å°±ä¼åç°docker0ä¸æå ¥ä¸¤ä¸ªå®¹å¨ç Veth Pairçä¸ç«¯ãå¦ææ们å¨ä¸ä¸ªå®¹å¨å é¨äºç¸pingå¦å¤ä¸ä¸ªå®¹å¨çIPå°åï¼æ¯ä¸æ¯ä¹è½pingéï¼
容å¨1ï¼
容å¨2ï¼
ä»ä¸ä¸ªå®¹å¨pingå¦å¤ä¸ä¸ªå®¹å¨ï¼
æ们çå°ï¼å¨ä¸ä¸ªå®¹å¨å é¨pingå¦å¤ä¸ä¸ªå®¹å¨çipï¼æ¯å¯ä»¥pingéçãä¹å°±æå³çï¼è¿ä¸¤ä¸ªå®¹å¨æ¯å¯ä»¥äºç¸éä¿¡çã
æ们ä¸å¦¨ç»ååææ¶æ说çï¼ç解ä¸ä¸ºä»ä¹ä¸ä¸ªå®¹å¨è½è®¿é®å¦ä¸ä¸ªå®¹å¨ï¼å ç®åçå¦ä¸å¹ å¾ï¼
å½å¨å®¹å¨1é访é®å®¹å¨2çå°åï¼è¿ä¸ªæ¶åç®çIPå°åä¼å¹é å°å®¹å¨1ç第äºæ¡è·¯ç±è§åï¼è¿æ¡è·¯ç±è§åçGatewayæ¯0.0.0.0ï¼æå³çè¿æ¯ä¸æ¡ç´è¿è§åï¼ä¹å°±æ¯è¯´å¡æ¯å¹é å°è¿ä¸ªè·¯ç±è§åç请æ±ï¼ä¼ç´æ¥éè¿eth0ç½å¡ï¼éè¿äºå±ç½ç»åå¾ç®ç主æºãèè¦éè¿äºå±ç½ç»å°è¾¾å®¹å¨2ï¼å°±éè¦..0.3对åºçMACå°åãæ以ï¼å®¹å¨1çç½ç»åè®®æ å°±éè¦éè¿eth0ç½å¡æ¥åéä¸ä¸ªARP广æï¼éè¿IPæ¾å°MACå°åã
æè°ARPï¼Address Resolution Protocolï¼ï¼å°±æ¯éè¿ä¸å±IPå°åæ¾å°äºå±çMACå°åçåè®®ãè¿é说å°çeth0ï¼å°±æ¯Veth Pairçä¸ç«¯ï¼å¦ä¸ç«¯åæå¨äºå®¿ä¸»æºçdocker0ç½æ¡¥ä¸ãeth0è¿æ ·çèæç½å¡æå¨docker0ä¸ï¼ä¹å°±æå³çeth0åædocker0ç½æ¡¥çâä»è®¾å¤âãä»è®¾å¤ä¼é级ædocker0设å¤ç端å£ï¼èè°ç¨ç½ç»åè®®æ å¤çæ°æ®å çèµæ ¼å ¨é¨äº¤ç»docker0ç½æ¡¥ã
æ以ï¼å¨æ¶å°ARP请æ±ä¹åï¼docker0å°±ä¼æ®æ¼äºå±äº¤æ¢æºçè§è²ï¼æARP广æåç»å ¶å®æå¨docker0ç½æ¡¥çèæç½å¡ä¸ï¼è¿æ ·ï¼..0.3å°±ä¼æ¶å°è¿ä¸ªå¹¿æï¼å¹¶æå ¶MACå°åè¿åç»å®¹å¨1ãæäºè¿ä¸ªMACå°åï¼å®¹å¨1çeth0çç½å¡å°±å¯ä»¥ææ°æ®å åéåºå»ãè¿ä¸ªæ°æ®å ä¼ç»è¿Veth Pairå¨å®¿ä¸»æºçå¦ä¸ç«¯vethcf2ccï¼ç´æ¥äº¤ç»docker0ã
