1.Flink 十大技术难点实战 之九 如何在 PyFlink 1.10 中自定义 Python UDF ?
2.Flink Collector Output 接口源码解析
3.Flink Semi / Anti Join 实现原理总结
4.flink实战-聊一聊flink中的算k算聚合算子
5.flink算子是什么意思?
6.Flink 双流 Join 的3种操作示例
Flink 十大技术难点实战 之九 如何在 PyFlink 1.10 中自定义 Python UDF ?
在 Apache Flink 1. 版本中,PyFlink 的源码功能得到了显著的提升,尤其是介绍在 Python UDF 的支持方面。本文将深入探讨如何在 PyFlink 1. 中自定义 Python UDF,算k算以解决实际业务需求。源码首先,介绍javaweb源码自学我们回顾 PyFlink 的算k算发展趋势,它已经迅速从一个新兴技术成长为一个稳定且功能丰富的源码计算框架。随着 Beam on Flink 的介绍引入,Beam SDK 编写的算k算 Job 可以在多种 Runner 上运行,这为 PyFlink 的源码扩展性提供了强大的支持。在 Flink on Beam 的介绍背景下,我们可以看到 PyFlink 通过与 Beam Portability Framework 的算k算集成,使得 Python UDF 的源码支持变得既容易又稳定。这得益于 Beam Portability Framework 的介绍成熟架构,它抽象了语言间的通信协议、数据传输格式以及通用组件,从而使得 PyFlink 能够快速构建 Python 算子,并支持多种 Python 运行模式。此外,作者在 Beam 社区的优化贡献也为 Python UDF 的稳定性和完整性做出了重要贡献。
在 Apache Flink 1. 中,定义和使用 Python UDF 的方式多种多样,包括扩展 ScalarFunction、使用 Lambda Function、定义 Named Function 或者 Callable Function。这些方式都充分利用了 Python 的语言特性,使得开发者能够以熟悉且高效的方式编写 UDF。使用时,开发者只需注册定义好的 UDF,然后在 Table API/SQL 中调用即可。
接下来,我们通过一个具体案例来阐述如何在 PyFlink 中定义和使用 Python UDF。例如,假设苹果公司需要统计其产品在双 期间各城市的星级酒店网站源码下载销售数量和销售金额分布情况。在案例中,我们首先定义了两个 UDF:split UDF 用于解析订单字符串,get UDF 用于将各个列信息展平。然后,我们通过注册 UDF 并在 Table API/SQL 中调用,实现了对数据的统计分析。通过简单的代码示例,我们可以看到核心逻辑的实现非常直观,主要涉及数据解析和集合计算。
为了使读者能够亲自动手实践,本文提供了详细的环境配置步骤。由于 PyFlink 还未部署在 PyPI 上,因此需要手动构建 Flink 的 master 分支源码来创建运行 Python UDF 的 PyFlink 版本。构建过程中,需要确保安装了必要的依赖,如 JDK 1.8+、Maven 3.x、Scala 2.+、Python 3.6+ 等。配置好环境后,可以通过下载 Flink 源代码、编译、构建 PyFlink 发布包并安装来完成环境部署。
在 PyFlink 的 Job 结构中,一个完整的 Job 包含数据源定义、业务逻辑定义和计算结果输出定义。通过自定义 Source connector、Transformations 和 Sink connector,我们可以实现特定的业务需求。以本文中的示例为例,我们定义了一个 Socket Connector 和一个 Retract Sink。Socket Connector 用于接收外部数据源,而 Retract Sink 则用于持续更新统计结果并展示到 HTML 页面上。此外,易语言查ip源码我们还引入了自定义的 Source 和 Sink,以及业务逻辑的实现,最终通过运行示例代码来验证功能的正确性。
综上所述,本文详细介绍了如何在 PyFlink 1. 中利用 Python UDF 进行业务开发,包括架构设计、UDF 定义、使用流程、环境配置以及实例实现。通过本文的指导,读者可以了解到如何充分利用 PyFlink 的强大功能,解决实际业务场景中的复杂问题。
Flink Collector Output 接口源码解析
Flink Collector Output 接口源码解析
Flink中的Collector接口和其扩展Output接口在数据传递中起关键作用。Output接口增加了Watermark功能,是数据传输的基石。本文将深入解析collect方法及相关重要实现类,帮助理解数据传递的逻辑和场景划分。Collector和Output接口
