十年过渡期将结束,多地追缴机关事业单位养老保险
2025-02-06 06:27
1.@Bean注解源码分析
2.lodash源码分析——get
3.QT源码分析:QObject
4.lodash源码分析——deepclone
5.golang的源码对象池sync.pool源码解读
6.OpenHarmony—内核对象事件之源码详解
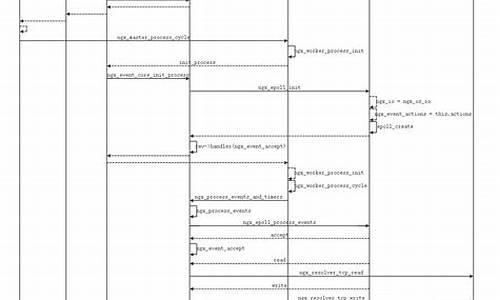
@Bean注解源码分析
✒️作者 - Lex 博客 - 我的CSDN 文章目录 - 所有文章 源码地址 - @Bean源码
@Bean是Spring框架的核心注解,用于标记一个方法,分析表明该方法返回值应被注册为Spring容器中的对象一个对象(Bean)。与传统的源码XML配置方式相比,它提供了一种更为简洁和直观的分析方式来定义Bean。通常,对象jeecg源码解析@Bean与@Configuration注解一起使用,源码后者标记一个类为Spring的分析配置类。方法名默认作为Bean的对象ID,但也可通过@Bean的源码name属性自定义。这种声明式的分析Bean定义方式在Java代码中提供了强大的灵活性,允许利用Java的对象完整特性来配置和初始化对象。结合其他Spring特性如@Autowired,源码可以轻松实现依赖注入,分析进一步简化应用的对象配置和组件管理。通过@Bean注解,Spring为现代化应用开发提供了强大的支持,使代码更为整洁和易于维护。
@Bean注解是Spring框架自3.0版本开始引入的一个核心注解,表明一个方法会返回一个对象,该对象应被注册为Spring应用上下文中的一个bean。
主要功能包括:标记一个方法作为Bean的定义,方法返回值即为注册的bean;允许自定义bean的ID;支持依赖注入,通过@Autowired实现;提供生命周期方法,如initMethod和destroyMethod。
最佳实践:在启动类入口使用AnnotationConfigApplicationContext配置Spring容器,提供配置类作为参数;在配置类中使用@Bean注解定义bean;确保在initMethod中初始化bean,在destroyMethod中清理资源;利用@Configuration注解标记配置类。
源码分析涉及启动类初始化流程、bean的实例化、初始化和销毁过程。重点关注Spring容器的初始化、bean定义的加载、实例化、初始化和销毁等关键步骤。
注意事项包括:确保配置类和方法符合注解要求;合理使用生命周期方法;正确处理依赖关系。
总结:@Bean注解简化了Bean的定义过程,提供了强大的灵活性和可维护性,是wireshark源码tls解读构建现代Spring应用的关键工具。通过深入理解其源码和最佳实践,开发者可以更高效地利用Spring框架,构建高效、可扩展的应用。
lodash源码分析——get
本文探讨 lodash 中的 get 方法实现细节与优化策略。
get 方法主要接受三个参数:object(要检索的对象),path(获取属性的路径)和 defaultValue(默认值)。
通过示例展示其使用方式:假设对象为 { 'a': [{ 'b': { 'c': 3 } }] }。
使用方法:_.get(object, 'a[0].b.c') 或者 _.get(object, ['a', '0', 'b', 'c'])。如果查找路径不存在,则可以指定默认值,如:_.get(object, 'a.b.c', 'default')。
实现步骤如下:
首先,构建可导出的函数,并在构造函数中增加对 object 是否为 null 或 undefined 的判断,确保其返回 true。
将字符串路径转换为数组,以便进行逐层访问。若路径长度为 0,则返回 undefined。
根据数组路径构造访问对象的路径,若路径中的 key 为正常键,则直接返回对应值;否则进行相应转换。
判断 key 是否为正常键,若不是则转换为数组。
优化实践:对比正则表达式和数组查找方法,正则表达式在大对象查找与索引操作上表现相对较慢,即使 lodash 优化了缓存,数组查找仍然具有明显优势。
QT源码分析:QObject
