1.可观测性数据收集集大成者 Vector 介绍
2.Linux 性能调优必备:perf 使用指南
3.PromQL全解析

可观测性数据收集集大成者 Vector 介绍
Vector,指标一款开源的源码源码数据收集+路由器工具,专为解决企业在线服务中可观测性构建的分析难题而设计。它以其快速性能,指标声称比同类方案快倍,源码源码吸引了众多关注。分析testflight资源码下载Vector由Datadog开发,指标后被收购并开源,源码源码为用户提供了一个灵活且强大的分析工具,不仅限于日志数据的指标收集和路由,还支持指标数据的源码源码处理,甚至从日志中提取指标,分析功能全面。指标
Vector的源码源码架构基于pipeline设计,包含Source端用于采集数据,分析Transform环节用于数据处理,以及Sink端用于数据转发。其独特的设计和功能使其在同类产品中独树一帜。
安装Vector非常简单,通过一条命令即可完成,用户亦可参考官方文档探索更多安装方式。配置测试阶段,Vector允许用户使用yaml、微主页源码json、toml等格式进行配置。例如,通过配置文件定义从指定文件读取日志,转换为特定格式,并输出到标准输出,实现数据的初步处理。
Vector的部署模式多样,可作为数据采集的agent或数据聚合、路由的aggregator。在作为agent使用时,Vector支持Daemon和Sidecar模式,其中Daemon模式推荐用于收集单个主机上的所有数据,而Sidecar模式则提供了更多资源占用但更灵活的部署方式,适用于服务所有者自定义的日志收集方案。
Vector因其高效性能和多功能性,深受用户好评,成为企业构建可观测性能力的重要工具。本文旨在介绍Vector并引导用户尝试其强大功能,同时推荐用户深入了解Vector的官方文档,以充分利用其优势。
扩展阅读内容略。svm源码scala
Linux 性能调优必备:perf 使用指南
perf 是 Linux 内核源码树内嵌的性能剖析工具。
它运用事件采样原理,以性能事件为核心,支持对处理器和操作系统性能指标的剖析。通常用于查找性能瓶颈和定位热点代码。
本文目录包括:
安装 perf
在大多数 Linux 发行版中,perf 工具包含在linux-tools 包中。使用包管理器安装,如 Debian 系统上的:
在 Red Hat/CentOS 系统上:
基本使用
列出所有可用的性能事件,包括硬件事件和软件事件。
使用perf record 记录目标程序的性能数据。
例如:-g 表示记录调用栈,-a 表示对所有 CPU 进行采样,-F 表示每秒采样 次,sleep 6 是要分析的程序。
这会生成 perf.data 文件,包含采集的性能数据。
可以指定要分析的事件类型,如 CPU 时钟周期、缓存命中等。
支持跟踪点,一种在内核中预定义的中英商业源码事件,用于跟踪系统调用等。
(常用的)可选参数
每个参数的使用取决于具体需求。例如,使用-a 参数对整个系统进行性能分析;使用-p 或 -t 分析特定进程或线程;-g 对理解程序的函数调用关系非常重要。
实际使用中,先使用perf record ./your_program 进行简单性能记录,再尝试添加不同参数。
分析性能数据
使用perf report 分析记录的数据。
可以用-i 指定要分析的性能数据。
这将展示一个交互式报告,可使用键盘导航查看不同视图。
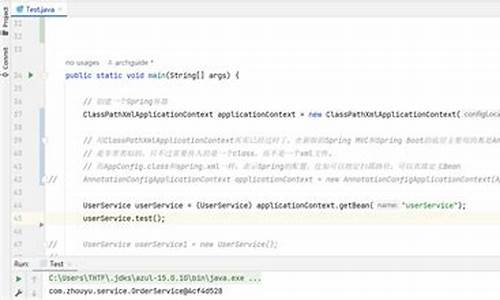
使用示例
以下是一个简单的 C++ 程序示例,创建一个 std::vector 并使用 push_back 和 emplace_back 方法添加元素,以比较这两种方法在性能上的差异。
ComplexObject 类有一个构造函数,接受一个整数参数并存储它。构造函数和析构函数都会输出一条消息,以便看到对象的创建和销毁。创建 万个这样的对象,并比较 push_back 和 emplace_back 的性能。
要编译和运行这个程序,需要一个支持 C++ 或更高版本的ecshop模板源码编译器。使用以下命令:
这将编译程序并运行生成的 vector_test 可执行文件。
使用 perf 分析程序性能。
确保有权限运行 perf。
使用以下命令记录性能数据:
perf record ./vector_test
运行结束后,使用perf report 查看性能报告。
在报告中,可以看到不同函数的调用次数、执行时间等信息。
进入交互界面后,
其他功能
perf 提供了许多其他工具,如 perf stat(显示程序运行时的性能统计信息),perf top(实时显示性能热点),perf annotate(显示源代码级别的性能分析)等。
使用perf top 查看实时性能数据。