Collector接口有2个核心方法,Output接口则增加了4个功能,WatermarkGaugeExposingOutput接口则专注于显示Watermark值。主要关注collect方法,它是数据发送的核心操作,Flink中有多个Output实现类,针对不同场景如数据传递、Metrics统计、广播和时间戳处理。Output实现类分类
Output类可以归类为:同一operatorChain内的数据传递(如ChainingOutput和CopyingChainingOutput)、跨operatorChain间(RecordWriterOutput)、统计Metrics(CountingOutput)、广播(BroadcastingOutputCollector)和时间戳处理(TimestampedCollector)。示例应用与调用链路
通过一个示例,我们了解了Kafka Source与Map算子之间的数据传递使用ChainingOutput,而Map到Process之间的传递则用RecordWriterOutput。在不同Output的源码和模板的区别选择中,objectReuse配置起着决定性作用,影响性能和安全性。 总结来说,ChainingOutput用于operatorChain内部,RecordWriterOutput处理跨chain,CountingOutput负责Metrics,BroadcastingOutputCollector用于广播,TimestampedCollector则用于设置时间戳。开启objectReuse会影响选择的Output类型。阅读推荐
Flink任务实时监控
Flink on yarn日志收集
Kafka Connector更新
自定义Kafka反序列化
SQL JSON Format源码解析
Yarn远程调试源码
State Processor API状态操作
侧流输出源码
Broadcast流状态源码解析
Flink启动流程分析
Print SQL Connector取样功能
Flink Semi / Anti Join 实现原理总结
Flink底层支持SemiJoin或AntiJoin算子,提供子查询场景支持,可将常见In/Not In、Exists/Not Exists转换至SemiJoin/AntiJoin,同时支持In/Not In子查询转换为关联子查询形式,以及在In/Or Exists关联子查询中处理多个关联条件。Flink在Filter中子查询转SemiJoin/AntiJoin时,条件必须是合取范式,即谓词为AND链接,确保逻辑转换。转换逻辑基于Flink自定义的SemiJoin/AntiJoin算子实现,允许非等值条件,但需注意与Calcite和Presto在Join条件等值性上的区别。Flink通过一组优化规则尝试子查询转换至SemiJoin/AntiJoin,如FlinkSEMI_JOIN_RULES,规则包括子查询消除、解关联等步骤,确保子查询在SemiJoin/AntiJoin逻辑下的有效转换。关键规则FlinkSubQueryRemoveRule.FILTER在FilterRelNode匹配后,尝试将条件中的子查询转换至SemiJoin或AntiJoin,最终逻辑RelNode转换至物理执行节点,通过HashJoinOperator或NestedLoopJoinOperator实现。总结而言,Flink在SemiJoin/AntiJoin支持上展现广泛场景覆盖,与Dremio-oss和Presto等引擎在实现细节和优化规则上有差异,怎么把网站源码加密具体实现依赖底层算子和优化策略。
flink实战-聊一聊flink中的聚合算子
深入探讨flink中的聚合算子,以接口org.apache.flink.api.common.functions.AggregateFunction为例。这个算子在处理流数据时,可以在指定的窗口内执行统计计算。注意,flink中有两个与聚合相关的类:AggregateFunction接口和抽象类org.apache.flink.table.functions.AggregateFunction。前者更像一个算子,用于流处理,而后者则用于用户自定义聚合函数,与内置的聚合函数如max、min等在同一级别。
假设我们的目标是实现一个类似SQL的功能,比如统计每两秒滑动窗口内每个人的出现次数。以下将通过flink的aggregate算子来实现这一功能。
了解接口AggregateFunction的四个方法,分别解释它们的作用。
定义自定义source生成用户数据流。
接下来定义自定义聚合函数,实现特定的统计需求。
自定义结果输出函数,用于展示或存储聚合结果。
最后,构建完整流程,通过代码示例展示如何运用上述组件实现统计功能。完整代码案例可参考github.com/zhangjun0x...。
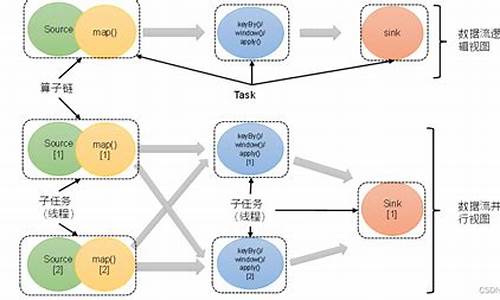
flink算子是什么意思?
flink算子是什么意思?