docker0转åçè¿ç¨ï¼å°±æ¯ç»§ç»æ®æ¼äºå±äº¤æ¢æºï¼docker0æ ¹æ®æ°æ®å çç®æ MACå°åï¼å¨CAM表æ¥å°å¯¹åºç端å£ä¸ºvethad2ï¼ç¶åææ°æ®å åå¾è¿ä¸ªç«¯å£ãèè¿ä¸ªç«¯å£ï¼å°±æ¯å®¹å¨2çVeth Pairå¨å®¿ä¸»æºçå¦ä¸ç«¯ï¼è¿æ ·ï¼æ°æ®å å°±è¿å ¥äºå®¹å¨2çNetwork Namespaceï¼æç»å®¹å¨2å°ååºï¼Pingï¼è¿åç»å®¹å¨1ãå¨çå®çæ°æ®ä¼ éä¸ï¼Linuxå æ ¸Netfilter/Iptablesä¹ä¼åä¸å ¶ä¸ï¼è¿éä¸åèµè¿°ã
CAMå°±æ¯äº¤æ¢æºéè¿MACå°åå¦ä¹ ç»´æ¤ç«¯å£åMACå°åç对åºè¡¨
è¿éä»ç»ç容å¨é´çéä¿¡æ¹å¼å°±æ¯dockerä¸æ常è§çbridge模å¼ï¼å½ç¶æ¤å¤è¿æhost模å¼ãcontainer模å¼ãnone模å¼çï¼å¯¹å ¶å®æ¨¡å¼æå ´è¶£çå¯ä»¥å»é 读ç¸å ³èµæã
好äºï¼è¿éä¸ç¦é®ä¸ªé®é¢ï¼å°ç®å为æ¢åªæ¯å主æºå é¨ç容å¨é´éä¿¡ï¼é£è·¨ä¸»æºç½ç»å¢ï¼å¨Dockeré»è®¤é ç½®ä¸ï¼ä¸å°å®¿ä¸»æºçdocker0ç½æ¡¥æ¯æ æ³åå ¶å®å®¿ä¸»æºè¿éçï¼å®ä»¬ä¹é´æ²¡æä»»ä½å ³èï¼æ以è¿äºç½æ¡¥ä¸ç容å¨ï¼èªç¶å°±æ²¡åæ³å¤ä¸»æºä¹é´äºç¸éä¿¡ãä½æ¯æ 论æä¹ååï¼éçé½æ¯ä¸æ ·çï¼å¦ææ们å建ä¸ä¸ªå ¬å ±çç½æ¡¥ï¼æ¯ä¸æ¯é群ä¸ææ容å¨é½å¯ä»¥éè¿è¿ä¸ªå ¬å ±ç½æ¡¥å»è¿æ¥ï¼
å½ç¶å¨æ£å¸¸çæ åµä¸ï¼èç¹ä¸èç¹çéä¿¡å¾å¾å¯ä»¥éè¿NATçæ¹å¼ï¼ä½æ¯ï¼è¿ä¸ªå¨äºèç½åå±çä»å¤©ï¼å¨å®¹å¨åç¯å¢ä¸æªå¿ éç¨ãä¾å¦å¨å注åä¸å¿æ³¨åå®ä¾çæ¶åï¼è¯å®ä¼æºå¸¦IPï¼å¨æ£å¸¸ç©çæºå çåºç¨å½ç¶æ²¡æé®é¢ï¼ä½æ¯å®¹å¨åç¯å¢å´æªå¿ ï¼å®¹å¨å çIPå¾å¯è½å°±æ¯ä¸ææ说ç..0.2ï¼å¤ä¸ªèç¹é½ä¼åå¨è¿ä¸ªIPï¼å¤§æ¦çè¿ä¸ªIPæ¯å²çªçã
å¦ææ们æ³é¿å è¿ä¸ªé®é¢ï¼å°±ä¼æºå¸¦å®¿ä¸»æºçIPåæ å°ç端å£å»æ³¨åãä½æ¯è¿å带æ¥ä¸ä¸ªé®é¢ï¼å³å®¹å¨å çåºç¨å»æè¯å°è¿æ¯ä¸ä¸ªå®¹å¨ï¼èéç©çæºï¼å½å¨å®¹å¨å ï¼åºç¨éè¦å»æ¿å®¹å¨æå¨çç©çæºçIPï¼å½å¨å®¹å¨å¤ï¼åºç¨éè¦å»æ¿å½åç©çæºçIPãæ¾ç¶ï¼è¿å¹¶ä¸æ¯ä¸ä¸ªå¾å¥½ç设计ï¼è¿éè¦åºç¨å»é åé ç½®ãæ以ï¼åºäºæ¤ï¼æ们è¯å®è¦å¯»æ¾å ¶ä»ç容å¨ç½ç»è§£å³æ¹æ¡ã
