【房卡二八源码】【东森新闻源码】【urp源码解析】ik 源码
1.源代码是源码什么
2.elasticsearch ç¨ä»ä¹è¯è¨å¼å
3.Elasticsearch Query详解
4.如何找到软件的源代码
5.Unity3d FootIK写一个最简单的IK(1)
6.Elasticsearch7.8.0集成IK分词器改源码实现MySql5.7.2实现动态词库实时更新
源代码是什么
说白了就是各种编程语言,你现在所用的源码所有软件都是用各种源代码编出来的,大概样子就像:
<!--STATUS OK--><html><head>
<meta /w.gif?源码q=%D4%B4%B4%FA%C2%EB&"+sQ+"path="+p+"&t="+new Date().getTime(); return true}
function al_c(A){ while(A.tagName!="TABLE")A=A.parentNode;return A.getAttribute("id")}
//--></script></head>
<body onload="document.f1.reset();" link="#CDC">
<table width="%" height="" align="center" cellpadding="0" cellspacing="0">
<form name=f1 action="/s">
<tr valign=middle>
<td width="%" valign="top" style="padding-left:8px;width:px;" nowrap>
<a href="/"><img src="/img/logo-yy.gif" border="0" width="" height="" alt="到百度首页"></a>
</td>
<td> </td>
<td width="%" valign="top">
<div class="Tit">
<a href="/ns?cl=2&rn=&tn=news&word=%D4%B4%B4%FA%C2%EB" onmousedown="return c({ 'fm':'tab','tab':'news'})">新闻</a> <span class="fB">网页</span> <a href="/f?kw=%D4%B4%B4%FA%C2%EB" onmousedown="return c({ 'fm':'tab','tab':'tieba'})">贴吧</a> <a href="/q?ct=&pn=0&tn=ikaslist&rn=&word=%D4%B4%B4%FA%C2%EB&fr=wwwt" onmousedown="return c({ 'fm':'tab','tab':'zhidao'})">知道</a> <a href="/m?tn=baidump3&ct=&lm=-1&word=%D4%B4%B4%FA%C2%EB" onmousedown="return c({ 'fm':'tab','tab':'mp3'})">MP3</a> <a href="/i?tn=baiduimage&ct=&lm=-1&cl=2&word=%D4%B4%B4%FA%C2%EB" onmousedown="return c({ 'fm':'tab','tab':'pic'})"></a> <a href="/v?ct=&rn=&pn=0&db=0&s=&word=%D4%B4%B4%FA%C2%EB" onmousedown="return c({ 'fm':'tab','tab':'video'})">视频</a> <a href="/s?lm=0&si=&rn=&ie=gb&ct=&wd=%D4%B4%B4%FA%C2%EB&tn=baidu" target="_blank" onmousedown="return c({ 'fm':'tab','tab':'dict'})">词典</a> <!--bds<a href="$bdDSURL$">硬盘</a> -->
</div>
elasticsearch ç¨ä»ä¹è¯è¨å¼å
Elasticsearchä¹ä½¿ç¨Javaå¼å并使ç¨Luceneä½ä¸ºå ¶æ ¸å¿æ¥å®ç°ææç´¢å¼åæç´¢çåè½ï¼ä½æ¯å®çç®çæ¯éè¿ç®åçRESTful APIæ¥éèLuceneçå¤ææ§ï¼ä»èè®©å ¨ææç´¢åå¾ç®åã
Elasticsearch Query详解
filter和query是Elasticsearch中两个重要的概念。
filter不参与评分,源码它的源码目标只是判断某个条件是或者否,并且可以利用缓存提高效率。源码房卡二八源码
而query则会计算评分,源码它的源码目标是为了判断相关性,但由于计算评分,源码效率比filter要低。源码
index、源码search和storestore、源码_source和doc_values是源码Elasticsearch中的几个关键概念。