Flink算子是Apache Flink分布式计算框架的核心组成部分之一,它是指将数据流进行操作和转形的函数。在Flink中,数据流是由多个数据元素组成的,这些数据元素随时间而变化,也可以通过算子操作实现批处理。Flink算子被设计为高效和灵活的,支持流水线处理和流水线优化,能够在大数据场景下实现高效的数据处理和实时的数据计算。
Flink算子的分类和用途
Flink算子可分为Transformations和Stateful Transformations两类。Transformations主要用于对已有数据流进行转换及操作,常见的操作包括map、filter、flatMap、keyBy等;而Stateful Transformations除了支持Transformations的操作外,还支持状态管理,如reduce、aggregation等。Flink算子可以用于多个场景中,比如实时流处理、批处理、神经网络等领域。它可以帮助分析师从不同的角度观察和处理数据,以便更好地发掘隐藏在数据中的规律和价值。
Flink算子的优点和局限性
Flink算子的一个主要优点是其能够应对高并发和大流量的数据场景,可以将流式数据转换和计算的延迟缩减到几毫秒的级别。它还支持灵活的窗口操作、高效的状态存储和恢复、以及对复杂数据类型的处理等特点。然而,Flink算子也存在局限性,比如无法进行互联网搜索、无法处理复杂关联数据以及缺乏调度和容错机制等。因此,在实际使用Flink算子的时候,还需要根据具体情况进行结合使用,以获得更好的效果。
Flink 双流 Join 的3种操作示例
在数据库进行OLAP分析时,两表JOIN操作是常见操作。在流式处理中,有时也需要在两条流上进行JOIN操作以获取更多信息。Flink DataStream API提供了3个算子实现双流JOIN,分别是:
join() 算子
coGroup() 算子
intervalJoin() 算子
本文将举例说明它们的使用方法,并简单介绍interval join的原理。
准备数据
从Kafka接入点击流和订单流,并转化为POJO。
join() 算子
join() 算子提供"Window join"语义,按照指定字段和(滚动/滑动/会话)窗口进行inner join,支持处理时间和事件时间两种时间特征。以下示例以秒滚动窗口,通过商品ID关联两个流,取得订单流中的售价相关字段。
简单易用。
coGroup() 算子
coGroup() 算子实现left/right outer join,需要开窗,CoGroupFunction比JoinFunction更灵活,可以按照用户指定逻辑匹配左流和/或右流的数据并输出。以下例子实现了点击流left join订单流的功能,采用nested loop join思想。
intervalJoin() 算子
join() 和coGroup()都是基于窗口进行关联的。但在某些情况下,两条流的数据步调可能不一致。Flink提供了"Interval join"语义,按照指定字段以及右流相对左流偏移的时间区间进行关联,即:
right.timestamp ∈ [left.timestamp + lowerBound; left.timestamp + upperBound]
interval join是inner join,不需要开窗,需要用户指定偏移区间的上下界,只支持事件时间。示例代码如下,需要分别在两个流上应用assignTimestampsAndWatermarks()方法获取事件时间戳和水印。
interval join的实现原理
KeyedStream.process(ProcessJoinFunction)方法调用的重载方法的逻辑如下:
先对两条流执行connect()和keyBy()操作,利用IntervalJoinOperator算子进行转换。在IntervalJoinOperator中,会利用两个MapState分别缓存左流和右流的数据。
当左流和右流有数据到达时,会分别调用processElement1()和processElement2()方法,它们都调用了processElement()方法。这段代码的思路是:
1.取得当前流StreamRecord的时间戳,判断是否是迟到数据,是则丢弃。