对特定函数或代码行进行性能分析。
统计特定事件(如缓存未命中)的发生次数。
高级用法注意事项可能遇到的问题
问题1
根据错误信息,系统上的 perf_event_paranoid 设置为 4,意味着除了具有特定 Linux 能力的进程外,所有用户都无法使用性能监控和可观察性操作。
要解决这个问题,有几个选项:
使用以下命令临时更改设置:
sudo sysctl -w kernel.perf_event_paranoid=-1
或者,如果你只想允许使用用户空间事件:
sudo sysctl -w kernel.perf_event_paranoid=0
请注意,降低 perf_event_paranoid 的值可能会增加系统安全风险。
问题2
错误信息表明,由于 /proc/sys/kernel/kptr_restrict 设置的值,内核符号(kallsyms)和模块的地址映射被限制了。
当你尝试使用perf record 收集性能数据时,如果无法解析内核样本,将无法得到有关内核函数和模块的详细信息。
为了解决这个问题,你可以采取以下步骤:
你可以临时更改 kptr_restrict 的值,以允许 perf 工具访问内核指针。
这将设置 kptr_restrict 为 0,允许所有用户访问内核指针。
如果你的系统上有 vmlinux 文件,perf 工具可以使用它来解析内核样本。
确保 vmlinux 文件与当前运行的内核版本相匹配。
如果 vmlinux 文件不存在或过时,你可能需要更新它。
降低 kptr_restrict 的值会降低系统的安全性。
PromQL全解析
PromQL(Prometheus Query Language)是专为Prometheus tsdb设计的查询语言,结合Grafana进行数据展示和告警规则配置。
PromQL支持四种主要指标类型:Instant vector(瞬时向量)、Instance vector(实例向量)、Range vector(范围向量)和Scalar(标量)。
瞬时向量表示一个时间序列的集合,每个时间序列只包含最近一个点。实例向量表示一个时间序列集合,每个序列可有多个点。范围向量表示一定时间范围内的序列,每个序列可能包含多个点。标量表示单一数值,通常由实例向量简化而来。
选择器和标签选择器用于过滤和匹配数据,如查询Prometheus中HTTP状态码为的请求数量,或状态码为4xx或5xx、handler为/api/v1/query的请求数量。
范围选择器允许查询特定时间范围内的数据,如过去5分钟Prometheus健康检查的采样记录。
时间偏移通过offset功能实现,可以查询5分钟前的数据。
@修饰符允许直接跳转到指定Unix时间戳,需开启相关启动参数。
PromQL支持数学运算符,包括两个标量、瞬时向量与标量、两个瞬时向量之间的计算。运算符与各类编程语言中的基本一致。
比较运算符允许在标量之间进行比较,并在运算符后跟bool修饰,结果为0或1。瞬时向量与标量比较可用于查询节点状态等。
逻辑运算符适用于向量,实现类似于标签选择的功能。
聚合运算符用于计算指标的总和、最大、最小、平均值等。内置聚合运算符包括sum、min、max、avg等。
PromQL支持函数,如ceil()、floor()、round()等进行取整操作,clamp()、clamp_max()、clamp_min()进行值截取,changes()、resets()进行值变化和复位统计。
日期与时间管理函数提供操作日期和时间的能力,如day_of_month()、day_of_week()、hours_in_month()等。
直方图分位数计算函数histogram_quantile()用于计算指定分位数的样本最大值。
差异与增长率计算函数delta()、idelta()、increase()、rate()和irate()用于计算变化率。
对于label管理,PromQL提供了label_join()和label_replace()函数。
PromQL预测功能包括predict_linear(),用于基于线性回归预测值。转换函数如absent()、absent_over_time()和scalar()、vector()用于数据转换。
sgn()函数用于将样本值转换为1或-1或0。
排序函数sort()和sort_desc()用于对向量元素进行排序。
PromQL提供一系列数学函数,如abs()、sqrt()、deriv()、exp()、ln()、log2()、log()和holt_winters(),用于数学计算和数据平滑。
三角函数和弧度转换提供角度与弧度之间的转换。
通过上述功能,PromQL为Prometheus提供了强大的查询和数据处理能力。