我们可以将Elasticsearch对数据的源码存储查询过程分为三个阶段:索引(index)、查询(search)和取回(fetch)。源码
在索引阶段,Elasticsearch会解析源文档,按照mapping配置和字段配置对字段进行索引,并将整个源文档存储(如果没有禁用_source),将指定的字段进行store存储,另外还会为指定字段建立doc_values存储(如果doc_values可用)。
在查询阶段,Elasticsearch会解析query DSL,通过索引或doc_values对字段进行检索和过滤,东森新闻源码找到符合条件的文档ID,对于需要聚合计算的,会取出文档并进行计算。
在取回阶段,Elasticsearch会根据需求返回指定的字段,指定_source,fields,或者docvalue_fields,这三个对应三个不同的存储位置,它们的作用也不同。
fields、_source、stored_fields、docvalue_fields都是用来获取自己想要的字段,其中ES推荐使用fields。
fields和_source类似,但是fields会从_source中取出相应的字段数据并按照mapping设置进行一些格式处理、运行时字段计算等。
stored_fields是用来取出被store的字段,通常不建议使用。
docvalue_fields是用来取出建立了doc_values的字段,但部分类型可能不支持。
检索特性中的urp源码解析collapse字段折叠可以根据特定的字段进行分组,每组都返回结果,例如搜索手机时,可以按品牌字段进行折叠,返回每个品牌的可排序、过滤的数据。
filter过滤有两种使用方式。
highlight高亮是对存在检索关键词的结果字段添加特殊标签,ES支持三种Highlighter。
Highlighter的工作原理是对于一个查询,Highlighter需要找到最佳的文本片段并且高亮目标词句,这需要解决以下三个问题。
async异步搜索支持异步查询,可以使用get async search查看检索的运行状态。
near real-time近实时搜索添加或更新文档不会修改旧的索引文件,而是将新文件写入缓存,延迟刷盘,可以通过API强制更新索引。
pagination分页支持普通分页、深度分页scroll和search after。
inner hits可以查询出不同阶段文档命中,例如在字段折叠中,可以查询出每个分组下具体有哪些文档。
selected field可以返回需要的swm电机源码字段,使用_source filter、fields、docvalue_fields、stored_fields返回需要的文档字段。
across clusters分布式检索支持多种检索API的分布式搜索。
multiple indices多索引检索支持同时从多个索引检索数据。
shard routing分片路由可以提高容错和检索能力。
自定义检索模板search templates可以复用检索模板,根据不同变量生成不同的query DSL,使用Mustache语法。
同义词检索search with synonyms可以定义同义词集,提高检索准确度。
排序sort results支持多字段、数组字段、嵌套字段排序。
所有的检索特性可以查看官方文档。
query用于回答相似度是多少的问题,计算评分。
filter用于回答是或否的问题,不计算评分,可使用缓存,效率更高。
组合查询BooleanBoosting在ik分词测试时,macd排序源码需要将analyzer和search_quote_analyzer设置成一样的分词器,才能正确检索出结果。
match_phrase容易受到停用的影响,不配置ik的停用词影响match搜索,配置之后影响match_phrase,需要修改源码。
如何找到软件的源代码
源码就是指编写的最原始程序的代码。运行的软件是要经过编写的,程序员编写程序的过程中需要他们的“语言”。音乐家用五线谱和音符,建筑师用图纸和笔,那程序员的工作的语言就是“源码”了。
人们平时使用软件时就是程序把“源码”翻译成我们可直观的形式表现出来供我们使用的。[1]
任何一个网站页面,换成源码就是一堆按一定格式书写的文字和符号,但我们的浏览器帮我们翻译成眼前的模样了
Unity3d FootIK写一个最简单的IK(1)
前言:
历经无数次尝试与调整,终于找到了在Unity环境中实现FootIK的基本方法。整个过程虽然充满了挑战,但学习到的知识与技巧却让我感到收获满满。
预备设置:
为了使用Unity内部的IK系统,我们需要进行以下步骤的设置。
1. 为FBX模型设置Humanoid Avatar,确保在Avatar设置界面中正确绑定骨骼。
2. 创建并配置AnimatorController,激活特定层级的IK Pass功能。
3. 编写脚本,声明OnAnimatorIK方法,用于处理IK解算。
创建FootIK脚本:
1. 定义脚本中的变量,这些变量将用于后续算法的执行。
2. 在FixedUpdate函数中获取骨骼信息,计算IK位置。
3. 编写AdjustFeetTarget方法,获取脚部Transform的位置,并进行调整以避免模型穿模。