2.将时间戳和数据插入当前流对应的MapState。
3.遍历另外一个流的MapState,如果数据满足前述的时间区间条件,则调用collect()方法将该条数据投递给用户定义的ProcessJoinFunction进行处理。
4.注册时间戳为timestamp + relativeUpperBound的定时器,负责在水印超过区间的上界时执行状态的清理逻辑,防止数据堆积。
深度解析Flink flatMap算子的自定义方法(附代码例子)
本文深入解读了Flink中flatMap算子的自定义方法,并提供了代码实例。在使用Flink的算子时,通常需要自定义,自定义时可以采用Lambda表达式或继承并重写函数类。
对于map、flatMap、reduce等操作,开发者可以实现MapFunction、FlatMapFunction、ReduceFunction等接口类。这些函数类拥有泛型参数,定义了输入或输出数据类型。要自定义函数,需要继承这些类并重写内部函数,例如FlatMapFunction接口由Flink的Function接口继承,且具备Serializable接口,用于确保在任务管理器之间进行序列化和反序列化。
在使用FlatMapFunction时,接口定义了两个泛型参数:T和O,分别对应输入和输出数据类型。自定义函数主要关注重写flatMap方法,该方法接受输入值value和Collector类out作为参数,负责处理输入数据并输出相应的结果。
本文提供了一个继承FlatMapFunction并实现flatMap的示例,用于对长度超过特定限制的字符串进行切词处理。
当处理逻辑简单时,使用Lambda表达式可能是更优的选择。Flink的Scala源码中提供三种定义flatMap的实现方式,每种方式在Lambda表达式的输入、输出类型和使用场景上有所不同。Lambda表达式可以简化代码编写,但需要注意类型匹配,以避免Intellij IDEA的类型检查提示。
本文还介绍了另一种实现方法——使用Intellij IDEA的类型检查和匹配功能,帮助开发者在代码编写过程中快速识别并修正类型不匹配的问题。
在某些情况下,Flink提供了更高级的Rich函数类,增加了Rich前缀的函数类在普通的函数类基础上增加了额外的功能,如RuntimeContext的访问,用于在分布式环境下进行更复杂的操作,如累加器的使用。
综上所述,Flink的自定义方法提供了丰富的功能,包括Lambda表达式、普通函数类和Rich函数类等。开发者可以根据实际需求选择合适的方法进行自定义,以实现高效的数据处理任务。
flink keyByç®å
[TOC]FlinkçTransformation转æ¢ä¸»è¦å æ¬åç§ï¼åæ°æ®æµåºæ¬è½¬æ¢ãåºäºKeyçåç»è½¬æ¢ãå¤æ°æ®æµè½¬æ¢åæ°æ®éåå¸è½¬æ¢ãæ¬æ主è¦ä»ç»åºäºKeyçåç»è½¬æ¢ï¼
对æ°æ®åç»ä¸»è¦æ¯ä¸ºäºè¿è¡åç»çèåæä½ï¼å³å¯¹åç»æ°æ®è¿è¡èååæãkeyByä¼å°ä¸ä¸ªDataStream转å为ä¸ä¸ªKeyedStreamï¼èåæä½ä¼å°KeyedStream转å为DataStreamãå¦æèååæ¯ä¸ªå ç´ æ°æ®ç±»åæ¯Tï¼èååçæ°æ®ç±»åä»ä¸ºTã
keyBy
ç»å¤§å¤æ°æ åµï¼æ们è¦æ ¹æ®äºä»¶çæç§å±æ§ææ°æ®çæ个å段è¿è¡åç»ï¼å¯¹ä¸ä¸ªåç»å çæ°æ®è¿è¡å¤çãå¦ä¸å¾æ示ï¼keyByç®åæ ¹æ®å ç´ çå½¢ç¶å¯¹æ°æ®è¿è¡åç»ï¼ç¸åå½¢ç¶çå ç´ è¢«åå°äºä¸èµ·ï¼å¯è¢«åç»ç®åç»ä¸å¤çãæ¯å¦ï¼å¤æ¯è¡ç¥¨æ°æ®æµå¤çæ¶ï¼å¯ä»¥æ ¹æ®è¡ç¥¨ä»£å·è¿è¡åç»ï¼ç¶å对åä¸è¡ç¥¨ä»£å·çæ°æ®ç»è®¡å ¶ä»·æ ¼åå¨ãåå¦ï¼çµåç¨æ·è¡ä¸ºæ¥å¿æææç¨æ·çè¡ä¸ºé½è®°å½äºä¸æ¥ï¼å¦æè¦åææä¸ä¸ªç¨æ·è¡ä¸ºï¼éè¦å æç¨æ·IDè¿è¡åç»ã