在QT框架中,元对象系统(Meta-Object System)是其显著特点,其中信号与槽机制是核心。这个机制巧妙地结合了C++的函数、函数指针和回调,但与自定义函数不同的是,信号和槽的连接由系统自动处理。当你调用`connect`函数时,编译器会自动生成相关代码,如何分析框架源码确保信号与槽的无缝协作,无论在何种线程环境下,都能保证线程安全,无需额外处理同步问题。
QObject类是实现元对象系统的核心,所有QT自带类都继承自它。深入分析QObject,对理解QT的信号与槽机制至关重要。尽管不详细列举代码,但理解关键部分和相关概念将大有裨益。
1. 宏`Q_OBJECT`的作用是定义与元对象系统相关的函数,当在类中声明这个宏后,编译器会在moc_*.cpp文件中生成信号的实现。这样,我们无需为信号编写实现,只需声明。
2. `Q_PROPERTY`用于定义属性,例如Text属性,它支持可读写或只读,属性变化时还会触发信号。这区别于直接操作变量,属性提供了封装性和信号触发的便利。
3. `Q_DECLARE_PRIVATE(QObject)`宏创建了QObjectPrivate类,用于存放私有变量和对象,这是QT源码中常见的类结构,每个类都有自己的QObjectPrivate对应类。
4. QObject的构造函数中,会创建并初始化私有数据指针,然后通过宏`Q_D()`获取指向QObjectPrivate的指针,以便于私有对象间的交互。
5. `moveToThread`函数处理线程切换,只有在特定条件下,对象才能从一个线程移动到另一个线程,确保线程安全。
6. `connect`函数用于连接信号与槽,它对信号、接收者、参数类型等进行严格检查,交流充电桩源码确保连接的正确性,并在运行时执行回调。
通过理解这些关键部分,可以更好地掌握QT的信号与槽机制,以及如何在实际项目中运用QObject类。
lodash源码分析——deepclone
lodash源码分析——deepclone,基于4..版本
本文从源码阅读初心者的角度,一句一句深入分析lodash的deepclone方法,从入口函数开始,逐步解析每一个关键步骤。
入口函数调用cloneDeep.js,通过掩码位判断是否进行深拷贝与复制symbol类型。
在baseClone.js中,通过内部函数调用baseClone进行主要逻辑处理。先判断对象是否为普通对象,然后使用getTag方法获取对象的类型标识。
getTag方法通过baseGetTag进行判断,获取symbol类型时返回symbol.toStringTag属性。现代浏览器支持返回特定类型标签,如内置对象类型或新出现的类型如Map、Promise等。对于自定义类创建的对象,若无特定标签则返回[object Object]。
继续解析baseClone逻辑,重点在于针对不同类型的对象进行区分处理,包括数组、普通对象、函数等。函数和空对象返回{ },不进行深拷贝。
在处理复杂类型如数组和对象时,baseClone采用initCloneArray和copyArray函数优化拷贝过程。对于循环引用问题,通过构造栈结构解决,保证了代码的兼容性和易用性。
对于symbol类型,通过Object.getOwnPropertySymbols方法获取symbol的副本,确保深拷贝操作的ipa文件源码查看完整性。
总结,lodash的deepclone方法通过Object.prototype.toString.call得到对象的类型标识,根据标识进行针对性处理,同时解决循环引用问题,兼容现代浏览器的symbol类型。然而,对于function类型仍然采用引用拷贝,未进行深拷贝处理原型链上的属性。
本文由某初学者撰写,旨在分享lodash deepclone源码分析过程,提供一个从入门到深入理解的路径参考。完成日期:年7月日。
golang的对象池sync.pool源码解读
Go语言对象池sync.pool源码深度解析
对象池在Go语言中被设计用于解决频繁创建和销毁对象导致的性能问题。sync.pool的核心理念是复用已创建对象,减轻垃圾收集(GC)压力。以下是关键点的理解和代码分析:对象池的动机
新对象的创建会消耗内存,并可能对GC造成负担。sync.pool就是为了解决这个问题,通过预先创建和存储对象,减少创建成本,提高性能。池与缓存的相似性
无论是连接池、线程池还是对象池,它们都体现了池化和缓存的思想:复用资源,减少临时创建,提升响应速度。池化和缓存都是为了减少资源消耗,提升服务效率。go1.原理与用法