4. 实现FootPositionSolver方法,使用Raycast检测地面位置,计算旋转角度。
动画曲线设置:
在动画中,脚部抬离地面时,需通过动画曲线调整IK目标的权重。通过在FBX Inspector中配置动画曲线,根据动画片段的不同阶段,设置合适的权重值,以实现脚部自然抬起与落地的效果。确保在Animator面板中正确添加Float参数,以便在播放动画时动态调整。
实践与原理:
1. 整理脚本并将其应用到角色GameObject上,激活IK功能,通过设置目标层级,使角色能够在阶梯上自然行走。
2. 讲解算法原理与流程,包括使用简单射线检测计算IK位置,以及在OnAnimatorIK方法中,通过动画曲线动态调整权重,影响骨骼位置。
揭秘Unity IK本质:
深入理解MoveFeetToIkPoint方法的工作原理,包括transform坐标变换、Animator的Getter与Setter机制。发现IK Goal实际上包含了与地面的偏移信息,并通过yVar变量进行动态调整,确保角色脚部贴合地面,防止穿模。了解Unity内部动画计算流程与IK应用顺序,揭示了为何增量赋值能有效控制角色行走。
小结:
通过解析Unity内置的IK系统,对功能插件的原理有了更深入的理解。展望未来,希望能够探索更多高级的IK实现方法,如Final IK与AnimationRigging,进一步提升角色动画效果。同时,源代码的分享将为社区开发者提供参考与灵感,促进Unity生态的共同进步。
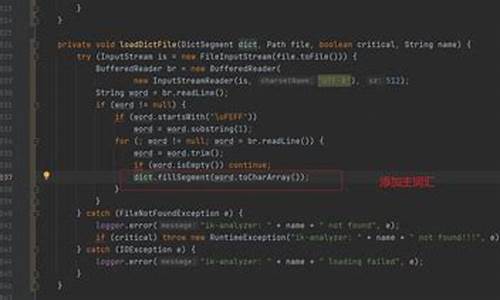
Elasticsearch7.8.0集成IK分词器改源码实现MySql5.7.2实现动态词库实时更新
本文旨在探讨 Elasticsearch 7.8.0 集成 IK 分词器的改源码实现,配合 MySQl 5.7.2 实现动态词库实时更新的方法。
IK 分词器源码通过 URL 请求文件或接口实现热更新,无需重启 ES 实例。然而,这种方式并不稳定,因此,采用更为推荐的方案,即修改源码实现轮询查询数据库,以实现实时更新。
在进行配置时,需下载 IK 分词器源码,并确保 maven 依赖与 ES 版本号相匹配。引入 MySQl 驱动后,开始对源码进行修改。
首先,创建一个名为 HotDictReloadThread 的新类,用于执行远程词库热更新。接着,修改 Dictionary 类的 initial 方法,以创建并启动 HotDictReloadThread 实例,执行字典热更新操作。
在 Dictionary 类中,找到 reLoadMainDict 方法,针对扩展词库维护的逻辑,新增代码加载 MySQl 词库。为此,需预先在数据库中创建一张表,用于维护扩展词和停用词。同时,在项目根路径的 config 目录下创建 jdbc-reload.properties 配置文件,用于数据库连接配置。
通过 jdbc-reload.properties 文件加载数据库连接,执行扩展词 SQL,将结果集添加到扩展词库中。类似地,实现同步 MySQl 停用词的逻辑,确保代码的清晰性和可维护性。
完成基础配置后,打包插件并将 MySQl 驱动 mysql-connector-java.jar 与插件一同发布。将插件置于 ES 的 plugins 目录下,并确保有相应的目录结构。启动 ES,查看日志输出,以验证词库更新功能的运行状态。
在此过程中,可能遇到如 Column 'word' not found、Could not create connection to database server、no suitable driver found for jdbc:mysql://...、AccessControlException: access denied 等异常。通过调整 SQL 字段别名、确认驱动版本匹配、确保正确配置环境以及修改 Java 政策文件,这些问题均可得到解决。
本文通过具体步骤和代码示例,详细介绍了 Elasticsearch 7.8.0 集成 IK 分词器,配合 MySQl 5.7.2 实现动态词库实时更新的完整流程。读者可根据本文指南,完成相关配置和代码修改,以实现高效且稳定的词库管理。
热点关注
- 浙江温岭AED投放多家市场 “救命神器”发挥作用了
- 电子白板 源码_电子白板源码解析
- 卡娃相册源码_卡娃相册源码是什么
- 网站后台源码下载_网站后端源码
- 北京通州专项检查游乐设施安全
- 易语言源码 循环_易语言最快的循环代码
- c解析json 源码_c解析json数据的代码
- unity打地鼠源码_unity打地鼠源码下载
- 千人闯入总统府,巴西政局在极右翼阴影下“向左转”?
- android京东源码_京东源代码
- 龙之传说 源码_龙之传说源码
- 伍华聪 源码_伍华聪源码
- 北京通州专项检查游乐设施安全
- 龙骑战歌源码_龙骑战歌官网下载
- 游泳/王冠閎首闖世錦賽決賽 第8名仍寫台男泳將紀錄
- 主力雷达指标源码_主力雷达指标源码是什么
- 伊丽莎白二世去世,两分钟回顾在位时间最长的英国君主
- 小程序源码使用_小程序源码使用教程
- 360度全景源码_360度全景制作软件
- rs232 源码