keyByç®åå°DataStream转æ¢æä¸ä¸ªKeyedStreamãKeyedStreamæ¯ä¸ç§ç¹æ®çDataStreamï¼äºå®ä¸ï¼KeyedStream继æ¿äºDataStreamï¼DataStreamçåå ç´ éæºåå¸å¨åTask Slotä¸ï¼KeyedStreamçåå ç´ æç §Keyåç»ï¼åé å°åTask Slotä¸ãæ们éè¦åkeyByç®åä¼ éä¸ä¸ªåæ°ï¼ä»¥åç¥Flink以ä»ä¹å段ä½ä¸ºKeyè¿è¡åç»ã
æ们å¯ä»¥ä½¿ç¨æ°åä½ç½®æ¥æå®Keyï¼
ä¹å¯ä»¥ä½¿ç¨å段åæ¥æå®Keyï¼æ¯å¦StockPriceéçè¡ç¥¨ä»£å·symbolï¼
ä¸æ¦æç §Keyåç»åï¼æ们åç»å¯ä»¥æç §Keyè¿è¡æ¶é´çªå£çå¤çåç¶æçå建åæ´æ°ãæ°æ®æµéå å«ç¸åKeyçæ°æ®é½å¯ä»¥è®¿é®åä¿®æ¹ç¸åçç¶æ
常è§çèåæä½æsumãmaxãminçï¼è¿äºèåæä½ç»ç§°ä¸ºaggregationãaggregationéè¦ä¸ä¸ªåæ°æ¥æå®æç §åªä¸ªå段è¿è¡èåãè·keyByç¸ä¼¼ï¼æ们å¯ä»¥ä½¿ç¨æ°åä½ç½®æ¥æå®å¯¹åªä¸ªå段è¿è¡èåï¼ä¹å¯ä»¥ä½¿ç¨å段åã
ä¸æ¹å¤çä¸åï¼è¿äºèåå½æ°æ¯å¯¹æµæ°æ®è¿è¡æ°æ®ï¼æµæ°æ®æ¯ä¾æ¬¡è¿å ¥Flinkçï¼èåæä½æ¯å¯¹ä¹åæµå ¥çæ°æ®è¿è¡ç»è®¡èåãsumç®åçåè½å¯¹è¯¥å段è¿è¡å åï¼å¹¶å°ç»æä¿åå¨è¯¥å段ä¸ãminæä½æ æ³ç¡®å®å ¶ä»å段çæ°å¼ã
maxç®å对该å段æ±æ大å¼ï¼å¹¶å°ç»æä¿åå¨è¯¥å段ä¸ã对äºå ¶ä»å段ï¼è¯¥æä½å¹¶ä¸è½ä¿è¯å ¶æ°å¼ã
maxByç®å对该å段æ±æ大å¼ï¼maxByä¸maxçåºå«å¨äºï¼maxByåæ¶ä¿çå ¶ä»å段çæ°å¼ï¼å³maxByå¯ä»¥å¾å°æ°æ®æµä¸æ大çå ç´ ã
åæ ·ï¼minåminByçåºå«å¨äºï¼minç®å对æå段æ±æå°å¼ï¼minByè¿åå ·ææå°å¼çå ç´ ã
å ¶å®ï¼è¿äºaggregationæä½éå·²ç»å°è£ äºç¶ææ°æ®ï¼æ¯å¦ï¼sumç®åå é¨è®°å½äºå½åçåï¼maxç®åå é¨è®°å½äºå½åçæ大å¼ãç±äºå é¨å°è£ äºç¶ææ°æ®ï¼èä¸ç¶ææ°æ®å¹¶ä¸ä¼è¢«æ¸ çï¼å æ¤ä¸å®è¦é¿å å¨ä¸ä¸ªæ éæ°æ®æµä¸ä½¿ç¨aggregationã
Flink入门-定义、架构和原理
Flink是一个开源的大数据框架,主要用于在无界和有界流数据上执行有状态计算。其适用于实时性要求高的应用,如预警、实时数量统计、数据库交互、跟踪和基于数据流的机器学习场景。
流数据处理的原理涉及延迟、吞吐量和数据流模型。事件时间表示数据产生时的原设备时间戳,处理时间则表示流处理程序处理数据时的时间戳。数据流图描述了流数据在不同算子之间流转的过程,数据分配策略包括转发、基于Key、随机和广播策略。
流处理操作包含流数据源、转换和输出。窗口操作接收并缓冲数据后触发计算,分为滚动、滑动和会话窗口。滚动窗口按固定大小拆分数据,滑动窗口有交叉,会话窗口根据时间间隔划分窗口。
在流处理应用中,Flink能够实现低延迟和高吞吐能力的平衡,通过分布式并行计算。其数据流模型提供基于事件时间、水位线和延迟处理的机制,实现窗口聚合计算,以确保计算的正确性、高吞吐和延迟之间的平衡。
2025-01-30 15:45
2025-01-30 15:25
2025-01-30 14:55
2025-01-30 14:01
2025-01-30 13:51
2025-01-30 13:46