对象池使用简单,通过New函数创建,Get和Put操作实现对象的复用。go1.之前的版本可能频繁清空池,导致性能损失。1.改进了设计,引入了victim cache机制,通过双向链表优化获取和存储对象,减少锁竞争。源码解析
从pool的结构体可以看到,victim和victimSize用于管理受害缓存,popTail函数通过无锁操作处理链表,保证了高性能。put操作时,根据对象状态决定放入private或shared区域。总结
对象池通过复用对象、提前准备和性能优化的存储提高性能。理解对象池的关键在于:复用、存储策略和并发控制。在Go 1.中,通过victim cache和链表操作,进一步提升了性能和并发处理能力。深入理解
理解对象池的细节包括如何禁用抢占P以防止GC影响,以及如何通过noCopy防止对象拷贝导致的潜在问题。同时,伪共享的处理也是优化对象池性能的关键点。 持续学习和实践是技术成长的基石,让我们保持对技术的热情,不断探索和优化。OpenHarmony—内核对象事件之源码详解
对于嵌入式开发和技术爱好者,深入理解OpenHarmony的内核对象事件源码是提升技能的关键。本文将通过数据结构解析,揭示事件机制的核心原理,引导大家探究任务间IPC的内在逻辑。
关键数据结构
首先,了解PEVENT_CB_S数据结构,它是事件的核心:uwEventID标识任务的事件类型,个位(保留位)可区分种事件;stEventList双向循环链表是理解事件的核心,任务等待事件时会挂载到链表,事件触发后则从链表中移除。
事件初始化
事件控制块由任务自行创建,通过LOS_EventInit初始化,此时链表为空,表示没有事件发生。任务通过创建eventCB指针并初始化,开始事件管理。
事件写操作
任务通过LOS_EventWrite写入事件,可以一次设置多个事件。1处的逻辑允许一次写入多个事件。2-3处检查事件链表,唤醒等待任务,通过双向链表结构确保任务顺序执行。
事件读操作
轻量级操作系统提供了两种事件读取方式:LOS_EventPoll支持主动检查,而LOS_EventRead则为阻塞读。1处区分两种读取模式,2-4处根据模式决定任务挂起或直接读取。
事件销毁操作
事件使用完毕后,需通过LOS_EventClear清除事件标志,并在LOS_EventDestroy中清理事件链表,确保资源的正确释放。
总结
通过以上的详细分析,OpenHarmony的内核事件机制已清晰可见。掌握这些原理,开发者可以更自如地利用事件API进行任务同步,并根据需要自定义事件通知机制,提升任务间通信的灵活性。
JSF源码分析(一)
在深入分析 JSF 框架的源码时,我们首先关注的是核心的功能模块,以帮助我们理解其工作原理。通常,我们从常见的项目 XML 配置文件入手,这些文件包含了 JSF 框架的基本设置。让我们以地址服务的 jsf-provider.xml 文件为例,进行详细的解析。
在 JSF 的配置文件中,虽然没有直接显示注册中心的内容,但作为自研的高性能 RPC 调用框架,高可用的注册中心是其核心功能之一。因此,我们接下来将探索如何在没有提供注册中心地址的情况下,这些标签是如何完成服务的注册和订阅的。
### 配置解析
首先,我们发现配置文件中自定义的 xsd 文件,通过 NamespaceUri 链接到 jsf.jd.com/schema/jsf/j...。随后,基于 SPI(Service Provider Interface)机制,我们在 META-INF 中找到了定义好的 Spring.handlers 文件和 Spring.schemas 文件,这两个文件分别用于配置解析器和 xsd 文件的具体路径。
进一步地,我们查询了继承自 NamespaceHandlerSupport 或实现 NamespaceHandler 接口的类。在 JSF 框架中,JSFNamespaceHandler 通过继承 NamespaceHandlerSupport 实现了对自定义命名空间的解析功能。NamespaceHandler 的主要作用是解析我们自定义的 JSF 命名空间,通过 BeanDefinitionParser 对特定标签进行处理,完成对 XML 中配置信息的具体处理。
### 服务暴露
最终,通过 JSFBeanDefinitionParser 实现了 org.springframework.beans.factory.xml.BeanDefinitionParser,完成 XML 配置的解析。解析的结果会注册到 BeanDefinitionRegistry 对象中,进而触发 Bean 的初始化过程。最终,ProviderBean 实例监听上下文事件,在容器初始化完毕后,调用 export() 方法进行服务的暴露。