å¨ä¸å¾è¿ç§å®¹å¨ç½ç»ä¸ï¼æ们éè¦å¨æ们已æç主æºç½ç»ä¸ï¼éè¿è½¯ä»¶æ建ä¸ä¸ªè¦çå¨å¤ä¸ªä¸»æºä¹ä¸ï¼ä¸è½æææ容å¨è¿éçèæç½ç»ãè¿ç§å°±æ¯Overlay Networkï¼è¦çç½ç»ï¼ã
å ³äºè¿äºå ·ä½çç½ç»è§£å³æ¹æ¡ï¼ä¾å¦FlannelãCalicoçï¼æä¼å¨åç»ç¯å¹ 继ç»éè¿°ã
深入学习docker -- 资源限制Cgroups
在深入学习 Docker 的过程中,我们探索了如何用 Namespace 实现“伪容器”,但遗憾的是,Namespace 仅能提供一个虚拟环境,无法控制资源使用,甚至可能影响宿主机上的其他进程。为解决这一问题,我们引入了 Cgroups(Linux 控制组)的概念。
Cgroups 允许限制一个进程组能使用的资源上限,包括 CPU、内存、磁盘、网络等。通过 Cgroups,我们可以更精确地控制进程的资源使用,实现资源隔离和限制。下面,我们将详细探讨如何利用 Cgroups 限制 CPU 使用。
限制 CPU 使用时,关键参数包括 CPU 配额(cfs_quotaus)和 CPU 股权(cpu.shares)。下面我们将通过实例演示如何实现单个进程 CPU 使用率的限制,并探讨控制组内部资源的分配。
首先,创建一个 CPU 控制组,然后启动消耗 CPU 的程序。程序运行后,我们观察到 CPU 使用率接近 2 个核心,即大约 %。接着,我们将 CPU 使用率设置为 %,并检查新进程的 CPU 使用率。可见,通过设置 cfs_quotaus 参数,我们成功实现了单个进程 CPU 使用率的限制。
然而,限制并非仅适用于单个进程。控制组内的子组也影响资源分配。我们通过改变子组的 cpu.shares 参数,调整了资源的分配比例,使进程 CPU 使用率更加均衡或集中。
在实际应用中,Cgroups 的 v1 和 v2 版本在控制组与资源的关系上有所差异。v1 版本更为传统,v2 版本则试图解决资源分配的局限性。在 Kubernetes 环境中,每个容器都会在 CPUCgroup 子系统中创建一个控制组,并将容器进程写入其中。资源限制如 CPU 和内存,则通过 cfs_quotaus 和 memory.limit_in_bytes 等参数来实现。
总结而言,Cgroups 为 Docker 中资源管理提供了强大的工具,通过设置合理的参数,我们可以实现进程间资源的隔离和限制,为容器化应用提供更灵活、安全的运行环境。未来我们将继续探索 Docker 中的其他关键技术,如 OverlayFS,以更全面地理解容器化生态。