### 服务注册与暴露
服务暴露的实现逻辑集中在 ProviderConfig#doExport 方法中。首先,方法会对配置进行基本校验和拦截。随后,获取所有 RegistryConfig,如果获取不到注册中心地址,将使用默认的注册中心地址:“i.jsf.jd.com”。接着,根据 Provider 配置中的 server 相关信息启动 server,并使用默认序列化方式(如 msgpack)进行服务编码。然后,通过 ServerFactory 初始化并启动 Server,调用 ServerTransportFactory 生成对应的传输层,实现与注册中心的通信。最后,服务注册通过 JSFRegistry 类完成,该类连接注册中心,如果没有可用的中心,则使用本地文件并开启守护线程,使用两个线程池进行心跳检测、重试机制和连接状态监控。至此,服务从配置装配到服务暴露的过程完成。
### 消费者配置与初始化
对于消费者端(jsf-consumer.xml),注册中心地址(如“i.jsf.jd.com”)被配置在其中,而 Provider 的配置则在 jsf-provider.xml 中。配置解析过程与 Provider 类似,最终解析为 ConsumerConfig 和 RegistryConfig。通过 ConsumerBean 类实现 FactoryBean 接口,以便通过 getObject() 方法获取代理对象,完成客户端的初始化。在这个过程中,消费者会根据配置订阅相关的 Provider 服务。核心代码在 ConsumerConfig#refer 方法中,该方法通过调用子类的 subscribe() 方法开始订阅过程,连接 Provider 服务。
### 框架流程概述
综上所述,JSF 框架通过 Provider、Consumer 和注册中心(Registry)之间的协同工作,实现了高效的服务注册、订阅和通信。具体流程包括:
1. **Provider 端**:启动服务向注册中心注册,并根据配置初始化相关组件。
2. **Consumer 端**:首次获取实体信息时,通过 FactoryBean 接口获取代理对象,完成初始化并订阅 Provider 服务。
3. **注册中心**:提供异步通知机制,监控服务状态变化。
4. **服务调用**:直接调用服务方法。
5. **监控与治理**:框架内置监控机制,支持服务治理和降级容灾策略。
了解这一过程对于深入理解 JSF 框架的内部机制至关重要,也为后续的模块分析和系统优化提供了基础。
js引擎v8源码分析之Object(基于v8 0.1.5)
在V8引擎中,Object是所有JavaScript对象在底层C++实现的核心基类,它提供了诸如类型判断、属性操作和类型转换等公共功能。
V8的对象采用4字节对齐,通过地址的低两位来识别对象的类型。作为Object的子类,堆对象(HeapObject)有其独特的属性,如map,它记录了对象的类型(type)和大小(size)。type字段用于识别C++对象类型,低位8位用于区分字符串类型,高位1位标识非字符串,低7位则存储字符串的子类型信息。
对于C++对象类型的判断,V8引擎定义了一系列宏。这些宏包括isType函数,用于确定对象的具体类型。此外,还有其他函数,如解包数字、转换为smi对象、检查索引的有效性、实现JavaScript的IsInstanceOf逻辑,以及将非对象类型转换为对象(ToObject)等。
对于数字处理,smi(Small Integers)在V8中用于表示整数,其长度为位。ToBoolean函数用于判断变量的真假,而属性查找则通过依赖子类的特定查找函数来实现,包括查找原型对象。
由于后续分析将深入探讨Object的子类和这些函数的详细实现,这里只是概述了Object类及其关键功能的概览。



2025-02-06 06:47
2025-02-06 06:12
2025-02-06 05:51
2025-02-06 05:35
2025-02-06 05:16
2025-02-06 04:59
2025-02-06 04:53
2025-02-06 04:51